

Rilevamento di codice JavaScript dannoso con Secure Internet Access Enterprise Secure Web Gateway


Scritto da: Jordan Garzon
Introduzione
Immaginate un modo senza JavaScript. Sono innumerevoli le volte in cui io e i miei colleghi ci abbiamo pensato a un certo punto della nostra carriera e, per il momento, un fondo senza JavaScript è difficile da immaginare. Lavorando in un'azienda che ha a che fare con JavaScript da diversi anni, sono ben consapevole delle sfide e di quanto sia prevalente nel nostro settore. In effetti, la protezione dei codici JavaScript rappresenta una parte enorme della nostra missione, che ci piaccia o no.
JavaScript è ovunque. Ogni richiesta a un sito Web e applicazione mobile carica decine di righe di codice JavaScript; ogni browser lo supporta. È così onnipresente che si può tranquillamente considerare una tecnologia critica, una di quelle che plasma il modo in cui i siti Web vengono creati e funzionano. Inoltre, come sappiamo tutti, in termini di sicurezza, più critica è una tecnologia, più modi ci sono per usarla in modo dannoso.
Essendo così pervasivo, attaccare e usare codice JavaScript offre agli avversari la possibilità di creare notevoli danni sfruttando l'enorme superficie di attacco offerta da JavaScript. Il potenziale impatto di un attacco di ampia portata è stato illustrato dalla vulnerabilità Log4j scoperta nel dicembre 2021, un vettore di attacco che, una volta scoperto, ha offerto una scalabilità immediata. Log4j, una libreria Java, offre capacità di accesso, una funzionalità base usata da quai tutti gli sviluppatori. Ecco la differenza tra le vulnerabilità di JavaScript e le altre vulnerabilità: la sua enorme presenza tra il codice di produzione.
Con questa consapevolezza, prevale la domanda onnipresente: “Allora, cosa possiamo fare al riguardo?” Dopo aver visto lo scompiglio creato da Log4j, ambiamo deciso di provare a rispondere in modo definitivo alla domanda e abbiamo lanciato un'indagine per comprendere e rilevare codici JavaScript dannosi. Tutto ciò ha portato al progetto di cui vi sto scrivendo oggi. La ricerca sulla sicurezza è sempre divertente e, quando abbiamo visto che la nostra teoria funzionava, abbiamo fatto un passo in avanti e abbiamo provato alcune situazioni contestuali del mondo reale.
In questo blog, voglio parlarvi della nostra indagine e delle tecniche che abbiamo usato per identificare e isolare i codici JavaScript dannosi al fine di creare una nuova capacità nel nostro prodotto. Sarà incluso un esame del paesaggio di minacce relative a JavaScript, tra cui l'architettura di sistema, gli algoritmi applicati e un caso di studio.
Paesaggio di minacce JavaScript dannose
Prima di entrare nel vivo del progetto, guardiamo il paesaggio che rende il codice JavaScript dannoso un vettore di minacce così rilevante. Ho già menzionato la sua pervasività, ma fino a quale profondità arriva? Comprendere questo fattore permette di inquadrare perfettamente il progetto. Di seguito sono sottolineati alcuni degli attacchi più prevalenti perpetrati usando JavaScript in rete.
Exploit del browser
Non c'è bisogno che vi dica quanto sia grande questa minaccia: i browser e i relativi plugin sono un elemento chiave di chiunque abbia un computer. Un esempio calzante è rappresentato dal Browser Exploitation Framework Project, noto anche come BeEF. BeEF è uno strumento di test delle penetrazione incentrato sui browser Web (uno dei maggiori vettori di attacco lato client), che evidenzia benissimo la sfruttabilità.
Skimmer
Gli skimmer sono un noto esempio di come la sicurezza informatica possa influire sulla vita al di fuori dell'ambito aziendale e diventare molto personale. Dal momento che JavaScript controlla il Document Object Model, è in grado di modificare non solo l'HTML generato, ma anche le richieste HTTP sottostanti. Ciò può essere visto in un'azione semplice come il clic su un pulsante da parte di un utente.
Un esempio nel mondo reale può essere derivato da qualsiasi sito con commercio digitale associato. Se un codice JavaScript dannoso viene inserito in un sito Web legittimo, tutte le credenziali delle carte di credito catturate dallo skimmer possono venire indirizzate all'autore dell'attacco. Il caso più rinomato si è verificato nel 2018 L'attacco Magecart al sito Web di British Airways che ha rubato circa 380.000 numeri di carte di credito.
Lo skimming è cambiato dal 2018. Un modo comune con il quale questa tecnica viene usata oggi è quello di sostituire gli indirizzi bitcoin con l'indirizzo dell'autore dell'attacco su un sito Web legittimo, come abbiamo visto con il gruppo Lazarus negli ultimi anni.
Clickjacking
Sebbene l'agire su un sito Web legittimo consente un'ampia disseminazione, ha un ambito limitato rispetto a un server di cui si ha il pieno controllo. Se l'autore dell'attacco convince l'utente ad avvicinarsi di sua volontà, ha il vantaggio di giocare in casa. Ciò assicura all'autore dell'attacco un impatto più grande. Una volta che le vittime sono approdate nel suo territorio, l'autore dell'attacco può convincerle a scaricare il malware, a recuperare informazioni dalla loro sessione di navigazione e ad eseguire molte attività dannose.
Un classico modo per farlo è quello di creare un iframe trasparente sopra uno legittimo, dando agli utenti un falso senso di sicurezza quando ci cliccano sopra. Questo iframe reindirizza gli utenti verso il server controllato dall'autore dell'attacco, dove può eseguire una miriade di attività dannose.
Crypto-mining non autorizzato
Il crypto-mining ha attirato molta attenzione negli ultimi anni, grazie al picco di utilizzo delle cryptovalute di oggi. Perché non usare il CPU di un utente per cercare le criptovalute? Soprattutto quando questa operazione richiede solo una riga di codice JavaScript. La più famosa libreria è stata Coinhive, che si dice sia stata chiusa nel 2019, ma è stata ovviamente sostituita in esempi come CoinIMP o CryptoLOOT.
Motore di rilevamento di codici JavaScript dannosi: architettura e algoritmi
Ora che abbiamo analizzato il paesaggio, è arrivato il momento di descrivere ciò che abbiamo creato. Esistono due modi per inserire il codice JavaScript in un sito Web: scrivendo un file JavaScript nello stesso server o usandone uno esistente da un'altra fonte e inserendo il link nella pagina HTML. Sul lato proxy vedremo due richieste HTTP diverse, una per l'HTML e l'altra per il file JavaScript. Inserendo il singolo sito Web, il browser può eseguire centinaia di richieste HTTP per il rendering dell'intero sito Web.
È possibile anche scrivere il codice JavaScript all'interno dell'HTML stesso. In questo caso, non sono necessarie altre richieste per recuperarlo. Discutendo di come rilevare codici JavaScript dannosi, deve esserci un modo per affrontare entrambi i lati, infatti è quello che abbiamo creato.
Il nostro nuovo motore è in grado di estrarre i codici JavaScript "inline" e analizzarli separatamente. Di seguito è riportato un estratto della pagina sorgente del New York Times , che mostra i due tipi di JavaScript:
 on February 2, 2022")
Estratto di codice HTML del New York Times (https://www.nytimes.com/), 2 febbraio 2022
Akamai Secure Internet Access Enterprise Secure Web Gateway (SWG) comprende diversi motori che analizzano il traffico in tempo reale. Si connette anche alle nostre informazioni sulle minacce ed è arricchito dai nostri algoritmi personalizzati.
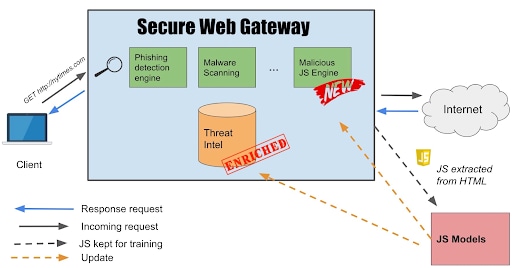 High-level overview of the Enterprise Threat Protector secure web gateway
High-level overview of the Enterprise Threat Protector secure web gateway
Facciamo uno zoom nella casella rossa "Modelli JS":
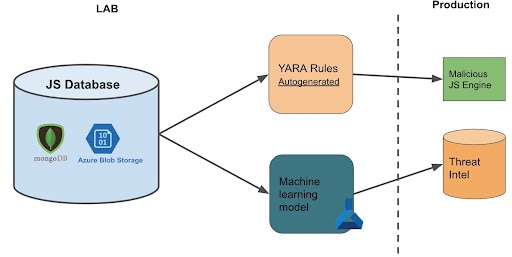
Database
I modelli fanno affidamento su un database relazionale per conservare i metadati e archiviare il codice JavaScript tramite un fornitore dell'archiviazione.
Il database include un set di training, ad es. i nostri dati etichettati: I dati legittimi arrivano soprattutto da codice JavaScript popolare visto nel nostro traffico. I dati dannosi vengono inseriti tramite varie fonti: VirusTotal (VT), rilevamenti da altri algoritmi e codice dannosi effettivamente rilevato. Pertanto, vengono costantemente aggiornati.
Il DB contiene anche il set di testi, in sostanza i giorni di traffico più recente visto sul proxy.
Modello per il rilevamento in tempo reale
Per poter rilevare il codice JavaScript dannoso in tempo reale, usiamo le regole YARA , che sviluppiamo sull'edge. Queste regole vengono create sulla base del set di training. Dal momento che la creazione di regole non è un'attività semplice, abbiamo basato un algoritmo su questo documento , che genera automaticamente le regole Yara. Lo abbiamo adattato per classificare il codice JavaScript anziché il codice binario e abbiamo modificato la logica di generazione delle regole, il che significa che possiamo aggiornare il motore JavaScript dannoso su SWG on demand.
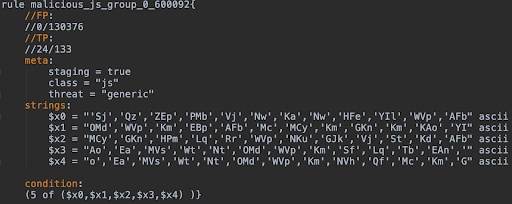 Example of a YARA rule generated with AutoYara
Example of a YARA rule generated with AutoYara
Arricchimento delle informazioni sulle minacce tramite il modello di apprendimento automatico
Un noto problema che i ricercatori devono affrontare per individuare il codice JavaScript è l'offuscamento, una tecnica (usata anche da siti Web legittimi) che minimizza il codice e lo trasforma in in linguaggio incomprensibile. Or Katz ha scritto un post del blog al riguardo ad ottobre 2020.
Per poterli rilevare, abbiamo integrato la nostra logica in un modello ispirato a JStap, che viene eseguito sull'albero sintattico astratto, una rappresentazione ad albero del codice, che poi è il modo con cui aggiriamo questa tecnica.
Un modello di apprendimento automatico può fornire una maggiore accuratezza rispetto alle regole YARA. Tuttavia, la sua implementazione sull'edge per l'analisi in tempo reale è complessa. Perciò, abbiamo ideato qualcosa a metà. Il nostro modello viene addestrato con lo stesso set di training, analizza il traffico offline (sull'ambiente Azure Machine Learning) e popola le informazioni sulle minacce con quello che trova.
Le informazioni sulle minacce vengono verificate ad ogni connessione con l'SWG, in questo modo i clienti traggono beneficio dal rilevamento del modello di apprendimento automatico.
In azione: un caso di studio
Il modo migliore per mostrarlo è quello di usare un esempio di vita reale. L'8 marzo, 2022, il modello di apprendimento automatico ha rilevato un codice JavaScript ospitato su cigarettesblog[.]blogspot[.]com.
In data 10 marzo 2022, questo dominio mostrava 0 rilevamenti sul VT.
![Home page di cigarettesblog[.]blogspot[.]com vista il 9 marzo](/site/it/images/blog/2022/detecting-malicious-javascript-with-swg5.jpeg) Home page of cigarettesblog[.]blogspot[.]com seen on March 9
Home page of cigarettesblog[.]blogspot[.]com seen on March 9
Nel seguente estratto, il codice JavaScript sostituisce tutti i link HTML con URL dannosi.
Uno di essi, hxxps://myprintscreen[.]com/soft/myp0912.exe, che è stato commentato nel codice, sta effettivamente scaricando un Trojan (4a6ffa02ff7280e00cf722c4f2235f0e318e6cc8a2b9968639ba715f1a38c834), che presenta 23 rilevamenti sul VT. Altri URL sono stati contrassegnati come dannosi da molti fornitori sul VT.
Si tratta di un comportamento classico di un codice JavaScript dannoso: sostituire gli URL sulle pagine, inviare le richieste POST ad altri domini (vedete l'estratto di seguito) o condurre un attacco guidato per convincere l'utente a scaricare un malware sul proprio computer.
![Codice JavaScript estratto da cigarettesblog[.]blogspot[.]com il 9 marzo 2022](/site/it/images/blog/2022/detecting-malicious-javascript-with-swg6.png) JavaScript code extracted from cigarettesblog[.]blogspot[.]com on March 9, 2022
JavaScript code extracted from cigarettesblog[.]blogspot[.]com on March 9, 2022
URL:
myprintscreen[.]com/soft/myp0912.exe
www[.]blog-hits.com
Hash file:
4a6ffa02ff7280e00cf722c4f2235f0e318e6cc8a2b9968639ba715f1a38c834 (Trojan)
fc311d002d7139e0a58b00464731ba8d4faea4670cff9fedfb35057fe838c285 (file JavaScript caricato da noi il 10 marzo)
Lo stesso meccanismo è stato rilevato su penis-photo.blogspot[.]com.br (il 10 marzo) o su mateyhderesa[.]blogspot.com (il 13 marzo), playboy-college-girls.blogspot.sk (14 marzo).
Riepilogo
Come ho detto all'inizio del post, qualsiasi cosa sia critica per la sicurezza può essere usata a fini dannosi, e qualcosa di prevalente come il codice JavaScript può avere gravi conseguenze. Può essere difficile da decrittografare; un post del blog precedente ha dimostrato che il 25% del codice dannoso che vediamo è offuscato. Non si tratta di una percentuale insignificante e, considerato quanto vediamo di Internet, è alquanto rappresentativa dell'espansione del problema.
Questa ricerca è iniziata come un modo per rendere più sicuri i nostri clienti, così abbiamo preso le nostre scoperte e le abbiamo applicate al nostro SWG. Abbiamo due nuovi modelli: basati su YARA e basati sull'apprendimento automatico. Il modello basato sulle regole YARA analizza qualsiasi codice JavaScript che attraversa l'SWG per una protezione in tempo reale. Il modello basato sull'apprendimento automatico verifica due volte il traffico per aggiornare le informazioni sulle minacce sull'edge. Entrambi i modelli sono costantemente aggiornati e riaddestrati e tengono conto delle minacce più recenti oltre che del nuovo codice JavaScript legittimo osservato in rete.

