
機械学習は、システムが人間の言語を理解し生成することを可能にし、自然言語処理(NLP)において重要な役割を果たします。機械学習は、感情分析、チャットボット、言語翻訳、テキスト要約などのアプリケーションで使用されています。NLP モデルは、大量のテキストデータからパターンを分析して学習することで、機械が人間の言語のニュアンスを解釈し、正確に応答できるようにします。
機械学習は AI の一分野であり、データから学習し、データに基づいて予測や判断を行うことができるアルゴリズムの開発に重点を置いています。機械学習では、ラベル付けされたデータセットを使用してモデルをトレーニングし、データ内のパターンや相関関係を認識します。これらのモデルは、そのパターンを使用して、新たな未知のデータに関する予測を行います。
機械学習(ML)は、人工知能の研究分野の 1 つであり、コンピューター自体が学習して、明示的にプログラムされずに予測や判断を行えるようにするアルゴリズムやモデルを開発することに重点を置いています。大量のデータを使用してコンピューターシステムをトレーニングすることにより、システムがパターンを認識し、知見を引き出し、正確な予測や判断を行えるようにします。
機械学習では、コンピューターは人間が定めた厳格なルールに従うのではなく、過去のデータを分析することで、経験から学習します。目標は、利用可能なデータの増加に伴って自動的にパフォーマンスを向上させることができるアルゴリズムを開発することです。システムがエラーを回避するためには大量の正確なトレーニングデータセットが必要であるため、効果的な機械学習アルゴリズムを開発するためには十分なデータが不可欠です。今日の世界で機械学習が重要である理由はいくつかあります。
機械学習の利点
機械学習は、テクノロジーとの関わり方に革命をもたらし、さまざまな業界で無数の可能性を切り開いてきました。この人工知能の分野は、コンピューターがデータから学習し、明示的にプログラムされることなく予測や判断を行えるようにします。機械学習の利点は数多くあり、その影響はさまざまな業界で見られます。
機械学習の大きな利点の 1 つは、大量の複雑なデータを処理できることです。従来の方法では、手動による分析を必要とする大規模なデータセットに直面した場合に課題が生じます。一方、機械学習アルゴリズムは、大量の情報を簡単に、迅速に、そして正確に処理できます。これにより、企業はデータ内に隠れた貴重な知見やパターンを明らかにし、より多くの情報に基づいて意思決定を行うことができます。
もう 1 つの利点は、効率性の向上と自動化です。機械学習モデルは、人間にとって時間のかかる反復的なタスクを自動化できます。そのようなプロセスを自動化することで、組織は従業員を解放して、人間の創造力と問題解決スキルを必要とするより重要なタスクに集中させることができます。
また、機械学習により、過去のふるまいパターンや嗜好を活用し、ユーザーの体験をパーソナライズできるようになります。Amazon、Netflix、Spotify などのプラットフォームで使用されているレコメンデーションシステムは、このパーソナライズ機能の代表的な例です。そのようなシステムは、閲覧履歴や購入記録などのユーザーデータを分析し、個々のユーザーの関心に合わせてカスタマイズされた商品提案やコンテンツ提案を行います。
機械学習は、パーソナライズに加えて、不正検知やサイバーセキュリティの取り組みにも大きく寄与します。金融機関は、トランザクションパターンをリアルタイムで継続的に分析して、疑わしいアクティビティを迅速に特定する高度な不正検知アルゴリズムを採用しています。同様に、機械学習ベースのセキュリティシステムは、従来のセキュリティアプローチよりもはるかに迅速に、マルウェア攻撃やネットワーク・トラフィック・パターンの異常を検知できます。
さらに、機械学習は、病気の診断や創薬研究などのヘルスケアアプリケーションでも重要な役割を果たします。機械学習モデルは、世界中の何百万人もの患者の医療記録と遺伝データを分析することにより、医師が過去に遭遇した同様のケースに基づいて正確な診断を行えるよう支援します。
最後に、機械学習を活用した予測分析は、企業が過去のデータの分析に基づいて将来の傾向を正確に予測するために役立ちます。これにより、企業は顧客の需要の予測、生産プロセスの最適化、プロアクティブな意思決定を行い、業務効率や収益性を高めることができます。機械学習アルゴリズムは、開発されたモデルに基づいて将来の業績を予測することができます。
機械学習の種類
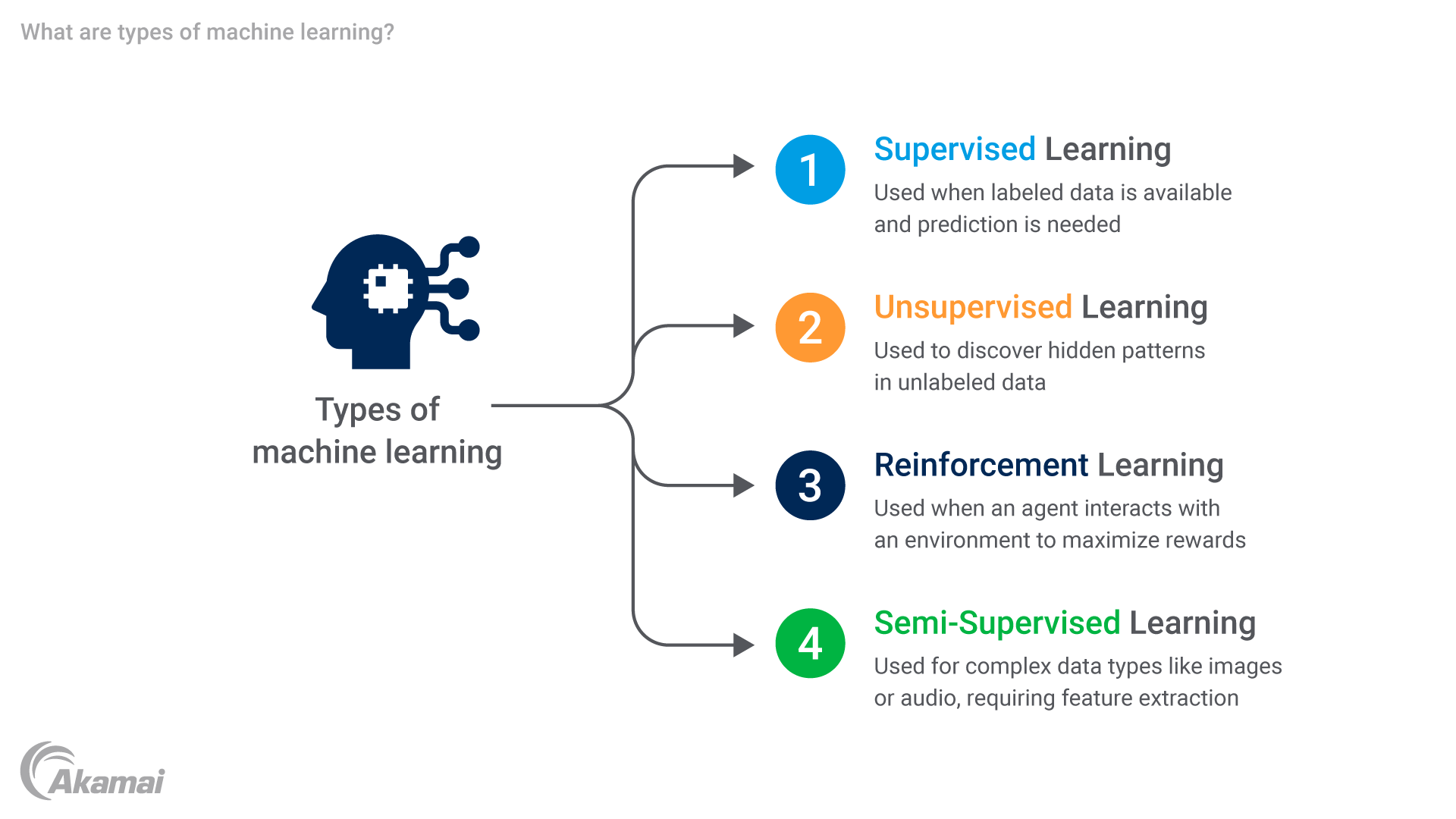
機械学習にはいくつかのカテゴリーがあり、それぞれが固有の特性を備え、さまざまな目的の達成に寄与します。その機械学習の種類には、「監視あり学習」、「監視なし学習」、「強化学習」、「半監視あり学習」があります。ここでは、これらの学習手法について詳しく説明します。
監視あり学習:このアプローチでは、入力(特徴量)と目的の出力(ラベル)の両方が提供されるラベル付きの例を使用して機械学習アルゴリズムをトレーニングします。その後、このモデルはトレーニングに使用した例に基づいて一般化を行い、未知の新しい入力インスタンスのラベルを予測します。
監視なし学習:この学習方法では、機械学習アルゴリズムは事前定義された出力やターゲットを使用せずに、ラベル付けされていないデータを探索します。主な目的は、データセット内の隠れた関係や構造を発見することです。
強化学習:この手法では、エージェントが環境とインタラクションを行い、利益を最大化したりペナルティを最小限に抑えたりするためのアクションの実行方法を学習します。エージェントは、環境から受け取ったフィードバックに基づき、試行錯誤を通じて学習します。
半監視あり学習:この機械学習アプローチでは、少量のラベル付きデータと大量のラベルなしデータを組み合わせてトレーニングに使用します。この方法は、豊富なラベルなしデータを活用してモデルのパフォーマンスと汎化性能を向上させるため、十分なラベル付きデータがない場合や、ラベル付きデータの取得にコストがかかる場合に特に有用です。
機械学習とディープラーニングの違い
機械学習とディープラーニングは、人工知能の領域内の関連する概念であり、ディープラーニングは多層的なニューラルネットワークを使用する機械学習の下位分野です。
機械学習は AI の一分野であり、データから学習し、データに基づいて予測や判断を行うことができるアルゴリズムの開発に重点を置いています。機械学習では、ラベル付けされたデータセットを使用してモデルをトレーニングし、データ内のパターンや相関関係を認識します。これらのモデルは、そのパターンを使用して、新たな未知のデータに関する予測を行います。
ディープラーニングは機械学習の下位分野であり、多層的な人工ニューラルネットワークをトレーニングして、大量のデータから複雑なパターンや表現を学習することに重点を置いています。これは、相互に接続されたニューロンを介して情報が流れる人間の脳の構造と機能からインスピレーションを得たモデルです。
ディープラーニングの「ディープ」という用語は、入力層と出力層の間に複数の隠れ層があるニューラルネットワークの深さを指します。その隠れ層により、ネットワークは階層的な特徴量や抽象的な表現をさまざまなレベルで抽出し、データ内の複雑な関係を把握することができます。
ディープ・ラーニング・モデルは通常、膨大な量のラベル付きデータを使用してトレーニングされます。このプロセスでは、入力データをネットワークの初期層にフィードし、複数の中間層(隠れ層とも呼ばれる)を通過させ、最終層から出力予測を生成します。このモデルは、トレーニング中に勾配降下法などの最適化アルゴリズムを使用して内部パラメーターを繰り返し調整し、エラーを最小限に抑えたり、パフォーマンスを最大化したりします。
この 2 つのモデルには主に次のような違いがあります。
- 表現:従来、機械学習では、エンジニアがアルゴリズムへの入力として機能を手動で設計する必要がありました。一方、ディープ・ラーニング・モデルは、生の入力データから階層的な表現を自動的に抽出できます。
- 複雑さ:ディープ・ラーニング・モデルは、複数の層と多数のパラメーターがあるため、従来の機械学習モデルよりも複雑になる傾向があります。
- データ要件:機能の選択やエンジニアリングのための十分な専門知識がある場合、機械学習は小規模なデータセットでも効果的に機能することがよくあります。一方、ディープラーニングの有用性は、複雑なデータセット内の複雑な関係を捉えることができる多層ニューラルネットワークを利用することにより、大量のラベル付きデータを活用して高精度の予測や意思決定タスクを実行する能力にあります。
機械学習モデルのユースケース
機械学習はさまざまな業界で利用され、さまざまな分野のイノベーションを実現しています。ヘルスケア業界では、機械学習を利用して医療画像や患者記録を分析し、病気の診断を支援しています。金融業界では、不正行為の検知や投資戦略の最適化に役立っています。小売企業や E コマース企業は、機械学習を使用しておすすめ商品の提案をパーソナライズしています。また、カスタマーサービス部門は、自然言語処理を活用したチャットボットや仮想アシスタントを利用し、ユーザー体験を強化しています。その他の一般的なユースケースには、自動運転(コンピュータービジョンが重要な役割を担う)や製造(予測メンテナンスモデルによって設備のアップタイムを確保する)などがあります。
API セキュリティにおいて ML が重要である理由
機械学習はさまざまなタイプのセキュリティ上の脅威の検知と防止に役立つため、API セキュリティにおいて重要なものです。機械学習システムは、より多くの入力でアルゴリズムを継続的に改善することで API セキュリティを強化し、より効率的に脅威を特定し緩和できるようにします。機械学習が API セキュリティにおいて重要である理由の一部として、次のことが挙げられます。
- 異常検知:機械学習アルゴリズムは、通常の API のふるまいからパターンを学習し、予想されるふるまいから逸脱する異常を特定できます。履歴データを分析することで、不正アクセスの試み、異常なデータ転送、異常な使用パターンなど、異常なアクティビティを検知できます。
- 侵入の検知:機械学習の手法を利用し、ネットワークトラフィックを監視して API に対する潜在的な悪性アクティビティや攻撃を特定する侵入検知システム(IDS)を構築できます。このようなモデルは、ネットワークパケットやログファイルから抽出された特徴量に基づいて攻撃パターンを認識できるようになります。
- 脅威インテリジェンス:機械学習アルゴリズムは、脅威インテリジェンスフィード、脆弱性データベース、ソーシャル・メディア・プラットフォームなどのさまざまなソースから取得した大量のデータを処理できます。この情報を継続的に分析することで、機械学習モデルは新たな脅威を特定し、それを検知機能に組み込むことができます。
- リアルタイムの応答:機械学習モデルを API セキュリティシステムと統合することにより、処理の大幅な遅延やサービスの可用性の低下を招くことなく、受信リクエストと応答を大規模にリアルタイムで監視できます。
API セキュリティソリューションにおいて機械学習を活用することで、組織は新たな脆弱性を検知する能力を強化し、進化する脅威に迅速に適応し、脅威検知プロセスのフォールス・ポジティブ(誤検知)や検知漏れを減らし、インシデント対応機能を向上させ、最終的に API を介して送信される機微な情報をより効果的に保護できます。
よくあるご質問
トレーニングデータは、機械学習モデルのトレーニングに使用されるラベル付きデータセットです。入力と出力のペアを含む例で構成されており、モデルはそれを使用してパターンを学習し、予測を行います。トレーニングデータの質と量は、新しいデータに対するモデルのパフォーマンスに直接影響するため、正確な機械学習モデルを構築する上で重要です。
一般的な機械学習モデルには、デシジョンツリー、線形回帰、ロジスティック回帰、サポート・ベクター・マシン(SVM)、ニューラルネットワークなどがあります。各モデルには、さまざまなタイプのタスクに適した固有の特性があります。例えば、デシジョンツリーは分類タスクによく使用され、ニューラルネットワークはコンピュータービジョンや NLP などのディープ・ラーニング・アプリケーションで使用されることが多くあります。
従来のプログラミングでは、特定のタスクを実行するためにプログラマーによる明示的な指示が必要です。一方、機械学習は、システムが事前定義されたルールに従うのではなく、データから学習し、データのパターンに基づいて予測や判断を行えるようにします。そのため、機械学習モデルは、より多くのデータを処理するほど、時間の経過とともにパフォーマンスを適応させ、改善することができます。
機械学習はデータサイエンスのコアコンポーネントであり、大規模なデータセットの分析、知見の発見、データに基づいた予測に必要なツールと手法を提供します。データサイエンティストは機械学習モデルを使用して、予測分析の構築、パターンの検知、意思決定の自動化を行い、組織がデータを活用して戦略的メリットを得られるようにします。
Akamai が選ばれる理由
Akamai は、オンラインビジネスの力となり、守るサイバーセキュリティおよびクラウドコンピューティング企業です。市場をリードするセキュリティソリューション、優れた脅威インテリジェンス、そして世界中の運用チームが、あらゆるところで企業のデータとアプリケーションを多層防御で守ります。Akamai のフルスタック・クラウドコンピューティング・ソリューションは、世界で最も分散されたプラットフォーム上で、パフォーマンスと手頃な価格を両立します。安心してビジネスを展開できる業界トップクラスの信頼性、スケール、専門知識の提供により、Akamai は、あらゆる業界のグローバル企業から信頼を獲得しています。


