
O aprendizado de máquina desempenha um papel crucial no processamento de linguagem natural, permitindo que os sistemas entendam e gerem linguagem humana. Ele é usado em aplicações como análise de sentimentos, chatbots, tradução de idiomas e resumo de textos. Os modelos de PLN analisam e aprendem padrões a partir de grandes volumes de dados de texto para que as máquinas interpretem nuances da linguagem humana e respondam com precisão.
O aprendizado de máquina é um ramo da IA que se concentra no desenvolvimento de algoritmos que podem aprender e fazer previsões ou tomar decisões com base em dados. No aprendizado de máquina, os modelos são treinados usando conjuntos de dados rotulados para reconhecer padrões ou correlações entre os dados. Em seguida, usam esses padrões para fazer previsões sobre dados novos e nunca antes vistos.
O aprendizado de máquina é um campo de estudo em inteligência artificial que se concentra no desenvolvimento de algoritmos e modelos que permitem que os computadores aprendam e façam previsões ou tomem decisões sem serem explicitamente programados. Isso envolve treinar um sistema de computador com uma grande quantidade de dados para que ele reconheça padrões, obtenha insights e faça previsões ou tome decisões precisas.
No aprendizado de máquina, o computador aprende com a experiência, analisando dados históricos em vez de seguir regras rígidas definidas por humanos. O objetivo é desenvolver algoritmos que possam melhorar automaticamente seu desempenho à medida que mais dados são disponibilizados. A eficácia dos algoritmos depende da obtenção de dados suficientes, pois os sistemas exigem conjuntos de dados de treinamento grandes e precisos para evitar erros. Há vários motivos pelos quais o aprendizado de máquina é importante no mundo atual.
Vantagens do aprendizado de máquina
O aprendizado de máquina revolucionou a maneira como interagimos com a tecnologia e abriu inúmeras possibilidades em vários setores. Esse ramo da inteligência artificial permite que os computadores aprendam com dados e façam previsões ou tomem decisões sem serem explicitamente programados. As vantagens são inúmeras e seu impacto pode ser visto em diferentes setores.
Uma grande vantagem do aprendizado de máquina é sua capacidade de lidar com grandes quantidades de dados complexos. Os métodos tradicionais enfrentam dificuldades ao se deparar com grandes conjuntos de dados que exigem análise manual. Os algoritmos de aprendizado de máquina, por outro lado, podem processar facilmente grandes quantidades de informações com rapidez e precisão. Isso possibilita que as empresas descubram insights e padrões valiosos que estavam ocultos nos dados, levando a uma tomada de decisões mais informada.
Outra vantagem é a melhoria da eficiência e da automação. Os modelos de aprendizado de máquina podem automatizar tarefas repetitivas que, de outra forma, seriam demoradas para humanos. Ao automatizar esses processos, as organizações podem liberar sua força de trabalho para se concentrar em tarefas mais críticas que exigem a criatividade e as habilidades de resolução de problemas que os humanos possuem.
O aprendizado de máquina também permite experiências personalizadas para os usuários, aproveitando padrões ou preferências de comportamento anteriores. Os sistemas de recomendação usados por plataformas como Amazon, Netflix ou Spotify são alguns dos principais exemplos desse poder de personalização. Esses sistemas analisam dados dos usuários, como o histórico de navegação ou registros de compras, para sugerir produtos ou conteúdo adaptados especificamente aos interesses de cada usuário individual.
Além da personalização, o aprendizado de máquina contribui significativamente para os esforços de detecção de fraudes e cibersegurança. As instituições financeiras empregam algoritmos avançados de detecção de fraudes que analisam continuamente os padrões transacionais em tempo real para identificar qualquer atividade suspeita imediatamente. Da mesma forma, os sistemas de segurança baseados em aprendizado de máquina podem detectar ataques de malware e anomalias nos padrões de tráfego de rede de forma muito mais veloz do que as abordagens de segurança tradicionais.
Além disso, o aprendizado de máquina desempenha um papel crucial em aplicações de saúde, como diagnóstico de doenças ou pesquisa de descoberta de medicamentos. Ao analisar registros médicos e dados genéticos de milhões de pacientes em todo o mundo, os modelos de aprendizado de máquina podem ajudar os médicos a fazer diagnósticos precisos com base em casos semelhantes encontrados anteriormente.
Por fim, a análise preditiva baseada em aprendizado de máquina ajuda as empresas a prever tendências futuras de forma precisa com base na análise de dados históricos. Isso permite que as empresas antecipem as demandas dos clientes, otimizem os processos de produção e tomem decisões proativas que levam a uma melhor eficiência operacional e maior lucratividade. Os algoritmos de aprendizado de máquina podem fazer previsões de resultados futuros com base nos modelos desenvolvidos.
Tipos de aprendizado de máquina
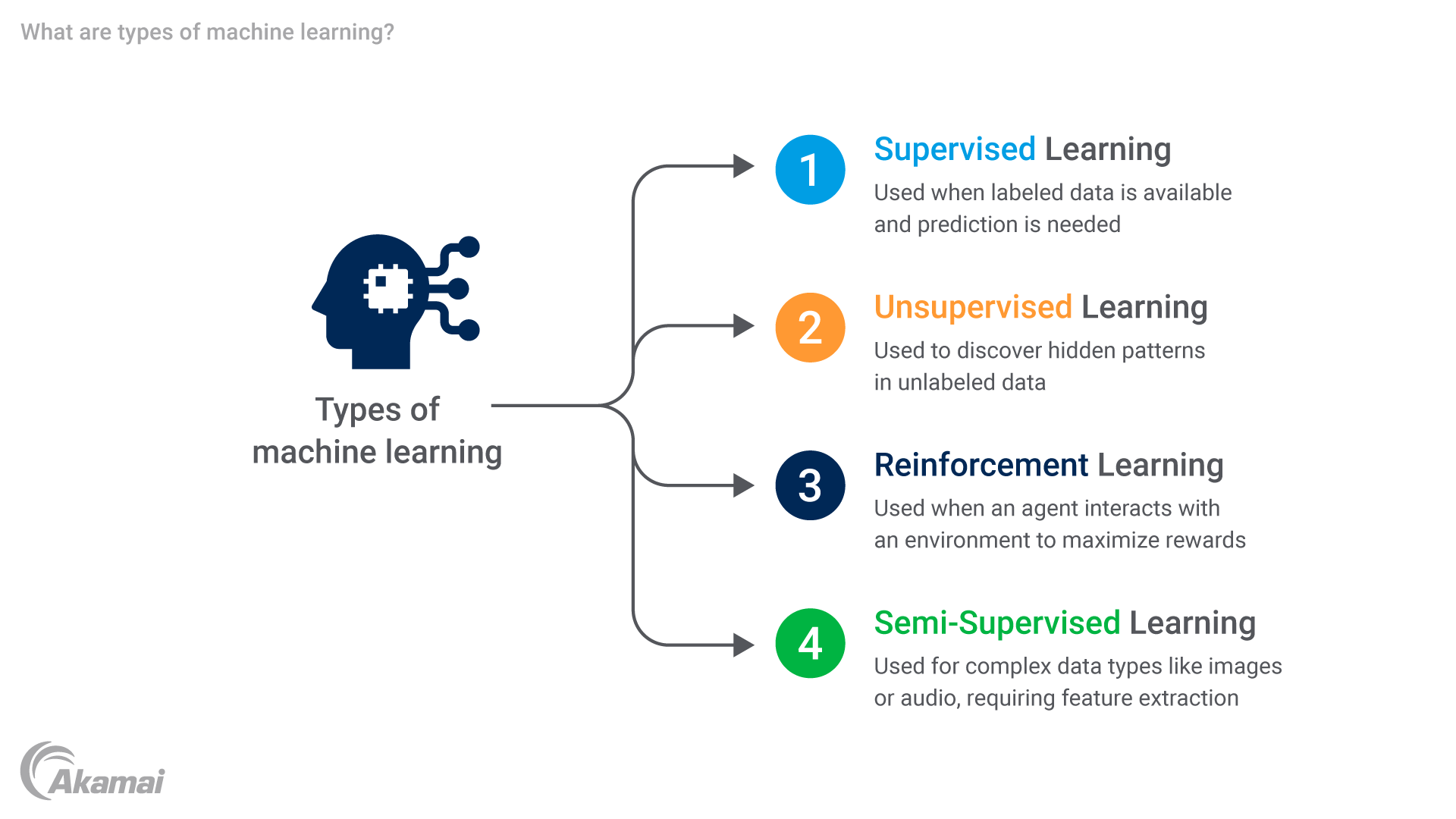
O aprendizado de máquina abrange várias categorias com diferentes finalidades e têm características exclusivas. São quatro tipos de aprendizado: supervisionado, não supervisionado, por reforço e semissupervisionado. Vamos explorar essas técnicas de aprendizado em mais detalhes.
Aprendizado supervisionado: nessa abordagem, o algoritmo do aprendizado de máquina é treinado usando exemplos rotulados em que entradas (recursos) e saídas desejadas (rótulos) são fornecidas. Em seguida, o modelo generaliza a partir desses exemplos para prever rótulos para instâncias de entrada novas e que nunca foram vistas antes.
Aprendizado não supervisionado: aqui, o algoritmo do aprendizado de máquina explora dados não rotulados sem saídas ou alvos predefinidos. O objetivo é principalmente descobrir relacionamentos ou estruturas ocultos dentro do conjunto de dados.
Aprendizado de reforço: essa técnica envolve a interação de um agente com um ambiente, aprendendo a tomar medidas para maximizar recompensas ou minimizar penalidades. O agente aprende por tentativa e erro com base no feedback recebido do ambiente.
Aprendizado semissupervisionado: essa abordagem de aprendizado de máquina combina uma pequena quantidade de dados rotulados com uma grande quantidade de dados não rotulados durante o treinamento. Esse método é particularmente útil quando os dados rotulados são escassos ou caros de obter, pois aproveita a abundância de dados não rotulados para melhorar o desempenho do modelo e a generalização.
Aprendizado de máquina versus aprendizado profundo
Ambos são conceitos relacionados à inteligência artificial, e o aprendizado profundo é um subconjunto do aprendizado de máquina que usa redes neurais com várias camadas.
O aprendizado de máquina é um ramo da IA que se concentra no desenvolvimento de algoritmos que podem aprender e fazer previsões ou tomar decisões com base em dados. No aprendizado de máquina, os modelos são treinados usando conjuntos de dados rotulados para reconhecer padrões ou correlações entre os dados. Em seguida, usam esses padrões para fazer previsões sobre dados novos e nunca antes vistos.
O aprendizado profundo é um subconjunto do aprendizado de máquina que se concentra no treinamento de redes neurais artificiais com várias camadas para aprender padrões complexos e representações de grandes quantidades de dados. É inspirado na estrutura e no funcionamento do cérebro humano, onde a informação flui através de neurônios interconectados.
O termo "profundo" refere-se à profundidade dessas redes neurais, que são compostas de várias camadas ocultas entre as camadas de entrada e saída. Elas permitem que a rede extraia recursos hierárquicos e representações abstratas em diferentes níveis para entender relações complexas nos dados.
Os modelos de aprendizado profundo são normalmente treinados com o uso de grandes quantidades de dados rotulados. O processo envolve a alimentação de dados de entrada na camada inicial da rede, passando-os por várias camadas intermediárias (também chamadas de camadas ocultas), produzindo uma previsão de saída a partir da última camada. Durante o treinamento, esses modelos ajustam seus parâmetros internos iterativamente usando algoritmos de otimização, como o método do gradiente, para minimizar erros ou maximizar o desempenho.
Estas são algumas das principais diferenças entre os dois:
- Representação: tradicionalmente, o aprendizado de máquina exige que os engenheiros projetem recursos manualmente como entradas para os algoritmos. Em contraste, os modelos de aprendizado profundo podem extrair automaticamente representações hierárquicas a partir dos dados brutos de entrada.
- Complexidade: os modelos de aprendizado profundo tendem a ser mais complexos do que os modelos tradicionais de aprendizado de máquina devido às suas várias camadas e ao grande número de parâmetros.
- Requisitos de dados: o aprendizado de máquina geralmente funciona bem com conjuntos de dados menores, em que há conhecimento de domínio suficiente para seleção de recursos e engenharia. Por outro lado, o poder do aprendizado profundo está em sua capacidade de aproveitar grandes quantidades de dados rotulados para fazer previsões altamente precisas ou realizar tarefas de tomada de decisão, utilizando redes neurais multicamada capazes de capturar relações intrincadas em conjuntos de dados complexos.
Casos de uso do modelo de aprendizado de máquina
O aprendizado de máquina é aplicado em muitos setores, permitindo inovações em vários campos. Na área da saúde, ele ajuda no diagnóstico de doenças analisando imagens e prontuários médicos. No setor financeiro, ajuda a detectar fraudes e a otimizar estratégias de investimento. As empresas de varejo e comércio eletrônico usam o aprendizado de máquina para recomendações personalizadas, enquanto os departamentos de atendimento ao cliente utilizam chatbots e assistentes virtuais alimentados por processamento de linguagem natural para aprimorar as experiências do usuário. Entre os outros casos de uso comuns estão direção autônoma, em que a visão computacional desempenha um papel significativo, e fabricação, em que os modelos de manutenção preditiva asseguram o tempo de atividade dos equipamentos.
Por que o aprendizado de máquina é importante para a segurança de APIs
O aprendizado de máquina é importante para a segurança de APIs porque pode ajudar a detectar e evitar vários tipos de ameaças à segurança. Ele aumenta a segurança de APIs melhorando continuamente seus algoritmos com mais informações, tornando-o mais eficiente na identificação e mitigação de ameaças. Estes são alguns motivos pelos quais o aprendizado de máquina é relevante no contexto da segurança de APIs:
- Detecção de anomalias. Os algoritmos de aprendizado de máquina podem aprender padrões a partir do comportamento normal das APIs e identificar anomalias que se desviam do comportamento esperado. Ao analisar dados históricos, eles podem detectar atividades incomuns, como tentativas de acesso não autorizado, transmissão anormal de dados ou padrões de uso incomuns.
- Detecção de invasões. As técnicas de aprendizado de máquina podem ser usadas para criar IDS (sistemas de detecção de invasões) que monitoram o tráfego de rede e identificam possíveis atividades mal-intencionadas ou ataques a APIs. Esses modelos podem aprender a reconhecer padrões de ataque com base em recursos extraídos de pacotes de rede e arquivos de log.
- Inteligência contra ameaças. Os algoritmos de aprendizado de máquina podem processar grandes quantidades de dados de várias fontes, incluindo feeds de inteligência contra ameaças, bancos de dados de vulnerabilidades e plataformas de mídia social. Ao analisar continuamente essas informações, os modelos podem identificar ameaças emergentes e incorporá-las aos recursos de detecção.
- Resposta em tempo real. Os modelos de aprendizado de máquina integrados aos sistemas de segurança de APIs permitem o monitoramento em tempo real de solicitações e respostas recebidas em escala, sem criar atrasos significativos de processamento ou interromper a disponibilidade do serviço.
Ao utilizar o aprendizado de máquina em soluções de segurança de APIs, as organizações podem aprimorar sua capacidade de detectar novas vulnerabilidades, adaptar-se rapidamente às ameaças em evolução, reduzir falsos positivos/negativos nos processos de detecção de ameaças, melhorar os recursos de resposta a incidentes e, por fim, proteger dados confidenciais transmitidos por meio de suas APIs de forma mais eficaz.
Perguntas frequentes
Os dados de treinamento são o conjunto de dados rotulado, usado para treinar modelos de aprendizado de máquina. Eles consistem em exemplos com pares de entrada e saída que o modelo usa para aprender padrões e fazer previsões. A qualidade e a quantidade dos dados de treinamento são essenciais para a criação de modelos precisos de aprendizado de máquina, pois influenciam diretamente o desempenho do modelo com novos dados.
Alguns modelos comuns de aprendizado de máquina são: árvores de decisão, regressão linear, regressão logística, máquinas de vetor de suporte (SVM) e redes neurais. Cada modelo tem características únicas adequadas a diferentes tipos de tarefas. Por exemplo, as árvores de decisão são frequentemente usadas para tarefas de classificação, enquanto as redes neurais são populares em aplicações de aprendizado profundo, incluindo visão computacional e PLN.
A programação tradicional depende de instruções explícitas dadas por programadores para executar tarefas específicas. Em contraste, o aprendizado de máquina permite que os sistemas aprendam com dados, fazendo previsões ou tomando decisões com base em padrões nesses dados, em vez de seguir regras predefinidas. Isso faz com que os modelos de aprendizado de máquina se adaptem e melhorem seu desempenho ao longo do tempo, à medida que processam mais dados.
O aprendizado de máquina é um componente essencial da ciência de dados, oferecendo as ferramentas e técnicas necessárias para analisar grandes conjuntos de dados, descobrir insights e fazer previsões com base em dados. Os cientistas de dados usam os modelos para criar análises preditivas, detectar padrões e automatizar a tomada de decisões, permitindo que as organizações aproveitem seus dados para obter benefícios estratégicos.
Por que os clientes escolhem a Akamai
A Akamai é a empresa de cibersegurança e computação em nuvem que potencializa e protege negócios online. Nossas soluções de segurança líderes de mercado, a inteligência avançada contra ameaças e a equipe de operações globais oferecem defesa completa para garantir a segurança de dados e aplicações empresariais em todos os lugares. As abrangentes soluções de computação em nuvem da Akamai oferecem desempenho e acessibilidade na plataforma mais distribuída do mundo. Empresas globais confiam na Akamai para obter a confiabilidade, a escala e a experiência líderes do setor necessárias para expandir seus negócios com confiança.


