
Maschinelles Lernen spielt eine entscheidende Rolle bei der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), indem es Systemen ermöglicht, menschliche Sprache zu verstehen und zu generieren. Sie wird in Anwendungen wie Stimmungsanalyse, Chatbots, Sprachübersetzung und Textzusammenfassung verwendet. NLP-Modelle analysieren und lernen Muster aus großen Textdatenmengen, sodass Maschinen menschliche Sprachnuancen interpretieren und präzise reagieren können.
Maschinelles Lernen ist ein Teilgebiet der KI, der sich auf die Entwicklung von Algorithmen konzentriert, die aus Daten lernen und Prognosen oder Entscheidungen auf der Grundlage von Daten treffen können. Beim maschinellen Lernen werden Modelle mithilfe von gekennzeichneten Datensätzen geschult, um Muster oder Korrelationen innerhalb der Daten zu erkennen. Diese Modelle verwenden diese Muster dann, um Vorhersagen über neue, unbekannte Daten zu erstellen.
Maschinelles Lernen (ML) ist ein Forschungsgebiet der künstlichen Intelligenz, das sich auf die Entwicklung von Algorithmen und Modellen konzentriert, die es Computern ermöglichen, zu lernen und Prognosen oder Entscheidungen zu treffen, ohne dass sie dafür explizit programmiert werden müssen. Dazu gehört das Trainings eines Computersystems mit einer großen Menge an Daten, die es ihm ermöglichen, Muster zu erkennen, Erkenntnisse zu gewinnen und präzise Prognosen oder Entscheidungen zu treffen.
Beim maschinellen Lernen lernt der Computer aus Erfahrung, indem er historische Daten analysiert, anstatt strenge Regeln zu befolgen, die von Menschen festgelegt wurden. Ziel ist es, Algorithmen zu entwickeln, die ihre Performance automatisch verbessern können, sobald mehr Daten verfügbar sind. Ausreichende Daten sind für effektive ML-Algorithmen von entscheidender Bedeutung, da Systeme große und genaue Trainingsdatensätze erfordern, um Fehler zu vermeiden. Es gibt mehrere Gründe, warum maschinelles Lernen in der heutigen Welt wichtig ist.
Vorteile des maschinellen Lernens
Maschinelles Lernen hat die Art und Weise, wie wir mit Technologie interagieren, revolutioniert und in verschiedenen Branchen unzählige Möglichkeiten eröffnet. Dieses Teilgebiet der künstlichen Intelligenz ermöglicht es Computern, aus Daten zu lernen und Prognosen oder Entscheidungen zu treffen, ohne explizit dafür programmiert zu werden. Die Vorteile von maschinellem Lernen sind vielfältig und ihre Auswirkungen sind über verschiedene Branchen hinweg zu erkennen.
Ein großer Vorteil des maschinellen Lernens besteht in der Fähigkeit, große Mengen komplexer Daten zu verarbeiten. Herkömmliche Methoden haben Probleme, wenn sie mit riesigen Datensätzen konfrontiert sind, die eine manuelle Analyse erfordern. Algorithmen für maschinelles Lernen hingegen können große Datenmengen schnell und präzise verarbeiten. So können Unternehmen wertvolle Erkenntnisse und Muster aufdecken, die in den Daten verborgen sind. Dies führt zu fundierteren Entscheidungen.
Ein weiterer Vorteil liegt in der verbesserten Effizienz und Automatisierung. Modelle für maschinelles Lernen können repetitive Aufgaben automatisieren, die sonst für den Menschen zeitaufwändig wären. Durch die Automatisierung dieser Prozesse können Unternehmen ihre Mitarbeiter entlasten, um sich auf wichtigere Aufgaben zu konzentrieren, die menschliche Kreativität und Problemlösungsfähigkeiten erfordern.
Maschinelles Lernen ermöglicht Nutzern auch personalisierte Erlebnisse, indem frühere Verhaltensmuster oder Präferenzen genutzt werden. Empfehlungssysteme, die von Plattformen wie Amazon, Netflix oder Spotify verwendet werden, sind die wichtigsten Beispiele für diese Personalisierung. Diese Systeme analysieren Nutzerdaten wie den Browserverlauf oder vorige Käufe, um Produkte oder Inhalte vorzuschlagen, die speziell auf die Interessen jedes einzelnen Nutzers zugeschnitten sind.
Neben der Personalisierung trägt maschinelles Lernen wesentlich zur Betrugserkennung und zur Cybersicherheit bei. Finanzinstitute wenden fortschrittliche Algorithmen zur Betrugserkennung an, die Transaktionsmuster kontinuierlich in Echtzeit analysieren, um verdächtige Aktivitäten umgehend zu erkennen. Ebenso können auf maschinellem Lernen basierende Sicherheitssysteme Malware-Angriffe und Anomalien in Netzwerktrafficmustern viel schneller erkennen als herkömmliche Sicherheitsansätze.
Darüber hinaus spielt maschinelles Lernen eine wichtige Rolle bei Anwendungen im Gesundheitswesen wie der Diagnose von Erkrankungen oder der Arzneimittelforschung. Durch die Analyse von Krankenakten und genetischen Daten von Millionen von Patienten weltweit können Modelle für maschinelles Lernen Ärzte dabei unterstützen, auf der Grundlage ähnlicher vorangegangener Fälle genaue Diagnosen zu stellen.
Und schließlich können Unternehmen mithilfe von vorausschauenden Analysen, die auf maschinellem Lernen basieren, zukünftige Trends auf der Grundlage historischer Datenanalysen genau vorhersagen. So können Unternehmen Kundenanforderungen vorhersehen, Produktionsprozesse optimieren und proaktive Entscheidungen treffen, die zu einer verbesserten Betriebseffizienz und höherer Rentabilität führen. Algorithmen für maschinelles Lernen können auf der Grundlage entwickelter Modelle Vorhersagen für zukünftige Ergebnisse treffen.
Arten des maschinellen Lernens
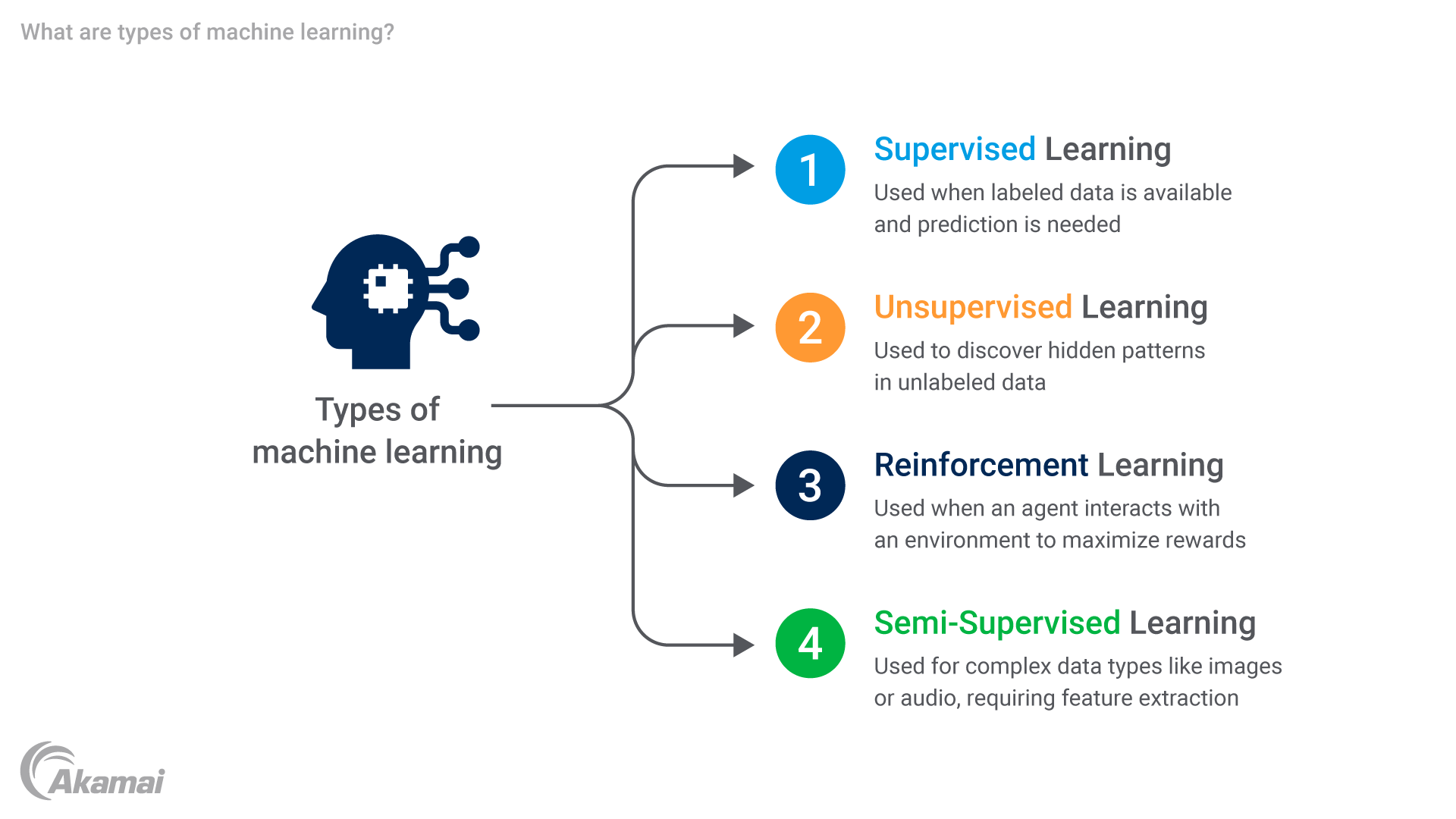
Maschinelles Lernen umfasst mehrere Kategorien, die unterschiedlichen Zwecken dienen und einzigartige Eigenschaften aufweisen. Zu diesen Arten des maschinellen Lernens gehören überwachtes Lernen, unüberwachtes Lernen, bestärkendes Lernen und halbüberwachtes Lernen. Sehen wir uns diese Lerntechniken genauer an.
Überwachtes Lernen: Bei diesem Ansatz wird der Algorithmus für maschinelles Lernen anhand von gekennzeichneten Beispielen trainiert, bei denen sowohl Eingaben (Merkmale) als auch gewünschte Ergebnisse (Kennzeichnungen) bereitgestellt werden. Das Modell verallgemeinert dann anhand dieser Beispiele, um Kennzeichnungen für neue, unbekannte Eingabeinstanzen vorherzusagen.
Unüberwachtes Lernen: Hier untersucht der Algorithmus für maschinelles Lernen nicht gekennzeichnete Daten ohne vordefinierte Ergebnisse oder Ziele. Das Ziel besteht hauptsächlich darin, verborgene Beziehungen oder Strukturen innerhalb des Datensatzes zu erkennen.
Bestärkendes Lernen: Bei dieser Technik interagiert ein Agent mit einer Umgebung und lernt, wie er Maßnahmen ergreift, um die Belohnung zu maximieren oder Strafen zu minimieren. Der Agent lernt durch Ausprobieren auf der Grundlage des Feedbacks, das er aus der Umgebung erhält.
Halbüberwachtes Lernen: Dieser Ansatz des maschinellen Lernens kombiniert während des Trainings eine kleine Menge an gekennzeichneten Daten mit einer großen Menge an nicht gekennzeichneten Daten. Diese Methode ist besonders dann nützlich, wenn gekennzeichnete Daten nur knapp oder teuer zu erhalten sind, da sie die Fülle an nicht gekennzeichneten Daten nutzt, um die Modellperformance oder die Generalisierbarkeit zu verbessern.
Maschinelles Lernen vs. Deep Learning
Maschinelles Lernen und Deep Learning sind verwandte Konzepte innerhalb der künstlichen Intelligenz, wobei Deep Learning eine Teilmenge des maschinellen Lernens darstellt, das neuronale Netze mit mehreren Ebenen verwendet.
Maschinelles Lernen ist ein Teilgebiet der KI, der sich auf die Entwicklung von Algorithmen konzentriert, die aus Daten lernen und Prognosen oder Entscheidungen auf der Grundlage von Daten treffen können. Beim maschinellen Lernen werden Modelle mithilfe von gekennzeichneten Datensätzen geschult, um Muster oder Korrelationen innerhalb der Daten zu erkennen. Diese Modelle verwenden diese Muster dann, um Vorhersagen über neue, unbekannte Daten zu erstellen.
Deep Learning ist ein Teilbereich des maschinellen Lernens, der sich auf das Training künstlicher neuronaler Netze mit mehreren Ebenen konzentriert, um aus großen Datenmengen komplexe Muster und Darstellungen zu lernen. Es wird von der Struktur und Funktionsweise des menschlichen Gehirns inspiriert, in dem Informationen durch miteinander verbundene Neuronen fließen.
Der Begriff „Deep“ in „Deep Learning“ bezieht sich auf die Tiefe dieser neuronalen Netze, die aus mehreren verborgenen Ebenen (Hidden Layers) zwischen den Eingabe- und Ausgabeebenen bestehen. Diese versteckten Schichten ermöglichen es dem Netz, hierarchische Merkmale und abstrakte Darstellungen auf verschiedenen Ebenen zu extrahieren. Dies ermöglicht es, komplexe Beziehungen innerhalb der Daten zu verstehen.
Deep-Learning-Modelle werden normalerweise anhand großer Mengen an gekennzeichneten Daten trainiert. Dabei werden Daten in die Ausgangsebene des Netzes eingespeist, durch mehrere Zwischenebenen (auch Hidden Layers genannt) geleitet und generieren in der letzten Ebene einer Ausgabevorhersage. Während des Trainings passen diese Modelle ihre internen Parameter iterativ an, indem sie Optimierungsalgorithmen wie den Gradientenabstieg verwenden, um Fehler zu minimieren oder die Performance zu maximieren.
Zu den wichtigsten Unterschieden zwischen den beiden gehören:
- Darstellung: Beim maschinellen Lernen müssen Ingenieure normalerweise manuell Funktionen als Eingaben für die Algorithmen entwerfen. Deep-Learning-Modelle hingegen können hierarchische Darstellungen automatisch aus rohen Eingabedaten extrahieren.
- Komplexität: Deep-Learning-Modelle sind aufgrund ihrer mehreren Ebenen und einer großen Anzahl von Parametern tendenziell komplexer als herkömmliche Modelle des maschinellen Lernens.
- Datenanforderungen: Maschinelles Lernen funktioniert oft gut mit kleineren Datensätzen, wenn ausreichend Fachwissen für die Auswahl und Entwicklung von Funktionen vorhanden ist. Auf der anderen Seite liegt die Stärke von Deep Learning in der Fähigkeit, riesige Mengen an gekennzeichneten Daten für äußerst genaue Vorhersagen oder Entscheidungsaufgaben zu nutzen, indem neuronale Netze mit mehren Ebenen verwendet werden, die komplexe Beziehungen innerhalb komplexer Datensätze erfassen können.
Anwendungsfälle für Modelle des maschinellen Lernens
Maschinelles Lernen findet in einer Vielzahl von Branchen Anwendung und ermöglicht Innovationen in verschiedenen Bereichen. Im Gesundheitswesen hilft maschinelles Lernen durch die Analyse von medizinischen Bildern und Patientenakten bei der Diagnose von Krankheiten. Im Finanzbereich hilft es, Betrug zu erkennen und Investitionsstrategien zu optimieren. Einzelhandels- und E-Commerce-Unternehmen setzen auf maschinelles Lernen für personalisierte Empfehlungen. Kundenservice-Abteilungen nutzen hingegen Chatbots und virtuelle Assistenten, die durch die Verarbeitung natürlicher Sprachen unterstützt werden, und so das Nutzererlebnis verbessern. Weitere gängige Anwendungsfälle sind autonomes Fahren, bei dem Computervision eine wichtige Rolle spielt, und Fertigung, bei der vorausschauende Wartungsmodelle die Verfügbarkeit der Ausrüstung gewährleisten.
Warum ML für die API-Sicherheit wichtig ist
Maschinelles Lernen ist für die API-Sicherheit wichtig, da es dabei helfen kann, verschiedene Arten von Sicherheitsbedrohungen zu erkennen und zu verhindern. Ein maschinelles Lernsystem verbessert die API-Sicherheit, indem es seine Algorithmen kontinuierlich mit mehr Input verbessert. Dadurch macht es die Identifizierung und Abwehr von Bedrohungen effizienter. Im Folgenden finden Sie einige Gründe, warum maschinelles Lernen im Kontext der API-Sicherheit relevant ist:
- Erkennung von Auffälligkeiten. Algorithmen für maschinelles Lernen können Muster aus dem normalen API-Verhalten ableiten und Anomalien identifizieren, die vom erwarteten Verhalten abweichen. Durch die Analyse historischer Daten können sie ungewöhnliche Aktivitäten wie unbefugte Zugriffsversuche, anormale Datenübertragung oder ungewöhnliche Nutzungsmuster erkennen.
- Angriffserkennung (Intrusion Detection). Techniken von maschinellem Lernen können genutzt werden, um Angriffserkennungssysteme (Intrusion Detection Systems, IDS) zu entwickeln, die den Netzwerktraffic überwachen und potenzielle schädliche Aktivitäten oder Angriffe auf APIs identifizieren. Diese Modelle können anhand von Funktionen, die aus Netzwerkpaketen und Protokolldateien extrahiert wurden, Angriffsmuster erkennen.
- Threat Intelligence. Algorithmen für maschinelles Lernen können große Datenmengen aus verschiedenen Quellen verarbeiten, darunter Feeds mit Bedrohungsinformationen, Datenbanken mit Schwachstellen und Social-Media-Plattformen. Durch die kontinuierliche Analyse dieser Informationen können Modelle für maschinellen Lernens aufkommende Bedrohungen identifizieren und in ihre Erkennungsfunktionen integrieren.
- Reaktion in Echtzeit. Modelle für maschinelles Lernen, die in API-Sicherheitssysteme integriert sind, ermöglichen eine skalierbare Echtzeitüberwachung eingehender Anforderungen und Antworten, ohne dass es zu erheblichen Verarbeitungsverzögerungen oder Beeinträchtigung der Serviceverfügbarkeit kommt.
Indem sie maschinelles Lernen für API-Sicherheitslösungen einsetzen, können Unternehmen ihre Fähigkeit verbessern, neue Schwachstellen zu erkennen, sich schnell an neue Bedrohungen anzupassen, falsch positive/negative Ergebnisse in Bedrohungserkennungsprozessen zu reduzieren, die Reaktionsfähigkeit von Vorfällen zu verbessern und letztendlich vertrauliche Daten, die über ihre APIs übertragen werden, effektiver zu schützen.
Häufig gestellte Fragen
Trainingsdaten sind die gekennzeichneten Datensätze, die zum Training von Modellen des maschinellen Lernens verwendet werden. Sie bestehen aus Beispielen mit Eingabe-/Ausgabepaaren, die das Modell verwendet, um Muster zu erlernen und Prognosen zu erstellen. Die Qualität und Quantität der Trainingsdaten sind für die Erstellung präziser ML-Modelle von entscheidender Bedeutung, da sie direkten Einfluss auf die Performance des Modells bei neuen Daten haben.
Zu den gängigen ML-Modellen gehören Entscheidungsbäume, lineare Regression, logistische Regression, Support Vector Machines (SVM) und neuronale Netzwerke. Jedes Modell verfügt über einzigartige Eigenschaften, die für verschiedene Arten von Aufgaben geeignet sind. So werden beispielsweise Entscheidungsbäume häufig für Klassifizierungsaufgaben verwendet, während neuronale Netze in Deep-Learning-Anwendungen, einschließlich Computervision und NLP, beliebt sind.
Herkömmliche Programmierung beruht auf expliziten Anweisungen, die von Programmierern zur Ausführung bestimmter Aufgaben erteilt werden. Im Gegensatz dazu ermöglicht maschinelles Lernen Systemen, aus Daten zu lernen, Prognosen oder Entscheidungen basierend auf Mustern in diesen Daten zu treffen, anstatt vordefinierte Regeln zu befolgen. Auf diese Weise können Modelle des maschinellen Lernens ihre Performance im Laufe der Zeit anpassen und verbessern, da sie mehr Daten verarbeiten.
Maschinelles Lernen ist eine Kernkomponente der Data Science und stellt die Tools und Techniken bereit, die zur Analyse großer Datensätze, zur Gewinnung von Erkenntnissen und zur Erstellung datengesteuerter Prognosen erforderlich sind. Datenwissenschaftler verwenden Modelle für maschinelles Lernen, um prädiktive Analysen zu erstellen, Muster zu erkennen und die Entscheidungsfindung zu automatisieren, sodass Unternehmen ihre Daten für strategische Vorteile nutzen können.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.


