

Akamai est l'entreprise de cybersécurité et de Cloud Computing qui soutient et protège l'activité en ligne. Nos solutions de sécurité leaders du marché, nos informations avancées sur les menaces et notre équipe opérationnelle internationale assurent une défense en profondeur pour protéger les données et les applications des entreprises du monde entier. Les solutions de Cloud Computing complètes d'Akamai offrent des performances de pointe à un coût abordable sur la plateforme la plus distribuée au monde. Les grandes entreprises du monde entier font confiance à Akamai pour bénéficier de la fiabilité, de l'évolutivité et de l'expertise de pointe nécessaires pour développer leur activité en toute sécurité.
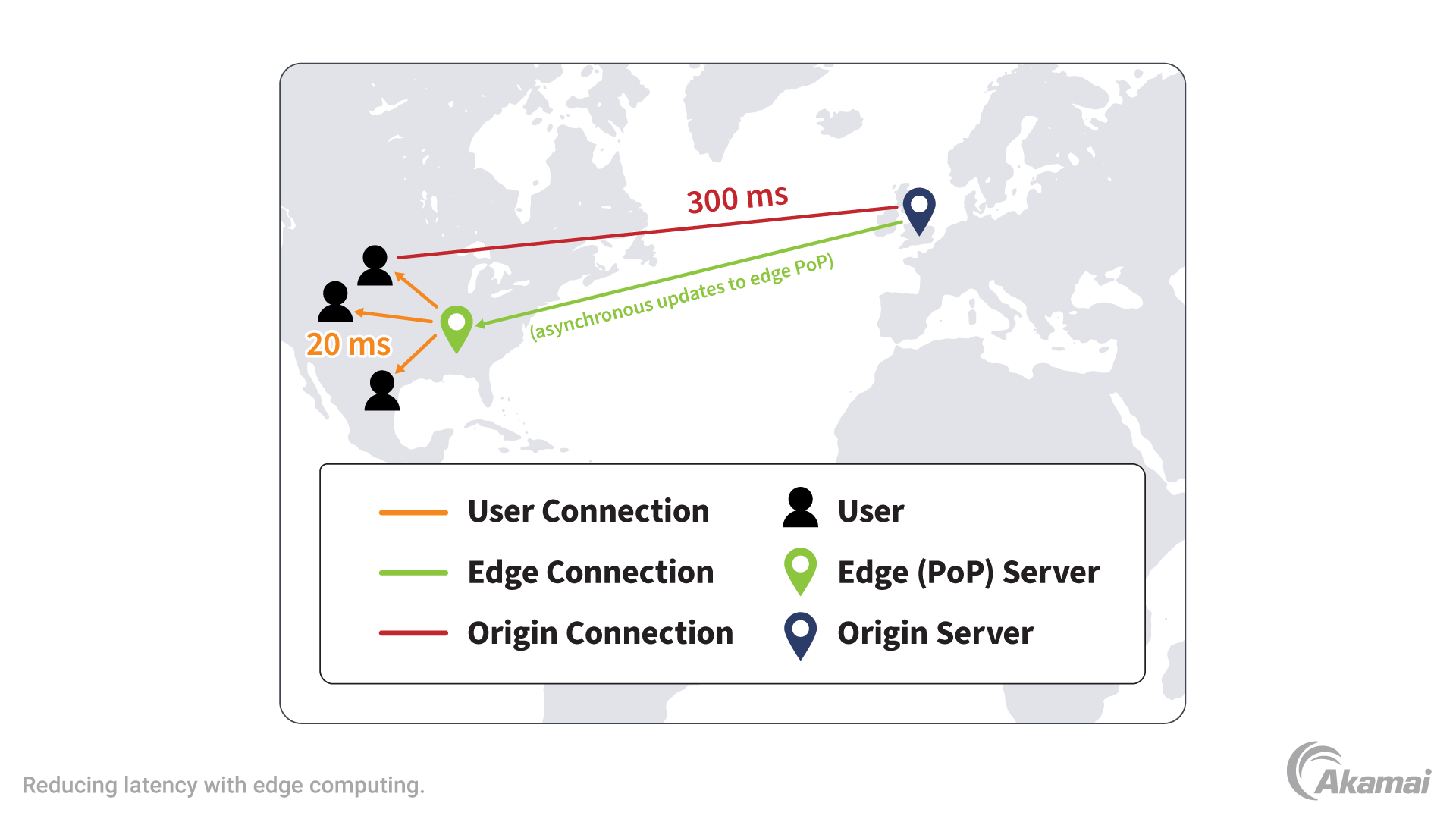
La périphérie du réseau est l'endroit où les mondes physique et digital interagissent, où les données sont saisies ou capturées par des terminaux connectés à Internet ou à un réseau, et où les terminaux reçoivent des données sur lesquelles les utilisateurs et les applications s'appuient pour prendre des décisions et obtenir des informations. L'Edge Computing rapproche les données, les informations et la prise de décision des utilisateurs et des terminaux, plutôt que de traiter les données dans un emplacement central qui peut être à des milliers de kilomètres de distance. En gérant le traitement à la périphérie du réseau, Le but est l'Edge Computing garantit que les données, notamment les données en temps réel, ne subissent pas de latence qui pourrait affecter l'objectif ou les performances d'une application.
L'Edge Computing est un modèle informatique dans lequel les fonctions de traitement et de stockage des données sont déplacées des centres de données centralisés vers des serveurs physiquement plus proches de la périphérie du réseau, où les utilisateurs et les terminaux accèdent aux données. En stockant et en traitant les données plus près des utilisateurs et des terminaux, l'Edge Computing permet d'améliorer la connectivité réseau, de réduire la latence, de réduire les coûts, de renforcer la sécurité et d'améliorer l'expérience utilisateur.
On peut considérer l'Edge Computing comme un cabinet médical avec son propre laboratoire. Plutôt que d'envoyer des échantillons à un centre de traitement central à des centaines de kilomètres, le cabinet médical dispose de l'équipement et de la bande passante nécessaires pour collecter, traiter et analyser vos échantillons sanguins immédiatement, ce qui vous permet d'obtenir des résultats plus rapidement et à moindre coût. Étant donné que les échantillons médicaux ne quittent pas le laboratoire, il y a peu de risque qu'ils soient perdus ou volés. Et en traitant vos analyses efficacement, le cabinet médical offre une expérience plus satisfaisante aux patients.
Pourquoi l'Edge Computing est-il important ?
La quantité de données que nous produisons et utilisons chaque année augmente de manière exponentielle. Des technologies telles que l'Internet des objets (IoT), l'intelligence artificielle (IA) et l'apprentissage automatique (ML) génèrent d'énormes quantités de données. Et comme des milliards de terminaux se connectent aux nouveaux réseaux 5G, cet océan virtuel de données ne fera que s'agrandir.
Dans les modèles informatiques traditionnels, les données d'une organisation sont acheminées via un centre de données centralisé, ce qui permet aux équipes informatiques et de sécurité de les gérer, de les inspecter et d'appliquer des politiques de sécurité. Cependant, à mesure que les volumes de données augmentent, l'envoi de tout ce trafic vers un centre de données entraîne inévitablement une latence et une congestion des réseaux. Par conséquent, les utilisateurs et les applications ne peuvent pas obtenir les données assez rapidement, et les expériences en ligne des utilisateurs deviennent lentes et frustrantes.
L'Edge Computing relève ce défi en traitant et en stockant les données à proximité de leur emplacement de génération et d'utilisation. En gardant les données, les charges de travail et les fonctions informatiques à proximité, l'Edge Computing permet aux données d'atteindre plus rapidement leurs objectifs pour améliorer les temps de réponse, les performances des applications et l'expérience utilisateur. Dans le même temps, l'Edge Computing réduit l'encombrement sur le réseau dans son ensemble.
Comment fonctionne l'Edge Computing ?
La périphérie du réseau est l'endroit où les mondes physique et digital interagissent, où les données sont saisies ou capturées par des terminaux connectés à Internet ou à un réseau, et où les terminaux reçoivent des données sur lesquelles les utilisateurs et les applications s'appuient pour prendre des décisions et obtenir des informations. L'Edge Computing rapproche les données, les informations et la prise de décision des utilisateurs et des terminaux, plutôt que de traiter les données dans un emplacement central qui peut être à des milliers de kilomètres de distance. En gérant le traitement à la périphérie du réseau, Le but est l'Edge Computing garantit que les données, notamment les données en temps réel, ne subissent pas de latence qui pourrait affecter l'objectif ou les performances d'une application.
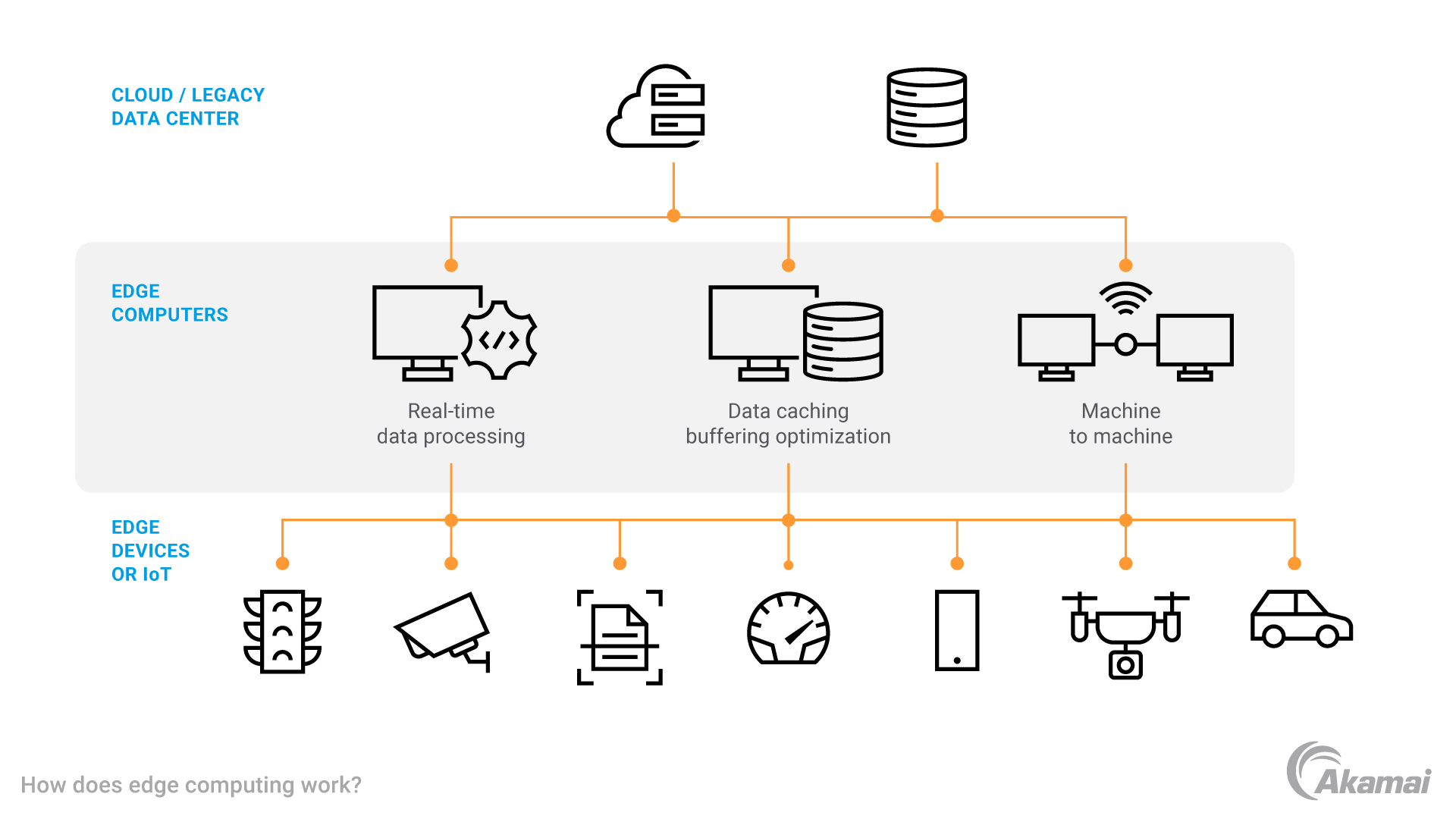
Pour créer un réseau à la périphérie, les équipes informatiques déploient des capacités de calcul dans des emplacements éloignés en installant des serveurs et des systèmes de stockage capables de traiter rapidement les données des terminaux à proximité. Les données peuvent également être traitées sur la mémoire et le stockage intégrés aux terminaux tels que les ordinateurs portables, les smartphones et les capteurs IoT. Plutôt que d'envoyer les données générées par les terminaux via un centre de données central ou vers le cloud, un réseau périphérique traite et stocke la plupart des données sur site ou sur des serveurs périphériques à proximité, et envoie uniquement les informations essentielles au cloud ou à un centre de données central.
Que sont les terminaux à la périphérie ?
Les terminaux à la périphérie sont des points de terminaison d'un réseau qui collectent, utilisent et fournissent des informations. Ils servent d'interface entre le monde réel et le centre de données ou le cloud. Les terminaux incluent les machines que nous utilisons tous les jours, comme les ordinateurs portables, les ordinateurs de bureau, les serveurs et les routeurs, ainsi que les terminaux et les passerelles qui font partie des réseaux IoT. Les autres types de terminaux à la périphérie incluent les terminaux médicaux, les instruments scientifiques, les scanners, les véhicules autonomes, les écrans intelligents, les terminaux de point de vente, les drones, les robots, les contrôleurs industriels et même les distributeurs automatiques.
Quels sont les exemples d'Edge Computing ?
L'Edge Computing est partout autour de nous et continue de croître et de se développer. Par exemple, il sert aux interactions quotidiennes auxquelles vous ne pensez même pas lorsque vous recevez une réponse instantanée. Cela peut aller de l'utilisation d'applications pour mobile, des achats en ligne, de la vérification de votre solde bancaire et du streaming multimédia à l'interaction avec un terminal connecté, comme une lampe, une sonnette ou une voiture, en passant par l'enregistrement pour un vol ou un voyage en train. Tous ces services nécessitent un traitement des informations en temps réel et à grande échelle. Ces exemples illustrent parfaitement la manière dont l'Edge Computing peut faire la différence entre une expérience exceptionnelle et une expérience lente et frustrante.
Exemples courants d'utilisation de l'Edge Computing :
- Jeux vidéo. La réactivité en temps réel, les temps d'attente, le matchmaking et la faible latence sont essentiels pour les jeux de compétition. L'Edge Computing améliore ces expériences digitales en augmentant la proximité avec les joueurs.
- Réseaux IoT. Les solutions d'Edge Computing permettent aux entreprises de tirer parti de la puissance des réseaux IoT pour collecter, analyser et agir sur d'énormes quantités de données en temps réel.
- Véhicules autonomes. Les voitures autonomes produisent d'énormes quantités de données qui doivent être agrégées et analysées en temps réel, ce qui permet au véhicule de prendre des décisions en une fraction de seconde pour amener les passagers et le chargement à la destination appropriée en toute sécurité.
- Télécommunications. L'Edge Computing permet aux fournisseurs de services de télécommunications de moderniser leurs réseaux et de déplacer les charges de travail et les services vers la périphérie du réseau pour des performances supérieures.
- Industrie et production. Les fabricants s'appuient sur l'Edge Computing pour surveiller les équipements, identifier les erreurs de production, activer l'automatisation, gérer la robotique et améliorer la qualité grâce à l'analyse en temps réel et à l'apprentissage machine.
- Énergie. Les entreprises impliquées dans l'exploration et la production d'énergie utilisent l'Edge Computing pour collecter et stocker des données sur les plateformes pétrolières et les gisements de gaz, fournissant ainsi des renseignements en temps réel capables de détecter les dangers, d'optimiser la production, d'améliorer l'efficacité et de protéger le personnel.
- Applications de sécurité. De la reconnaissance faciale en temps réel dans les aéroports aux détecteurs de mouvement et caméras sur site, de nombreuses applications de sécurité et de surveillance bénéficient des temps de réponse ultra-rapides disponibles lorsque les données sont traitées à la périphérie du réseau.
- Santé. L'Edge Computing est la meilleure solution pour collecter et traiter l'énorme volume de données produites par les terminaux et les capteurs médicaux, ce qui permet aux fournisseurs de réagir rapidement aux changements de l'état des patients.
- Villes intelligentes. Les villes intelligentes utilisent l'Edge Computing pour alimenter des applications en temps réel telles que les feux de circulation intelligents, les réseaux électriques intelligents, les lampadaires intelligents et les systèmes de surveillance intelligents qui doivent être capables de traiter les données avec des temps de réponse d'une fraction de seconde et une précision supérieure.
- Réalité augmentée (RA) et réalité virtuelle (VR). La réalité augmentée et la réalité virtuelle nécessitent toutes deux un traitement en temps réel de grands ensembles de données avec un décalage proche de zéro.
- Intelligence artificielle (IA) L'Edge Computing permet aux applications d'IA et d'apprentissage machine de générer, récupérer et traiter d'énormes volumes de données avec une plus grande vitesse et une connectivité fiable.
Quels sont les avantages de l'Edge Computing ?
Pour comprendre ses avantages, vous pouvez envisager l'Edge Computing comme l'utilisation de votre banque locale et d'un distributeur automatique de billets plutôt que du siège central de la banque dans une ville située à des centaines de kilomètres. Plutôt que de parcourir de longues distances pour effectuer un dépôt ou retirer de l'argent, vous pouvez simplement vous rendre à quelques centaines de mètres dans votre agence locale, ce qui vous fait gagner beaucoup de temps et d'argent. Si tous vos voisins font de même, vous réduirez également les embouteillages sur les routes locales. Vous aurez également une expérience plus sécurisée, car il est moins probable que vous rencontriez des problèmes de voiture, que vous ayez un accident ou que votre argent soit volé en conduisant quelques pâtés de maisons jusqu'à votre banque locale.
Les avantages de l'Edge Computing sont les suivants :
- Faible latence. La latence est le délai pénible qui a lieu lorsque vous naviguez sur un site Web et que vous attendez le chargement de la page, ou lorsque vous appuyez sur une application pour mobile et que vous devez attendre son démarrage. Cela se produit généralement car les centres de traitement et de stockage des données sont physiquement loin de vous. Lorsque ces processus sont déplacés en bordure de l'Internet, géolocalisée près de vous, des expériences digitales en temps quasi réel sont possibles.
- Réduction des coûts. En minimisant le trafic réseau, l'Edge Computing aide à réduire les coûts associés à la fourniture d'une bande passante suffisante, ainsi qu'au déplacement et au stockage des données dans le cloud.
- Performances supérieures. Lorsque les données sont fournies avec moins de latence et des temps de chargement rapides, les entreprises peuvent compter sur des performances supérieures de leurs réseaux, systèmes et applications.
- Améliorer l'expérience client. En améliorant les temps de réponse et en réduisant la latence, l'Edge Computing améliore l'expérience des clients lorsqu'ils interagissent avec les sites Web et les applications.
- Souveraineté des données. En maintenant les données locales et en ne dépassant pas les frontières nationales ou régionales, l'Edge Computing permet aux entreprises d'éviter les problèmes de souveraineté des données et de simplifier la conformité aux réglementations en matière de confidentialité des données dans diverses régions.
- Améliorer la productivité. L'Edge Computing permet aux utilisateurs d'accéder plus rapidement aux données et aux analyses, ce qui leur permet de prendre des décisions et d'agir plus rapidement.
- Prise de décision plus rapide. Des temps de réponse plus rapides et une connectivité réseau fiable se traduisent par une livraison plus rapide des données dont les dirigeants d'entreprise ont besoin pour prendre des décisions éclairées.
- Résilience accrue. En déplaçant le traitement des données vers un réseau de terminaux et de sites en bordure de l'Internet, l'Edge Computing fournit des chemins redondants pour la transmission et le traitement des données localement afin d'éliminer un point central de défaillance potentiel avec des serveurs centralisés.
Les solutions d'Edge Computing de pointe d'Akamai
Akamai fournit une infrastructure en bordure de l'Internet pour la création et l'exécution d'applications et de services de manière flexible et avec une évolutivité, une fiabilité et une sécurité inégalées. Avec notre plateforme en bordure de l'Internet et de cloud massivement distribuée, nous pouvons offrir le meilleur en matière d'applications en bordure de l'Internet, de services informatiques et d'optimisation du cloud. La transformation digitale n'a jamais été aussi simple.
- EdgeWorkers fournit aux équipes de développement des fonctionnalités et des outils permettant de créer de nouveaux microservices qui exploitent la plateforme d'Akamai pour des calculs sécurisés et rapides en bordure de l'Internet.
- EdgeKV est une solution de stockage clé-valeur distribuée d'Akamai qui permet aux développeurs JavaScript de créer des applications EdgeWorkers axées sur les données.
- Cloudlets propose des outils permettant d'exécuter la logique applicative en bordure de l'Internet pour offrir de meilleures expériences Web grâce à des applications robustes et en libre-service.
Foire aux questions (FAQ)
L'Edge Computing est une architecture informatique où les données sont stockées et traitées à la périphérie du réseau, plus près des utilisateurs, des terminaux et des applications qui les génèrent et les utilisent. Cela réduit la latence et l'encombrement du réseau pour améliorer les temps de réponse et permettre une prise de décision en temps réel. Un réseau de distribution de contenu est un ensemble de serveurs répartis géographiquement qui stockent et diffusent le contenu le plus près possible des utilisateurs, afin d'améliorer les temps de réponse et l'expérience utilisateur. L'Edge Computing et les CDN sont conçus pour rapprocher le contenu des données de la périphérie du réseau. Cependant, les CDN sont simplement responsables de la mise en cache des copies statiques des données, tandis que les réseaux en bordure de l'Internet stockent et traitent les données.
L'Edge Computing apporte des fonctions telles que le traitement des données, le stockage, la mise en réseau et la sécurité à la périphérie du réseau, en s'appuyant sur un large éventail de terminaux pour traiter et stocker les données à proximité des utilisateurs et des applications qui en ont besoin. Le Cloud Computing utilise la technologie de virtualisation pour créer de vastes pools de ressources informatiques dans les centres de données du monde entier, ce qui rend les ressources informatiques disponibles à la demande et accessibles via Internet. Le Cloud Computing exécute des charges de travail sur des ressources cloud qui résident généralement dans des centres de données distants, tandis que l'Edge Computing exécute des charges de travail sur des terminaux situés à la périphérie du réseau.