
Akamai Firewall for AI:为新兴 LLM 应用威胁提供强劲防护力量


全球各地的组织正在借助人工智能(AI)推动业务发展,寻求提升生产力、优化流程并降低成本。当前最常用的 AI 形式之一是大型语言模型(LLM),企业正利用它来回答客户问题、提供定制化信息等,从而带来多种收益。
AI 模型和 LLM 正面临严重攻击风险
LLM 在带来益处的同时,也伴随着新的风险与威胁。AI 模型包含有价值的专有知识和敏感数据集,因此成为攻击者的主要目标。LLM 易受到新型且独特的攻击,包括:
提示注入攻击 — 攻击者操纵 AI 生成的响应,以窃取敏感数据或绕过安全防护。
针对 AI 的拒绝服务 (DoS) 攻击 — 攻击者通过海量请求耗尽 AI 模型资源。
有害输出和幻觉 — AI 模型生成误导性、偏见或冒犯性内容,可能造成声誉风险。
数据泄露和模型盗窃 — 攻击者试图从 AI 模型中获取专有知识。
合规性和治理挑战 — 像 OWASP Top 10 for LLM这样的行业指南要求更严格的监管。
网络安全团队需要在保护组织安全的同时,不妨碍 LLM 带来的创新与生产力提升。同时也不能影响客户体验。但传统的安全措施并未针对这些新的威胁而设计。他们需要专门用于检测和缓解 LLM 攻击的防护措施。
保护 AI 应用程序的完整性,安全性和可靠性
Akamai 最近推出 Firewall for AI (AI 防火墙),专为防护 AI 驱动的应用程序、LLM 及 AI 驱动的 API 免受新兴网络威胁而生。通过保护 AI 的入站查询和出站响应,Firewall for AI 弥补了生成式 AI 带来的关键安全漏洞。
凭借实时威胁检测、策略驱动的执行以及自适应安全措施,该防火墙可防御提示注入、敏感数据泄露、对抗性攻击以及针对 AI 的拒绝服务(DoS)攻击。因此,它可保护 AI 驱动创新的完整性、安全性与可靠性
核心特色功能
Firewall for AI 核心特色功能包括:
- 多层防护:阻止对抗性输入、未经授权的查询和大规模数据抓取,以防止模型操作和数据外泄。
实时 AI 威胁检测:使用自适应安全规则动态响应不断演变的基于 AI 的攻击,包括注入保护和模型利用。
合规性和数据保护:确保 AI 生成的输出安全可靠,并符合监管及行业标准。
灵活的部署选项:通过 Akamai edge、REST API 或反向代理部署,实现与现有安全框架的无缝集成。
- 主动的风险抵御措施:过滤 AI 输出,以防止有害内容、幻觉和未经授权的数据泄露
工作原理
Firewall for AI 会检查输入和输出,通过检测并拦截恶意提示,同时只输出安全可信的响应,确保您的安全防护措施始终有效(见图)。
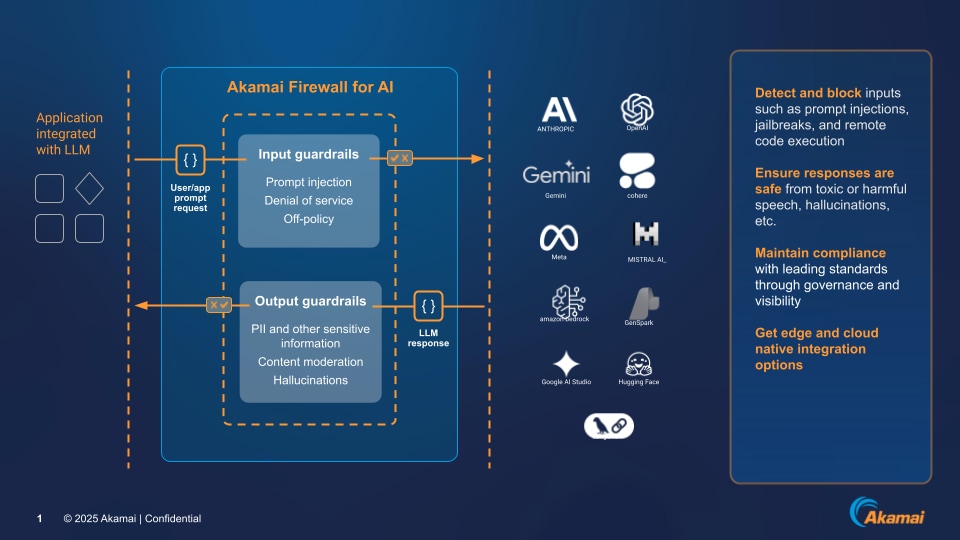 Figure: How Akamai Firewall for AI works
Figure: How Akamai Firewall for AI works
例如,Firewall for AI 会审查 LLM 提示,识别试图操纵 LLM 的行为,例如旨在绕过 LLM 隐私或安全防护的提示措辞。同样,它会在 LLM 响应到达用户之前进行检查,有助于防止敏感数据(如客户账户号码)泄露。
随着 AI 融入核心业务应用程序,这种级别的检查可轻松纳入应用测试流程,在每个环节增强信任与可靠性。
了解更多
了解 Akamai Firewall for AI 如何保护 LLM,同时保持业务高效。
