
El aprendizaje automático desempeña un papel crucial en el procesamiento del lenguaje natural (NLP, del inglés "natural language processing") al permitir que los sistemas comprendan y generen el lenguaje humano. Se utiliza en aplicaciones como el análisis de la opinión, los chatbots, la traducción de idiomas y el resumen del texto. Los modelos de NLP analizan y aprenden patrones a partir de grandes volúmenes de datos de texto, lo que permite a las máquinas interpretar los matices del lenguaje humano y responder con precisión.
El aprendizaje automático es una rama de la IA que se centra en el desarrollo de algoritmos que pueden aprender de los datos y hacer predicciones o tomar decisiones basándose en ellos. En el aprendizaje automático, los modelos se entrenan con el uso de conjuntos de datos etiquetados para reconocer patrones o correlaciones dentro de los datos. A continuación, estos modelos utilizan estos patrones para hacer predicciones sobre datos nuevos y no vistos.
El aprendizaje automático (ML) es un campo de estudio de la inteligencia artificial que se centra en el desarrollo de algoritmos y modelos que permiten a los ordenadores aprender y hacer predicciones o tomar decisiones sin necesidad de programarlos explícitamente. Implica el entrenamiento de un sistema informático con una gran cantidad de datos, lo que le permite reconocer patrones, extraer información y hacer predicciones o tomar decisiones precisas.
En el aprendizaje automático, el ordenador aprende de la experiencia al analizar los datos históricos en lugar de seguir las reglas estrictas definidas por los humanos. El objetivo es desarrollar algoritmos que puedan mejorar automáticamente su rendimiento a medida que haya más datos disponibles. Disponer de datos suficientes es crucial para que los algoritmos de aprendizaje automático sean eficaces, ya que los sistemas requieren conjuntos de datos de entrenamiento grandes y precisos para evitar errores. Hay varios motivos por los que el aprendizaje automático es importante en el mundo actual.
Ventajas del aprendizaje automático
El aprendizaje automático ha revolucionado la forma en que interactuamos con la tecnología y ha abierto innumerables posibilidades en diversos sectores. Esta rama de la inteligencia artificial permite a los ordenadores aprender de los datos y hacer predicciones o tomar decisiones sin necesidad de programarlos explícitamente. Las ventajas del aprendizaje automático son numerosas y su impacto se puede observar en diferentes sectores.
Una de las principales ventajas del aprendizaje automático es su capacidad para gestionar grandes cantidades de datos complejos. Los métodos tradicionales tienen dificultades cuando se enfrentan a grandes conjuntos de datos que requieren análisis manuales. Por otro lado, los algoritmos de aprendizaje automático pueden procesar fácilmente grandes cantidades de información de forma rápida y precisa. Esto permite a las empresas descubrir información valiosa y patrones ocultos en los datos, lo que permite tomar decisiones más informadas.
Otra ventaja es la mejora de la eficiencia y la automatización. Los modelos de aprendizaje automático pueden automatizar tareas repetitivas que, de otro modo, serían laboriosas para los humanos. Mediante la automatización de estos procesos, las organizaciones pueden liberar a sus empleados para que se centren en tareas más importantes que requieren creatividad humana y habilidades de resolución de problemas.
El aprendizaje automático también permite a los usuarios disfrutar de experiencias personalizadas al aprovechar patrones de comportamiento o preferencias anteriores. Los sistemas de recomendación que utilizan plataformas como Amazon, Netflix o Spotify son ejemplos excelentes de este potencial de personalización. Estos sistemas analizan los datos de los usuarios, como el historial de navegación o los registros de compra, para sugerir productos o contenidos adaptados específicamente a los intereses de cada usuario.
Además de la personalización, el aprendizaje automático contribuye significativamente a la detección de fraudes y a los esfuerzos de ciberseguridad. Las instituciones financieras emplean algoritmos avanzados de detección de fraudes que analizan continuamente los patrones transaccionales en tiempo real para identificar cualquier actividad sospechosa con rapidez. Del mismo modo, los sistemas de seguridad basados en el aprendizaje automático pueden detectar ataques de malware y anomalías en patrones de tráfico de red mucho más rápido que los enfoques de seguridad tradicionales.
Además, el aprendizaje automático desempeña un papel crucial en aplicaciones sanitarias como el diagnóstico de enfermedades o la investigación de descubrimiento de fármacos. Mediante el análisis de registros médicos y datos genéticos de millones de pacientes en todo el mundo, los modelos de aprendizaje automático pueden ayudar a los médicos a realizar diagnósticos precisos basados en casos similares detectados anteriormente.
Por último, los análisis predictivos basados en el aprendizaje automático ayudan a las empresas a prever las tendencias futuras con precisión basándose en el análisis de datos históricos. Esto permite a las empresas anticiparse a las demandas de los clientes, optimizar los procesos de producción y tomar decisiones proactivas que mejoran la eficiencia operativa y aumentan la rentabilidad. Los algoritmos de aprendizaje automático pueden hacer predicciones de resultados futuros basándose en modelos desarrollados.
Tipos de aprendizaje automático
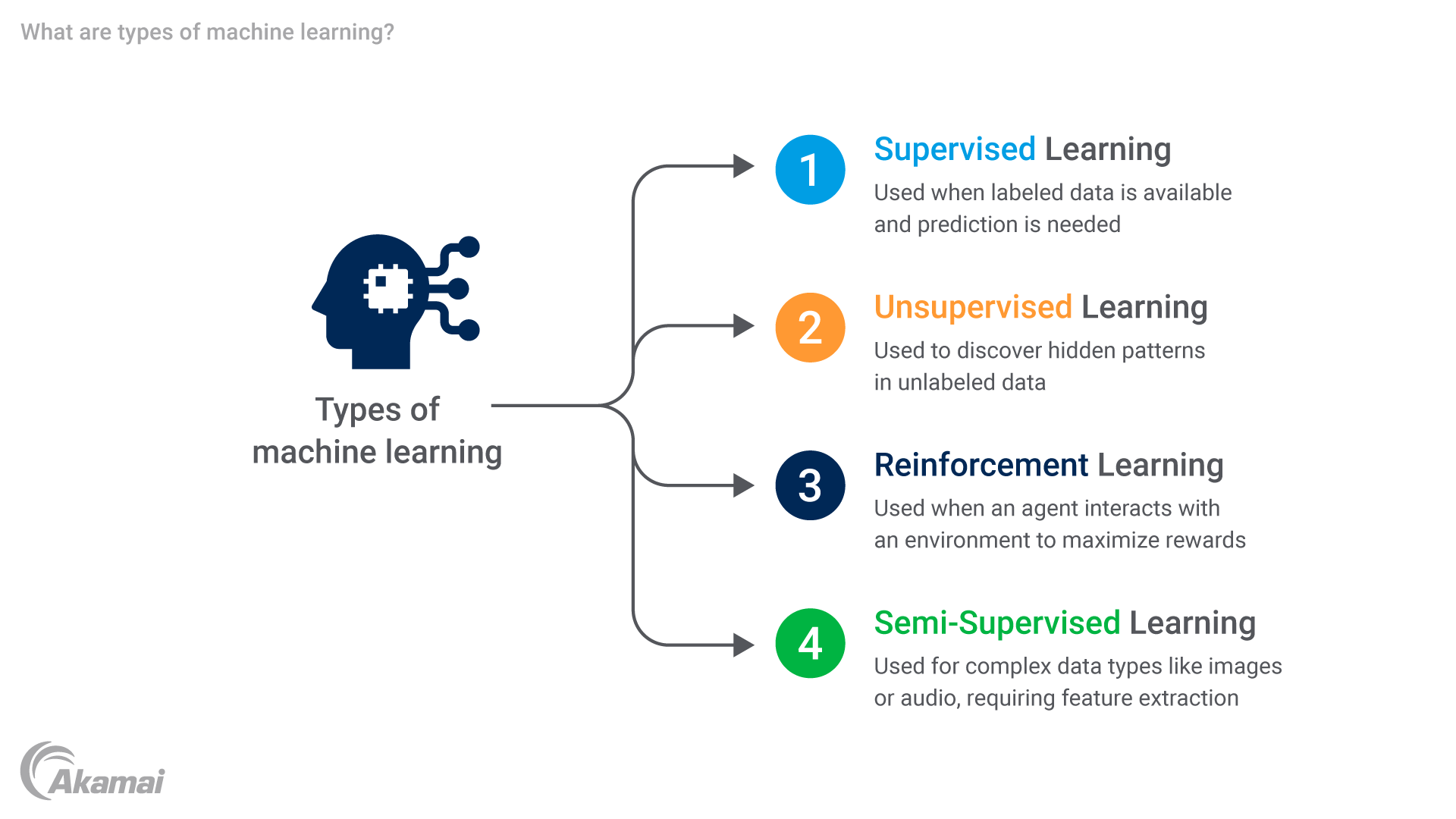
El aprendizaje automático abarca varias categorías que tienen diferentes propósitos y características únicas. Estos tipos de aprendizaje automático son el aprendizaje supervisado, el aprendizaje no supervisado, el aprendizaje de refuerzo y el aprendizaje semisupervisado. Echemos un vistazo a estas técnicas de aprendizaje con más detalle.
Aprendizaje supervisado: En este enfoque, el algoritmo de aprendizaje automático se entrena con ejemplos etiquetados en los que se proporcionan tanto entradas (características) como salidas deseadas (etiquetas). A continuación, el modelo generaliza a partir de estos ejemplos con el fin de predecir etiquetas para instancias de entrada nuevas y no vistas.
Aprendizaje no supervisado: En este caso, el algoritmo de aprendizaje automático explora los datos sin etiquetar sin salidas ni destinos predefinidos. Su objetivo es principalmente descubrir relaciones o estructuras ocultas dentro del conjunto de datos.
Aprendizaje de refuerzo: Esta técnica implica que un agente interactúe con un entorno y aprenda a tomar medidas para maximizar las recompensas o minimizar las sanciones. El agente aprende a través del proceso de prueba y error basándose en los comentarios recibidos del entorno.
Aprendizaje semisupervisado: Este enfoque de aprendizaje automático combina una pequeña cantidad de datos etiquetados con una gran cantidad de datos sin etiquetar durante el entrenamiento. Este método es especialmente útil cuando los datos etiquetados son escasos u obtenerlos resulta costoso, ya que aprovecha la abundancia de datos sin etiquetar para mejorar el rendimiento y la generalización del modelo.
Aprendizaje automático frente a aprendizaje profundo
El aprendizaje automático y el aprendizaje profundo son conceptos relacionados dentro de la inteligencia artificial, donde el aprendizaje profundo es un subconjunto del aprendizaje automático que utiliza redes neuronales con varias capas.
El aprendizaje automático es una rama de la IA que se centra en el desarrollo de algoritmos que pueden aprender de los datos y hacer predicciones o tomar decisiones basándose en ellos. En el aprendizaje automático, los modelos se entrenan con el uso de conjuntos de datos etiquetados para reconocer patrones o correlaciones dentro de los datos. A continuación, estos modelos utilizan estos patrones para hacer predicciones sobre datos nuevos y no vistos.
El aprendizaje profundo es un subconjunto del aprendizaje automático que se centra en el entrenamiento de redes neuronales artificiales con varias capas para aprender patrones y representaciones intrincados a partir de grandes cantidades de datos. Se inspira en la estructura y el funcionamiento del cerebro humano, donde la información fluye a través de neuronas interconectadas.
El término "profundo" en el concepto de "aprendizaje profundo" se refiere a la profundidad de estas redes neuronales, que se componen de varias capas ocultas entre las capas de entrada y de salida. Estas capas ocultas permiten a la red extraer características jerárquicas y representaciones abstractas a diferentes niveles, lo que permite comprender relaciones complejas dentro de los datos.
Los modelos de aprendizaje profundo se suelen entrenar con grandes cantidades de datos etiquetados. El proceso implica la introducción de datos de entrada en la capa inicial de la red, pasarlos a través de varias capas intermedias (también denominadas capas ocultas) y, finalmente, generar una predicción de salida desde la última capa. Durante el entrenamiento, estos modelos ajustan sus parámetros internos de forma iterativa mediante algoritmos de optimización como el descenso de gradientes para minimizar los errores o maximizar el rendimiento.
A continuación, se muestran algunas de las principales diferencias entre los dos modelos:
- Representación: Tradicionalmente, el aprendizaje automático requiere que los ingenieros diseñen manualmente las características como entradas para los algoritmos. Por el contrario, los modelos de aprendizaje profundo pueden extraer automáticamente representaciones jerárquicas de los datos de entrada sin procesar.
- Complejidad: Los modelos de aprendizaje profundo tienden a ser más complejos que los modelos de aprendizaje automático tradicionales debido a sus múltiples capas y al gran número de parámetros.
- Requisitos de datos: El aprendizaje automático a menudo funciona bien con conjuntos de datos más pequeños en los que hay suficiente conocimiento del dominio para la selección de características y la ingeniería. Por otro lado, el potencial del aprendizaje profundo reside en su capacidad de aprovechar grandes cantidades de datos etiquetados para hacer predicciones o realizar tareas de toma de decisiones de gran precisión mediante el uso de redes neuronales multicapa capaces de capturar relaciones complejas dentro de conjuntos de datos complejos.
Casos de uso del modelo de aprendizaje automático
El aprendizaje automático se aplica a una amplia gama de sectores, lo que permite innovaciones en diversos campos. En el sector sanitario, el aprendizaje automático ayuda a diagnosticar enfermedades mediante el análisis de imágenes médicas y registros de pacientes. En el sector financiero, ayuda a detectar el fraude y a optimizar las estrategias de inversión. Las empresas de comercio minorista y comercio electrónico utilizan el aprendizaje automático para obtener recomendaciones personalizadas, mientras que los departamentos de atención al cliente utilizan chatbots y asistentes virtuales basados en el procesamiento del lenguaje natural para mejorar las experiencias de los usuarios. Otros casos de uso comunes incluyen la conducción autónoma, donde la visión artificial desempeña un papel importante, y la fabricación, donde los modelos de mantenimiento predictivo garantizan el tiempo de actividad del equipo.
¿Por qué es importante el ML para la seguridad de API?
El aprendizaje automático es importante para la seguridad de API, ya que puede ayudar a detectar y prevenir diversos tipos de amenazas a la seguridad. Un sistema de aprendizaje automático mejora la seguridad de API mejorando continuamente sus algoritmos con más entradas, lo que hace que sea más eficiente a la hora de identificar y mitigar las amenazas. A continuación, se muestran algunos motivos por los que el aprendizaje automático es relevante en el contexto de la seguridad de API:
- Detección de anomalías. Los algoritmos de aprendizaje automático pueden aprender patrones del comportamiento normal de las API e identificar anomalías que se desvían del comportamiento esperado. Al analizar los datos históricos, pueden detectar actividades inusuales, como intentos de acceso no autorizados, transmisión de datos anómala o patrones de uso inusuales.
- Detección de intrusiones. Las técnicas de aprendizaje automático se pueden utilizar para crear sistemas de detección de intrusiones (IDS) que supervisen el tráfico de red e identifiquen posibles actividades maliciosas o ataques a las API. Estos modelos pueden aprender a reconocer patrones de ataque basados en características extraídas de los paquetes de red y los archivos de registro.
- Inteligencia contra ciberamenazas. Los algoritmos de aprendizaje automático pueden procesar grandes cantidades de datos de diversas fuentes, incluidas fuentes de inteligencia contra ciberamenazas, bases de datos de vulnerabilidades y plataformas de redes sociales. Mediante el análisis continuo de esta información, los modelos de aprendizaje automático pueden identificar amenazas emergentes e incorporarlas a sus capacidades de detección.
- Respuesta a incidentes en tiempo real. Los modelos de aprendizaje automático integrados con los sistemas de seguridad de API permiten la supervisión en tiempo real de las solicitudes y respuestas entrantes a escala sin crear retrasos de procesamiento significativos ni interrumpir la disponibilidad del servicio.
Al aprovechar el aprendizaje automático en las soluciones de seguridad de API, las organizaciones pueden mejorar su capacidad para detectar nuevas vulnerabilidades, adaptarse rápidamente a las amenazas en evolución, reducir los falsos positivos/negativos en los procesos de detección de amenazas, mejorar las capacidades de respuesta a incidentes y, en última instancia, proteger los datos confidenciales que se transmiten a través de sus API de forma más eficaz.
Preguntas frecuentes
Los datos de entrenamiento son el conjunto de datos etiquetados que se utiliza para entrenar modelos de aprendizaje automático. Consta de ejemplos con pares de entrada-salida que el modelo utiliza para aprender patrones y hacer predicciones. La calidad y cantidad de los datos de entrenamiento son esenciales para crear modelos de aprendizaje automático precisos, ya que influyen directamente en el rendimiento del modelo en los nuevos datos.
Los modelos de aprendizaje automático comunes incluyen árboles de decisión, regresión lineal, regresión logística, máquinas de vectores de soporte (SVM) y redes neuronales. Cada modelo tiene características únicas adaptadas a diferentes tipos de tareas. Por ejemplo, los árboles de decisión se utilizan a menudo para las tareas de clasificación, mientras que las redes neuronales son populares en aplicaciones de aprendizaje profundo, como la visión artificial y el NLP.
La programación tradicional se basa en instrucciones explícitas dadas por los programadores para realizar tareas específicas. Por el contrario, el aprendizaje automático permite a los sistemas aprender de los datos para hacer predicciones o tomar decisiones basadas en patrones en función de esos datos, en lugar de seguir reglas predefinidas. Esto permite a los modelos de aprendizaje automático adaptar y mejorar su rendimiento a lo largo del tiempo a medida que procesan más datos.
El aprendizaje automático es un componente fundamental de la ciencia de datos, y proporciona las herramientas y técnicas necesarias para analizar grandes conjuntos de datos, descubrir información y hacer predicciones basadas en datos. Los científicos de datos utilizan modelos de aprendizaje automático para crear análisis predictivos, detectar patrones y automatizar la toma de decisiones, lo que permite a las organizaciones aprovechar sus datos para obtener beneficios estratégicos.
Por qué los clientes eligen Akamai
Akamai es la empresa de ciberseguridad y cloud computing que potencia y protege los negocios online. Nuestras soluciones de seguridad líderes en el mercado, nuestra inteligencia ante amenazas consolidada y nuestro equipo de operaciones globales proporcionan una defensa en profundidad para proteger los datos y las aplicaciones empresariales. Las soluciones integrales de cloud computing de Akamai garantizan el rendimiento y una buena relación calidad-precio en la plataforma más distribuida del mundo. Las grandes empresas confían en Akamai, ya que les ofrece una fiabilidad, una escalabilidad y una experiencia inigualables en el sector, idóneas para crecer con seguridad.


