
L'apprentissage automatique joue un rôle crucial dans le traitement du langage naturel (NLP) en permettant aux systèmes de comprendre et de générer le langage humain. Il est utilisé dans des applications telles que l'analyse des sentiments, les chatbots, la traduction et la synthèse de texte. Les modèles NLP analysent et apprennent des modèles à partir de grands volumes de données textuelles, ce qui permet aux machines d'interpréter les nuances du langage humain et de répondre avec précision.
L'apprentissage automatique est une branche de l'IA qui se concentre sur le développement d'algorithmes capables d'apprendre et de réaliser des prédictions ou de prendre des décisions en fonction des données. L'apprentissage automatique consiste à entraîner des modèles à reconnaître les schémas ou les corrélations au sein des données à partir d'ensembles de données étiquetées. Ces modèles utilisent ensuite ces schémas pour réaliser des prédictions sur de nouvelles données inconnues.
L'apprentissage automatique (ML) est un domaine d'étude de l'intelligence artificielle qui se concentre sur le développement d'algorithmes et de modèles permettant aux ordinateurs d'apprendre et de réaliser des prédictions ou de prendre des décisions sans programmation explicite. Il implique l'entraînement d'un système informatique avec une grande quantité de données, ce qui lui permet de reconnaître des schémas, d'obtenir des informations et de réaliser des prédictions ou de prendre des décisions précises.
Dans le domaine de l'apprentissage automatique, l'ordinateur apprend de son expérience en analysant les données historiques au lieu de suivre des règles strictes définies par les humains. L'objectif est de développer des algorithmes capables d'améliorer automatiquement leurs performances à mesure que de plus en plus de données sont disponibles. Il est essentiel de disposer de suffisamment de données pour des algorithmes d'apprentissage automatique efficaces, car les systèmes ont besoin d'ensembles de données d'entraînement volumineux et précis pour éviter les erreurs. Il existe plusieurs raisons pour lesquelles l'apprentissage automatique est important dans le monde actuel.
Avantages de l'apprentissage automatique
L'apprentissage automatique a révolutionné notre façon d'interagir avec la technologie et a ouvert d'innombrables possibilités dans différents secteurs. Cette branche de l'intelligence artificielle permet aux ordinateurs d'apprendre à partir des données et de réaliser des prédictions ou de prendre des décisions sans être explicitement programmés. Les avantages de l'apprentissage automatique sont nombreux et son impact peut être observé dans différents secteurs.
L'un des principaux avantages de l'apprentissage automatique est sa capacité à gérer de grandes quantités de données complexes. Les méthodes traditionnelles ont du mal à gérer des ensembles de données volumineux qui nécessitent une analyse manuelle. Les algorithmes d'apprentissage automatique, quant à eux, peuvent traiter de grandes quantités d'informations facilement, rapidement et avec précision. Cela permet aux entreprises de découvrir des informations et des modèles précieux dissimulés dans les données, et donc de prendre des décisions plus éclairées.
Un autre avantage est l'amélioration de l'efficacité et de l'automatisation. Les modèles d'apprentissage automatique peuvent automatiser les tâches répétitives qui seraient très longues pour les humains. En automatisant ces processus, les entreprises permettent à leurs employés de se concentrer sur des tâches plus importantes, pour lesquelles ils doivent faire appel à leur créativité et à leurs compétences en matière de résolution de problèmes.
L'apprentissage automatique permet également aux utilisateurs d'offrir des expériences personnalisées, en s'appuyant sur les habitudes ou préférences comportementales passées. Les systèmes de recommandation utilisés par des plateformes comme Amazon, Netflix ou Spotify sont des exemples de ce pouvoir de personnalisation. Ils analysent les données des utilisateurs, telles que l'historique de navigation ou d'achats, afin de suggérer des produits ou du contenu spécifiquement adaptés aux intérêts de chaque utilisateur.
Outre la personnalisation, l'apprentissage automatique contribue de manière significative à la détection des fraudes et aux efforts de cybersécurité. Les institutions financières utilisent des algorithmes avancés de détection des fraudes qui analysent en permanence les modèles transactionnels en temps réel, pour identifier rapidement toute activité suspecte. De même, les systèmes de sécurité basés sur l'apprentissage automatique peuvent détecter les attaques de logiciels malveillants et les anomalies dans les schémas de trafic réseau beaucoup plus rapidement que les approches de sécurité traditionnelles.
En outre, l'apprentissage automatique joue un rôle crucial dans les applications médicales telles que le diagnostic de maladies ou la recherche de médicaments. En analysant les dossiers médicaux et les données génétiques de millions de patients dans le monde entier, les modèles d'apprentissage automatique peuvent aider les médecins à établir des diagnostics précis basés sur des cas similaires rencontrés auparavant.
Enfin, l'analyse prédictive basée sur l'apprentissage automatique aide les entreprises à prévoir avec précision les tendances futures en fonction de l'analyse des données historiques. Elles peuvent ainsi anticiper les demandes des clients, optimiser les processus de production et prendre des décisions proactives qui mènent à une efficacité opérationnelle et à une rentabilité accrues. Les algorithmes d'apprentissage automatique peuvent faire des prédictions sur les résultats futurs en fonction des modèles développés.
Types d'apprentissage automatique
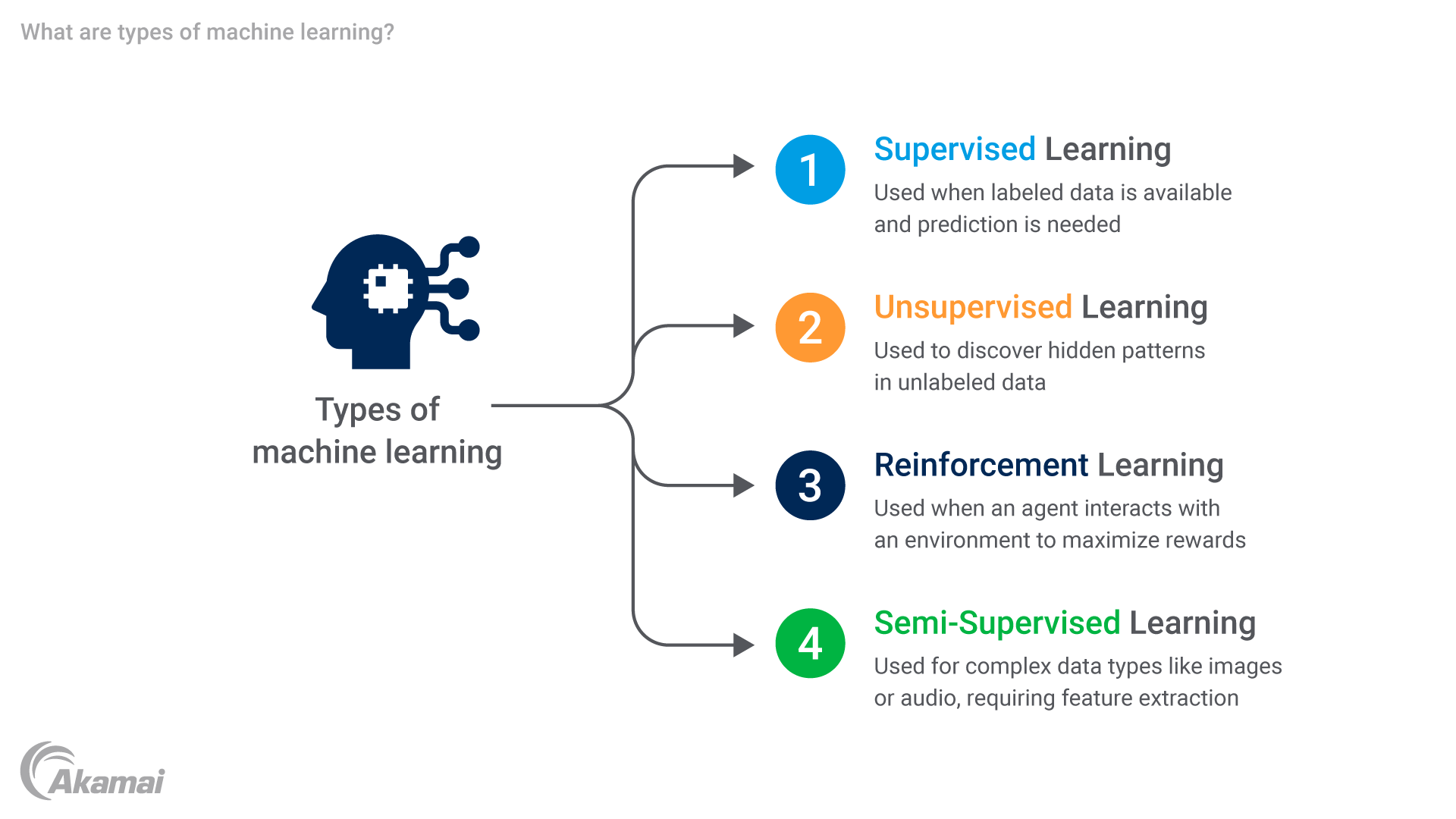
L'apprentissage automatique englobe plusieurs catégories qui ont des objectifs différents et des caractéristiques uniques. Parmi ces types d'apprentissage automatique figurent l'apprentissage supervisé, l'apprentissage non supervisé, l'apprentissage par renforcement et l'apprentissage semi-supervisé. Découvrons ces techniques d'apprentissage plus en détail.
Apprentissage supervisé : cette approche consiste à entraîner l'algorithme d'apprentissage automatique sur des exemples étiquetés où les entrées (fonctions) et les sorties souhaitées (étiquettes) sont fournies. Le modèle effectue ensuite des généralisations à partir de ces exemples pour prévoir les étiquettes des nouvelles instances d'entrée inconnues.
Apprentissage non supervisé : dans ce cas, l'algorithme d'apprentissage automatique explore les données non étiquetées sans aucune sortie ni cible prédéfinie. Son objectif est principalement de découvrir les relations ou les structures cachées dans l'ensemble de données.
Apprentissage par renforcement : cette technique implique qu'un agent interagit avec un environnement et apprend à prendre des mesures afin d'optimiser les récompenses ou de minimiser les pénalités. L'agent apprend en faisant des essais et s'appuie sur les retours de l'environnement.
Apprentissage semi-supervisé : cette approche de l'apprentissage automatique combine une petite quantité de données étiquetées avec une grande quantité de données non étiquetées pendant l'entraînement. Cette méthode est particulièrement utile lorsque les données étiquetées sont rares ou coûteuses, car elle exploite l'abondance de données non étiquetées pour améliorer les performances du modèle et la généralisabilité.
Apprentissage automatique ou apprentissage profond
L'apprentissage automatique et l'apprentissage profond sont des concepts liés appartenant au domaine de l'intelligence artificielle. L'apprentissage profond est un sous-ensemble de l'apprentissage automatique qui utilise des réseaux neuronaux à plusieurs couches.
L'apprentissage automatique est une branche de l'IA qui se concentre sur le développement d'algorithmes capables d'apprendre et de réaliser des prédictions ou de prendre des décisions en fonction des données. L'apprentissage automatique consiste à entraîner les modèles à reconnaître les schémas ou les corrélations au sein des données à partir d'ensembles de données étiquetées. Ces modèles utilisent ensuite ces schémas pour réaliser des prédictions sur de nouvelles données inconnues.
L'apprentissage profond est un sous-ensemble de l'apprentissage automatique qui se concentre sur la formation de réseaux neuronaux artificiels avec plusieurs couches, pour apprendre des modèles et des représentations complexes à partir de grandes quantités de données. Il s'inspire de la structure et du fonctionnement du cerveau humain, où les informations circulent à travers des neurones interconnectés.
Le terme « profond » se rapporte à la profondeur de ces réseaux neuronaux, qui sont composés de plusieurs couches dissimulées entre les couches d'entrée et de sortie. Ces couches dissimulées permettent au réseau d'extraire des fonctions hiérarchiques et des représentations abstraites à différents niveaux, et donc de comprendre les relations complexes au sein des données.
Les modèles d'apprentissage profond sont généralement entraînés avec de grands volumes de données étiquetées. Le processus consiste à alimenter les données d'entrée dans la couche initiale du réseau, à les faire passer par plusieurs couches intermédiaires (également appelées couches dissimulées), puis à générer une prédiction de sortie à partir de la dernière couche. Pendant l'entraînement, ces modèles ajustent leurs paramètres internes de manière itérative à l'aide d'algorithmes d'optimisation, tels que la descente de gradient, afin de réduire les erreurs ou d'optimiser les performances.
Voici quelques-unes des principales différences entre les deux :
- Représentation : dans l'apprentissage automatique, les ingénieurs doivent traditionnellement concevoir manuellement des fonctions en tant qu'entrées pour les algorithmes. En revanche, les modèles d'apprentissage profond peuvent extraire automatiquement des représentations hiérarchiques à partir de données d'entrée brutes.
- Complexité : les modèles d'apprentissage profond ont tendance à être plus complexes que les modèles d'apprentissage automatique traditionnels, en raison de leurs couches multiples et de leur grand nombre de paramètres.
- Exigences en matière de données : l'apprentissage automatique est souvent efficace avec des ensembles de données plus petits, où les connaissances du domaine sont suffisantes pour la sélection des fonctions et l'ingénierie. D'un autre côté, la puissance de l'apprentissage profond réside dans sa capacité à utiliser d'énormes volumes de données étiquetées pour réaliser des prédictions ou des prises de décision très précises, en s'appuyant sur des réseaux neuronaux à plusieurs couches capables de capturer les relations dans les ensembles de données complexes.
Cas d'utilisation du modèle d'apprentissage automatique
L'apprentissage automatique est appliqué à un large éventail de secteurs, ce qui permet d'innover dans différents domaines. Dans le secteur de la santé, l'apprentissage automatique facilite le diagnostic des maladies en analysant les images médicales et les dossiers des patients. Dans le secteur financier, elle permet de détecter les fraudes et d'optimiser les stratégies d'investissement. Les entreprises de vente au détail et d'e-commerce utilisent l'apprentissage automatique pour générer des recommandations personnalisées, tandis que les services client s'appuient sur les chatbots et les assistants virtuels optimisés par le traitement du langage naturel pour améliorer l'expérience utilisateur. D'autres cas d'utilisation courants incluent la conduite autonome, où la vision par ordinateur joue un rôle important, et la fabrication, où les modèles de maintenance prédictive garantissent la disponibilité des équipements.
Pourquoi l'apprentissage automatique est important pour la sécurité des API
L'apprentissage automatique est important pour la sécurité des API, car il peut aider à détecter et à prévenir différents types de menaces de sécurité. Un système d'apprentissage automatique renforce la sécurité des API en affinant continuellement ses algorithmes grâce à des entrées supplémentaires, ce qui le rend plus efficace pour détecter et atténuer les menaces. Voici quelques raisons pour lesquelles l'apprentissage automatique est pertinent dans le contexte de la sécurité des API :
- Détection des anomalies. Les algorithmes d'apprentissage machine peuvent apprendre les modèles à partir du comportement normal de l'API et identifier les anomalies qui s'écartent du comportement attendu. En analysant les données historiques, ils peuvent détecter des activités inhabituelles telles que des tentatives d'accès non autorisées, des transmissions de données anormales ou des schémas d'utilisation inhabituels.
- Détection des intrusions. Les techniques d'apprentissage automatique peuvent être utilisées pour créer des systèmes de détection d'intrusion (IDS) qui surveillent le trafic réseau et identifient les activités malveillantes ou les attaques potentielles sur les API. Ces modèles peuvent apprendre à reconnaître les schémas d'attaque à partir des fonctions extraites des paquets réseau et des fichiers journaux.
- Renseignements sur les menaces. Les algorithmes d'apprentissage automatique peuvent traiter de grandes quantités de données provenant de différentes sources, notamment des flux de renseignements sur les menaces, des bases de données de vulnérabilité et des plateformes de réseaux sociaux. En analysant ces informations en continu, les modèles d'apprentissage machine peuvent identifier les menaces émergentes et les intégrer à leurs capacités de détection.
- Réponse en temps réel. Les modèles d'apprentissage automatique intégrés aux systèmes de sécurité des API permettent de surveiller en temps réel les demandes et les réponses entrantes à grande échelle, sans générer de retards de traitement importants ni perturber la disponibilité des services.
En tirant parti de l'apprentissage automatique dans les solutions de sécurité des API, les entreprises peuvent renforcer leur capacité à détecter de nouvelles vulnérabilités, s'adapter rapidement à l'évolution des menaces, réduire les faux positifs/négatifs dans les processus de détection des menaces, améliorer leur réponse aux incidents et protéger plus efficacement les données sensibles transmises via leurs API.
Foire aux questions
Les données d'entraînement correspondent à l'ensemble de données étiquetées utilisé pour entraîner les modèles d'apprentissage automatique. Elles comprennent des exemples avec des paires entrée-sortie que le modèle utilise pour apprendre des schémas et réaliser des prédictions. La qualité et la quantité de données d'entraînement sont essentielles pour créer des modèles d'apprentissage automatique précis, car elles influencent directement les performances du modèle sur de nouvelles données.
Les modèles courants d'apprentissage automatique incluent les arbres de décision, la régression linéaire, la régression logistique, les machines vectorielles de support (SVM) et les réseaux neuronaux. Chaque modèle possède des caractéristiques uniques adaptées à différents types de tâches. Par exemple, les arbres de décision sont souvent utilisés pour les tâches de classification, tandis que les réseaux neuronaux sont populaires dans les applications d'apprentissage profond, y compris la vision par ordinateur et le NLP.
La programmation traditionnelle repose sur des instructions explicites données par les programmeurs pour effectuer des tâches spécifiques. En revanche, l'apprentissage automatique permet aux systèmes d'apprendre à partir des données, en réalisant des prédictions ou en prenant des décisions basées sur des modèles dans ces données, plutôt que de suivre des règles prédéfinies. Cela permet aux modèles d'apprentissage automatique de s'adapter et d'améliorer leurs performances au fil du temps, à mesure qu'ils traitent plus de données.
L'apprentissage automatique est un composant essentiel de la science des données. Il fournit les outils et les techniques nécessaires pour analyser de grands ensembles de données, découvrir des informations et réaliser des prévisions basées sur les données. Les experts en science des données utilisent des modèles d'apprentissage automatique pour créer des analyses prédictives, détecter des modèles et automatiser la prise de décision, ce qui permet aux entreprises d'exploiter leurs données pour bénéficier d'avantages stratégiques.
Pourquoi les clients choisissent-ils Akamai ?
Akamai est l'entreprise de cybersécurité et de Cloud Computing qui soutient et protège l'activité en ligne. Nos solutions de sécurité leaders du marché, nos informations avancées sur les menaces et notre équipe opérationnelle internationale assurent une défense en profondeur pour protéger les données et les applications des entreprises du monde entier. Les solutions de Cloud Computing complètes d'Akamai offrent des performances de pointe à un coût abordable sur la plateforme la plus distribuée au monde. Les grandes entreprises du monde entier font confiance à Akamai pour bénéficier de la fiabilité, de l'évolutivité et de l'expertise de pointe nécessaires pour développer leur activité en toute sécurité.


