

Think about Bot: Botリクエストの把握・対処の難しさを考える


Bot(自動でWebサイトにアクセスし、情報を収集したり処理を実行したりするプログラム)とそのリクエストに対する対処に注目が集まっています。しかしSQL Injection等の明らかな攻撃とは異なり、良性/悪性が常に区別できるとは限らないのがBotリクエストの検知・対処の難しいところです。本記事では、国際学会やジャーナルで発表された学術論文を調査し、Botリクエストの分類と検知技術について紹介します。そこから、Botリクエストの把握・対処の難しさについて議論したいと思います。
BOTリクエストとは
Google Dictionaryでは、「Bot」という単語に対して、「an autonomous program on the internet or another network that can interact with systems or users.(インターネットやネットワーク上で、システムやユーザーとやり取りできる自動プログラム)」という説明がされています。特にWebアクセスにおけるBotは、自動でWebサイトにアクセスし、情報を収集したり処理を実行したりするプログラムのことを指し、こうしたプログラムから送信されたリクエストを「Botリクエスト」と呼ぶことが多いのではないでしょうか。
プログラムの例として、PythonでHTTPクライアントライブラリを使用して、オンラインショッピングサイトの在庫確認を行い、その結果をデータベースに保存するBotを作成する場合、下記のようなコードが書けます。
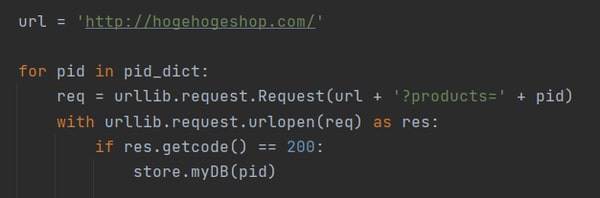
図1: 商品の在庫確認を行うPythonコードの例
もちろん、世の中に存在するBotは、このようなシンプルなものばかりではありません。
どんなBOTが存在するのか?
Rovettaらの論文[1]では、WebにおけるBotリクエストを下記の4種類に分類しています。
- Webクローラ...検索エンジンによるWebサイトの情報収集を行う
- プライバシーや倫理的に問題があるWebクローラ...メールアドレス等の機微な情報を収集したり、ブログにスパムコメントを投稿したりする
- 広告クリック等により金銭的な被害を発生させるBot...広告バナーをクリックする等により、広告主の予算を不正に消費させる
- 競合他社に対して不利な状況にさせ得るクローラ...競合他社のWebサイトを解析して競合よりもSEO的に有利な位置に立つ、アカウントを入手して会員特典情報を入手したりカートに商品を買わずに保持する
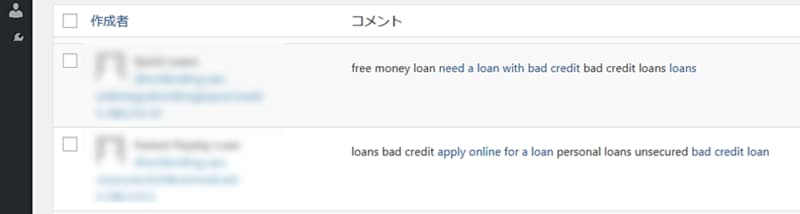
図2: スパムコメントの投稿例
上記に加え、特に近年では、Eコマースサイトに対して商品の監視・自動購入を行うツールが存在します。設定項目も充実しており、リクエスト元のUser-Agent値や対象商品の監視頻度、自動購入に際しての価格の上限・下限、該当する商品を見つけた後のアクション(メールを送信する、アラームを鳴らす、注文処理を完了させる等)などを、GUI上できめ細かく設定できるツールも存在します。
このように、Botリクエストといってもその目的やWebサイトに対する影響は様々です。1のWebクローラは多くの場合、Webサイトにリクエストが到達しても問題ないと判断される管理者が多いはずです。一方で、2、3、4や監視・自動購入ツールに対しては、できればWebサイトに訪問して欲しくない、あるいは訪問を止めたい、と考える管理者の方が多いはずです。そこで、Botリクエストの検知技術が求められてきています。
どうやってBOTリクエストを見つけるのか?
Botリクエストの検知技術や、実際の環境で観測されたBotリクエストの分析報告が国際学会やジャーナルでも多く発表されています。本記事では、その中から論文3本を取り上げて、検知技術や分析報告をご紹介します。
PUBCRAWL: Protecting Users and Businesses from CRAWLers (2012年)[2]
Jacobらの論文では、ソーシャルネットワークサービスへの適用を想定して、リクエストの特徴と時系列データの2種類の特徴を用いてクローラからのリクエストを検知する手法を提案しています。リクエストの特徴では、エラーレスポンス率が高い、プロフィール閲覧順序が異常、といった、人間からのリクエストとは異なる特徴を用いてクローラを判断します。時系列データでは、クローラと人間からのリクエストタイムラインに差が出ることを用いてクローラを判断します。論文では、この検知手法を実際のソーシャルネットワークに適用し、BingbotやGooglebotなどの良性クローラ、User-Agent値がなかったりスクリプトのライブラリ名が含まれていたりするクローラ、User-Agent上ではFirefoxやGooglebotを名乗っているものの実際は異なると判断されるクローラが検知できたと報告されています。さらには、RefererやCookieを偽装したとみられる、クローラ検知回避を狙ったリクエストも報告されています。
Analysis of aggregated bot and human traffic on e-commerce site (2014年)[3]
Suchackaの論文では、ある書店Webサイトに対するアクセスログを対象に、リクエストセッションの特徴を調査した結果を報告しています。特徴は、訪問ページ数や訪問時間、リクエスト数に対する画像ファイルの割合、HEADメソッドやエラーレスポンスの割合などの10項目です。その上で、「HEADメソッドの割合が100%」、「エラーレスポンスの割合が100%」といった条件を複数定義し、その条件に合致するセッションをBotとし、人間とBotリクエストの特徴の違いを複数の観点から分析しています。例えば、画像ファイルやReferer含有率の分布では、人間とBotで分布の様子が大きく異なることが示されています。
SpiderTrap—An Innovative Approach to Analyze Activity of Internet Bots on a Website (2020年)[4]
Lewandowskiらの論文では、Botリクエストを収集するため、おとりWebサイトを構築し、実際に運用してBotリクエストを収集したことが報告されています。おとりWebサイトはPhilosophy of GNU Projectのコンテンツを利用し、各ページ内にリンクをランダムに埋め込む形でページを自動で生成します。リンクは<a href>タグやHTMLソースにコメントとして埋め込む等のパターンを複数用意しています。このWebサイトを140日間インターネット上で運用し、Botリクエストを収集した結果も報告されています。収集できたBotリクエストは、脆弱性スキャン等の悪性だったものが全体の約61%を占めていたとしています。さらに、Botリクエストの中には実際には存在しない環境を示す値がUser-Agentに含まれていた例も紹介されていました。例えば、「Mozilla/1.22; MSIE 10.0; Windows 3.1」はWindows 3.1上のInternet Explorer 10からのリクエストであることを示す値ですが、Windows 3.1上でInternet Explorer 10は動作しないため、実際の環境から到達したリクエストである可能性は非常に低いとしています。
このようにBotリクエスト検知技術は、製品だけではなく、学術面でも注目されるトピックのひとつになっています。
BOTリクエストの把握・対処の難しさ
上記で紹介した検知技術や分析報告から、Botリクエストの把握・対処の難しさを示す要素が大きく2点出てきます。まず、Botリクエスト検知技術では、主に経験則ベースで定義したリクエストヘッダ・レスポンスの特徴と、リクエスト送信タイムラインの2種類の情報を使って、リクエストが人間あるいはBotによるものかを判断しています。これは、シグネチャマッチング式でSQL Injection等のWeb攻撃を検知する手段と比較すると、検知ロジックが複雑になっていることがわかります。
次に、Botリクエストも複数種類存在することや、Botリクエスト検知と一言で表現しても、それが示すものは論文によって異なり、検知したいBotや適用先のサービスが多様です。このため、Botリクエストの対処を考えるときに、何をBotとして検知し、さらにどの程度対処すれば良いのかが見えづらいという難しさもあります。
そこで、Botリクエストの対処を進めるに際して押さえたいポイントとして、まずはお客様自身のWebサイトにどういったユーザーあるいはBotが到達していて、特にWebサイトやサービスを困らせるBotリクエストの調査・把握を行うことが挙げられます。その上で、深刻な悪影響を及ぼすBotリクエストから優先して対処し、併せて検知ロジックの理解を進めて頂くことが重要です。さらにAkamaiでは、Bot対策製品であるBot Managerだけでなく、キャッシュ応答や負荷分散製品(Cloudlet Visitor Prioritizationなど)と組み合わせて、オリジン負荷軽減を含めたBotの対処も可能です。
[1] Stefano Rovetta, Grażyna Suchacka, and Francesco Masulli. "Bot recognition in a Web store: An approach based on unsupervised learning." Journal of Network and Computer Applications 157 (2020): 102577.
[2] Gregoire Jacob, Engin Kirda, Christopher Kruegel, and Giovanni Vigna. "PUBCRAWL: Protecting Users and Businesses from CRAWLers." 21st USENIX Security Symposium (USENIX Security 12). 2012.
[3] Grażyna Suchacka. "Analysis of aggregated bot and human traffic on e-commerce site." 2014 Federated Conference on Computer Science and Information Systems. IEEE, 2014.
[4] Piotr Lewandowski, Marek Janiszewski, and Anna Felkner. "SpiderTrap--An Innovative Approach to Analyze Activity of Internet Bots on a Website." IEEE Access 8 (2020): 141292-141309.
