
L'apprendimento automatico svolge un ruolo cruciale nell'elaborazione del linguaggio naturale (NLP) consentendo ai sistemi di comprendere e generare il linguaggio umano. Inoltre, viene utilizzato in applicazioni come l'analisi del sentiment, i chatbot, la traduzione linguistica e il riassunto di testi. I modelli NLP analizzano e apprendono i modelli da grandi volumi di dati di testo, consentendo ai computer di interpretare le sfumature del linguaggio umano e rispondere in modo accurato.
L'apprendimento automatico è una branca dell'AI che si concentra sullo sviluppo di algoritmi in grado di imparare e fare previsioni o prendere decisioni basate sui dati. Nell'apprendimento automatico, i modelli vengono addestrati utilizzando dataset etichettati in modo da riconoscere modelli o correlazioni al loro interno. Questi modelli, quindi, utilizzano tali schemi per fare previsioni su dati nuovi e non visionati preventivamente.
L'apprendimento automatico (ML) è un settore di studio dell'intelligenza artificiale incentrato sullo sviluppo di algoritmi e modelli che consentono ai computer di apprendere e fare previsioni o prendere decisioni senza essere esplicitamente programmati. L'apprendimento automatico richiede l'addestramento di un sistema informatico con una grande quantità di dati per poter riconoscere i modelli, ottenere informazioni dettagliate e fare previsioni o prendere decisioni accurate.
Nell'apprendimento automatico, il computer apprende dall'esperienza analizzando i dati cronologici invece di seguire rigide regole definite dall'uomo. L'obiettivo è sviluppare algoritmi in grado di migliorare automaticamente le loro performance man mano che diventano disponibili più dati. Disporre di dati sufficienti è fondamentale per ottenere algoritmi di apprendimento automatico efficaci poiché i sistemi richiedono vasti dataset di addestramento accurati per evitare errori. Sono diversi i motivi per cui attualmente l'apprendimento automatico è importante.
Vantaggi dell'apprendimento automatico
L'apprendimento automatico ha rivoluzionato il nostro modo di interagire con la tecnologia e ha aperto innumerevoli possibilità in vari settori. Questo ramo dell'intelligenza artificiale consente ai computer di apprendere dai dati e di fare previsioni o prendere decisioni senza essere esplicitamente programmati. I vantaggi dell'apprendimento automatico sono numerosi e il suo impatto è visibile in diversi settori.
Uno dei principali vantaggi dell'apprendimento automatico è la sua capacità di gestire grandi quantità di dati complessi. I metodi tradizionali faticano quando devono affrontare enormi dataset che richiedono un'analisi manuale. Gli algoritmi di apprendimento automatico, d'altro canto, possono elaborare facilmente grandi quantità di informazioni in modo rapido e accurato. Ciò consente alle aziende di scoprire importanti informazioni e modelli nascosti all'interno dei dati, il che porta ad un processo decisionale più informato.
Un altro vantaggio è rappresentato dal miglioramento dell'efficienza e dell'automazione. I modelli di apprendimento automatico possono automatizzare le attività ripetitive che altrimenti sarebbero dispendiose in termini di tempo per l'uomo. Automatizzando questi processi, le organizzazioni possono alleggerire il carico di lavoro che grava sui dipendenti per farli concentrare su attività più importanti che richiedono creatività umana e competenze di risoluzione dei problemi.
L'apprendimento automatico consente, inoltre, agli utenti di offrire experience personalizzate sfruttando i modelli di comportamento o le preferenze precedenti. I sistemi di recensione utilizzati da piattaforme come Amazon, Netflix o Spotify sono i principali esempi di questa potenza della personalizzazione. Questi sistemi analizzano i dati degli utenti, come la cronologia di navigazione o i dati relativi agli acquisti, per suggerire prodotti o contenuti personalizzati in base agli interessi di ogni singolo utente.
Oltre alla personalizzazione, l'apprendimento automatico contribuisce in modo significativo al rilevamento delle frodi e alle attività di cybersecurity. Le istituzioni finanziarie utilizzano avanzati algoritmi di rilevamento delle frodi che analizzano continuamente i modelli delle transazioni in tempo reale per identificare tempestivamente eventuali attività sospette. Analogamente, i sistemi di sicurezza basati sull'apprendimento automatico possono rilevare attacchi malware e anomalie nei modelli del traffico di rete molto più rapidamente rispetto ai tradizionali approcci alla sicurezza.
Inoltre, l'apprendimento automatico svolge un ruolo cruciale nelle applicazioni sanitarie, come la diagnosi delle malattie o la ricerca di nuovi farmaci. Analizzando le cartelle cliniche e i dati genetici di milioni di pazienti in tutto il mondo, i modelli di apprendimento automatico possono aiutare i medici ac effettuare diagnosi accurate sulla base di casi simili riscontrati in precedenza.
Infine, l'analisi predittiva basata sull'apprendimento automatico aiuta le aziende a prevedere accuratamente le tendenze future in base all'analisi dei dati cronologici. Ciò consente alle aziende di anticipare le richieste dei clienti, ottimizzare i processi di produzione e prendere decisioni proattive che portano ad una migliore efficienza operativa e ad una maggiore redditività. Gli algoritmi di apprendimento automatico possono fare previsioni sui risultati futuri in base ai modelli sviluppati.
Tipi di apprendimento automatico
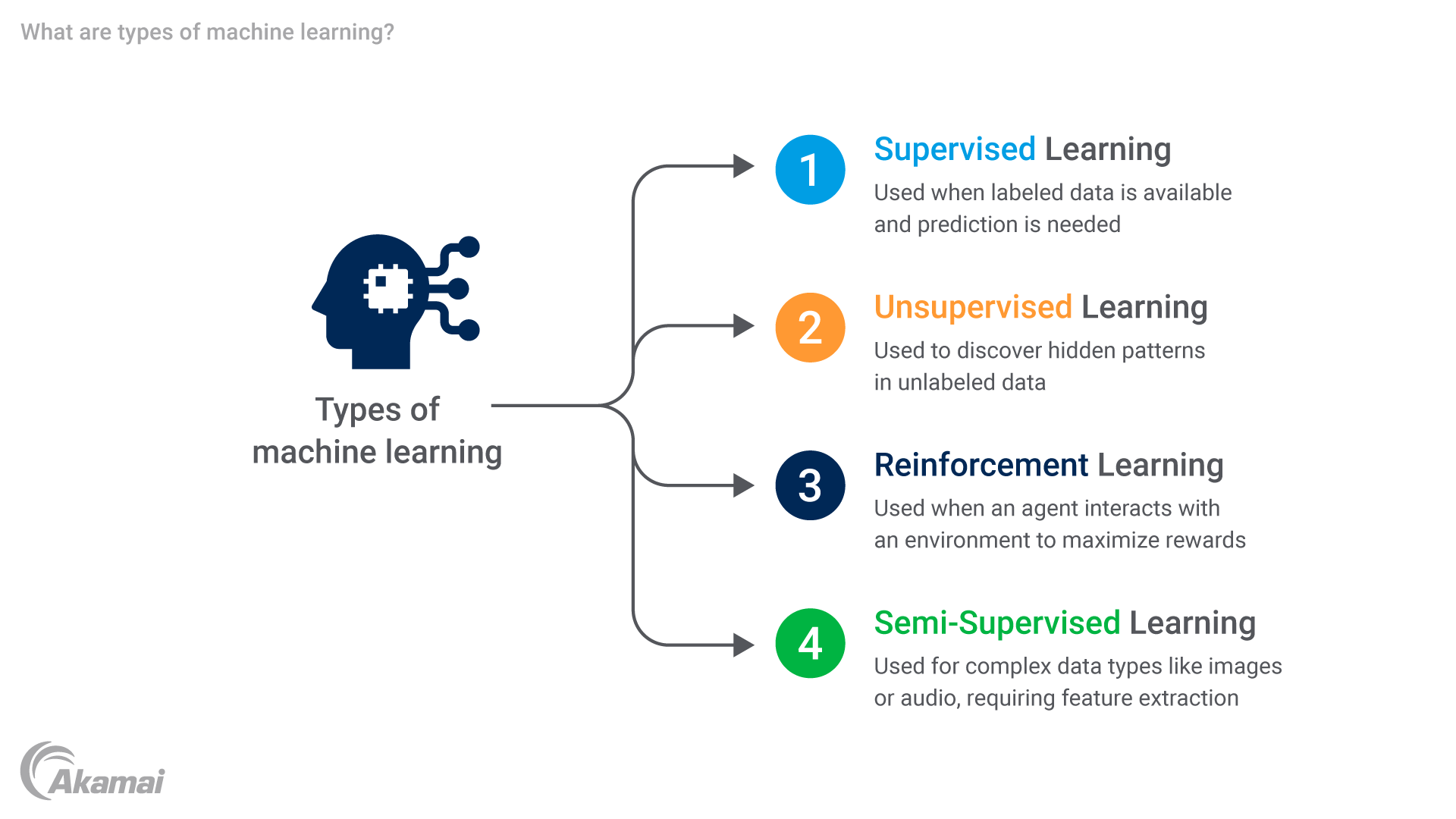
L'apprendimento automatico comprende diverse categorie che hanno scopi diversi e caratteristiche esclusive. I vari tipi di apprendimento automatico sono: l'apprendimento supervisionato, l'apprendimento non supervisionato, l'apprendimento per rinforzo e l'apprendimento semi-supervisionato. Esaminiamo queste tecniche di apprendimento in modo più dettagliato.
Apprendimento supervisionato: in questo approccio, l'algoritmo di apprendimento automatico viene addestrato utilizzando esempi etichettati in cui vengono forniti sia gli input (funzioni) che gli output desiderati (etichette). Il modello quindi si generalizza da questi esempi per prevedere le etichette per le nuove istanze di input non visionate preventivamente.
Apprendimento non supervisionato: in questo caso, l'algoritmo di apprendimento automatico esamina i dati non etichettati senza output né obiettivi predefiniti. Il suo obiettivo è principalmente quello di scoprire le relazioni o le strutture nascoste all'interno del dataset.
Apprendimento per rinforzo: questa tecnica prevede l'interazione di un agente con un ambiente e l'apprendimento delle azioni necessarie per massimizzare i premi o ridurre al minimo le sanzioni. L'agente apprende tramite tentativi ed errori in base al feedback ricevuto dall'ambiente.
Apprendimento semi-supervisionato: questo approccio all'apprendimento automatico combina una piccola quantità di dati etichettati con una grande quantità di dati non etichettati durante l'addestramento. Questo metodo è particolarmente utile quando i dati etichettati sono scarsi o costosi da acquisire perché sfrutta l'elevato numero di dati non etichettati per migliorare le performance e la generalizzabilità del modello.
Confronto tra apprendimento automatico e apprendimento profondo
L'apprendimento automatico e l'apprendimento profondo sono concetti correlati all'interno dell'intelligenza artificiale, in cui l'apprendimento profondo è un sottoinsieme dell'apprendimento automatico che utilizza reti neurali a più livelli.
L'apprendimento automatico è una branca dell'AI che si concentra sullo sviluppo di algoritmi in grado di imparare e fare previsioni o prendere decisioni basate sui dati. Nell'apprendimento automatico, i modelli vengono addestrati utilizzando dataset etichettati in modo da riconoscere modelli o correlazioni all'interno dei dati. Questi modelli, quindi, utilizzano tali schemi per fare previsioni su dati nuovi e non visionati preventivamente.
L'apprendimento profondo è un sottoinsieme dell'apprendimento automatico che si concentra sull'addestramento di reti neurali artificiali con più livelli per apprendere schemi e rappresentazioni complessi da grandi quantità di dati. Si ispira alla struttura e al funzionamento del cervello umano, in cui le informazioni fluiscono attraverso i neuroni interconnessi.
Il termine "profondo" si riferisce alla profondità di queste reti neurali, che sono composte da più livelli nascosti tra i livelli di input e output. Questi livelli nascosti consentono alla rete di estrarre funzioni gerarchiche e di astrarre rappresentazioni a diversi livelli, consentendole di comprendere le relazioni complesse all'interno dei dati.
I modelli di apprendimento profondo sono, in genere, formati utilizzando grandi quantità di dati etichettati. Il processo prevede l'inserimento dei dati di input nel livello iniziale della rete, il loro passaggio attraverso diversi livelli intermedi (detti anche livelli nascosti) e, infine, la generazione di una previsione di output dall'ultimo livello. Durante l'addestramento, questi modelli regolano i parametri interni in modo iterativo utilizzando algoritmi di ottimizzazione come la discesa del gradiente per ridurre al minimo gli errori o massimizzare le performance.
Tra le principali differenze tra i due modelli, figurano:
- Rappresentazione: tradizionalmente, l'apprendimento automatico richiede ai tecnici di progettare manualmente le varie funzioni come input per gli algoritmi. Al contrario, i modelli di apprendimento profondo possono estrarre automaticamente le rappresentazioni gerarchiche dai dati di input non elaborati.
- Complessità: i modelli di apprendimento profondo tendono ad essere più complessi rispetto ai modelli di apprendimento automatico tradizionali a causa dei loro molteplici livelli e dell'elevato numero di parametri.
- Requisiti dei dati: l'apprendimento automatico spesso funziona bene con dataset più piccoli in cui esiste una conoscenza sufficiente del dominio per la selezione e la progettazione delle funzioni. D'altra parte, la potenza dell'apprendimento approfondito risiede nella sua capacità di sfruttare enormi quantità di dati etichettati per eseguire previsioni o prendere decisioni altamente accurate utilizzando reti neurali multilivello in grado di acquisire relazioni complicate all'interno di dataset complessi.
Casi di utilizzo del modello di apprendimento automatico
L'apprendimento automatico viene applicato in un'ampia gamma di settori, consentendo innovazioni in vari campi. Nel settore sanitario, l'apprendimento automatico aiuta a diagnosticare le malattie analizzando le immagini mediche e le cartelle cliniche dei pazienti. Nel settore finanziario, aiuta a rilevare le frodi e ad ottimizzare le strategie di investimento. Le società di e-commerce e i retailer utilizzano l'apprendimento automatico per fornire consigli personalizzati, mentre i reparti di assistenza clienti sfruttano chatbot e assistenti virtuali basati sull'elaborazione del linguaggio naturale per migliorare le user experience. Altri casi di utilizzo comuni includono la guida autonoma, in cui la visione artificiale svolge un ruolo significativo, e la produzione, in cui i modelli di manutenzione predittiva garantiscono i tempi di attività delle apparecchiature.
Perché l'ML è importante per la sicurezza delle API
L'apprendimento automatico è importante per la sicurezza delle API perché può aiutare a rilevare e prevenire vari tipi di minacce alla sicurezza. Un sistema di apprendimento automatico migliora la sicurezza delle API migliorando continuamente i suoi algoritmi con più input, rendendolo più efficiente nell'identificazione e nella mitigazione delle minacce. Ecco alcuni motivi per cui l'apprendimento automatico è rilevante nel contesto della sicurezza delle API:
- Rilevamento delle anomalie. Gli algoritmi di apprendimento automatico possono imparare i modelli dal normale comportamento delle API e identificare le anomalie che si discostano dal comportamento previsto. Analizzando i dati cronologici, questi algoritmi possono rilevare attività insolite, come tentativi di accesso non autorizzati, trasmissioni di dati anomale o modelli di utilizzo insoliti.
- Rilevamento delle intrusioni. Le tecniche di apprendimento automatico possono essere utilizzate per creare sistemi di rilevamento delle intrusioni (IDS) che monitorano il traffico di rete e identificano potenziali attività dannose o attacchi alle API. Questi modelli possono imparare a riconoscere i modelli di attacco in base alle funzioni ricavate dai pacchetti di rete e dai file di registro.
- Intelligence sulle minacce. Gli algoritmi di apprendimento automatico possono elaborare grandi quantità di dati provenienti da varie fonti, tra cui feed di intelligence sulle minacce, database di vulnerabilità e piattaforme di social media. Analizzando continuamente queste informazioni, i modelli di apprendimento automatico possono identificare le minacce emergenti e integrarle nelle loro funzionalità di rilevamento.
- Risposta in tempo reale. I modelli di apprendimento automatico integrati con i sistemi di sicurezza delle API consentono di monitorare in tempo reale le richieste e le risposte in entrata su larga scala, senza creare significativi ritardi di elaborazione o interrompere la disponibilità del servizio.
Sfruttando l'apprendimento automatico nelle soluzioni per la sicurezza delle API, le organizzazioni possono migliorare la loro capacità di rilevare nuove vulnerabilità, adattarsi rapidamente alle minacce in continua evoluzione, ridurre i falsi positivi/negativi nei processi di rilevamento delle minacce, migliorare le funzionalità di risposta agli incidenti e, infine, proteggere i dati sensibili trasmessi tramite le API in modo più efficace.
Domande frequenti
I dati di addestramento sono i dataset etichettati che vengono utilizzati per addestrare i modelli di apprendimento automatico. Sono costituiti da esempi con coppie di input/output che il modello utilizza per apprendere i modelli e fare previsioni. La qualità e la quantità dei dati di addestramento sono essenziali per creare modelli di apprendimento automatico accurati perché influiscono direttamente sulle performance del modello sui nuovi dati.
Tra i più comuni modelli di apprendimento automatico, figurano schemi decisionali, regressione lineare, regressione logistica, sistemi SVM (Support Vector Machine) e reti neurali. Ogni modello presenta caratteristiche esclusive che risultano adatte a diversi tipi di attività. Ad esempio, gli schemi decisionali vengono spesso utilizzati per le attività di classificazione, mentre le reti neurali sono comuni nelle applicazioni di apprendimento profondo, tra cui la visione artificiale e l'NPL.
La programmazione tradizionale si basa su istruzioni esplicite fornite dai programmatori per eseguire attività specifiche. Al contrario, l'apprendimento automatico consente ai sistemi di apprendere dai dati, facendo previsioni o prendendo decisioni in base ai modelli presenti in tali dati anziché seguire regole predefinite. Ciò consente ai modelli di apprendimento automatico di adattarsi e migliorare le loro performance nel tempo man mano che elaborano più dati.
L'apprendimento automatico è un componente fondamentale della data science perché fornisce le tecniche e gli strumenti necessari per analizzare grandi dataset, scoprire informazioni e fare previsioni basate sui dati. Gli analisti di dati utilizzano i modelli di apprendimento automatico per creare analisi predittive, rilevare modelli e automatizzare i processi decisionali, consentendo alle organizzazioni di sfruttare i propri dati per ottenere vantaggi strategici.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.


