
KI-Inferenz bezeichnet den Prozess, in dem ein KI-Modell, das mit kuratierten Datensätzen trainiert wurde, Eingabedaten aufnimmt und Ausgaben in Form von Vorhersagen oder Entscheidungen erzeugt. Dabei geht es um die Anwendung des erlernten Wissens aus der Trainingsphase auf neue, unbekannte Daten.
Künstliche Intelligenz (KI) hat zahlreiche Branchen revolutioniert, vom Gesundheitswesen bis hin zu autonomen Fahrzeugen. Voraussetzung dafür war, dass KI Systeme ermöglicht, die intelligente Entscheidungen auf der Grundlage von Daten treffen können. Das Herzstück dieser KI-Systeme ist der Prozess der KI-Inferenz, eine kritische Phase, in der trainierte KI-Modelle eingesetzt werden, um Vorhersagen oder Entscheidungen in Echtzeit zu treffen. Von besonderer Bedeutung ist dieser Prozess für Anwendungen, die sofortige Reaktionen erfordern, wie Chatbots und selbstfahrende Fahrzeuge. Hier ist die Fähigkeit, schnell Eingabedaten zu verarbeiten und Ergebnisse zu generieren, eine Frage der Sicherheit und Effizienz.
Einführung in KI-Inferenz
KI-Inferenz ist der Prozess, in dem ein trainiertes Machine-Learning-Modell Eingabedaten erfasst und eine Ausgabe erzeugt, zum Beispiel in Form einer Vorhersage oder einer Entscheidung. Im Gegensatz zur Trainingsphase, in der zum Erlernen von Mustern und Beziehungen große Datensätze in einen Algorithmus eingespeist werden, ist Inferenz die Anwendung dieses erlernten Wissens auf neue, unbekannte Daten. Dieser Unterschied ist entscheidend, wenn man die Rolle der KI-Inferenz in realen Anwendungen verstehen will. Beispielsweise muss das Modell bei autonomen Fahrzeugen Sensordaten in Echtzeit verarbeiten, um Entscheidungen zum Lenken, Bremsen und Beschleunigen zu treffen, die alle eine geringe Latenz und hohe Genauigkeit erfordern.
Im Bereich der Chatbots ermöglicht KI-Inferenz die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP). Dadurch ist es möglich, Nutzeranfragen in gesprächsartiger Form zu verstehen und zu beantworten. Diese Entscheidungsfindung in Echtzeit macht KI-Anwendungen wie Chatbots und virtuelle Assistenten so leistungsstark und nutzerfreundlich. Die Fähigkeit, unbekannte Daten zu verarbeiten und genaue Vorhersagen zu treffen, ist ein Beleg für die Robustheit des trainierten KI-Modells und die Effizienz des Inferenzprozesses.
KI-Training vs. KI-Inferenz
Die Entwicklung von KI-Systemen umfasst zwei wesentliche Phasen: Die KI-Trainingsphase und die Inferenz. Während der KI-Trainingsphase werden KI-Modelle mit großen Datensätzen gefüttert, um Muster zu lernen und zu erkennen. Dieser Prozess erfordert häufig erhebliche Rechenressourcen und Zeit, da das Modell seine Parameter iterativ anpassen muss, um Fehler zu minimieren. Die beim Trainieren verwendeten Algorithmen, wie neuronale Deep-Learning-Netzwerke, wurden entwickelt, um die Performance des Modells anhand der Trainingsdaten zu optimieren.
KI-Inferenz bezieht sich dagegen auf die Bereitstellungsphase, in der das trainierte Modell verwendet wird, um auf der Grundlage neuer, eingehender Daten Vorhersagen oder Entscheidungen zu treffen. Hier liegt der Schwerpunkt auf geringer Latenz und Echtzeit-Performance, da Verzögerungen bei Anwendungen wie dem autonomen Fahren und Systemen für Echtzeit-Entscheidungsprozesse nachteilig sein können. Die Rechenanforderungen sind bei der Inferenz in der Regel geringer als beim Trainieren. Sie erfordern aber dennoch eine effiziente Nutzung von Prozessoren wie GPUs (Grafikprozessoren) und CPUs (Hauptprozessoren), damit eine hohe Performance und schnelle Reaktionszeiten sichergestellt werden. Lesen Sie unsere Einführung in Training und Inferenz beim maschinellen Lernen, um mehr über KI-Training und -Inferenz zu erfahren.
Schritte bei KI-Inferenz
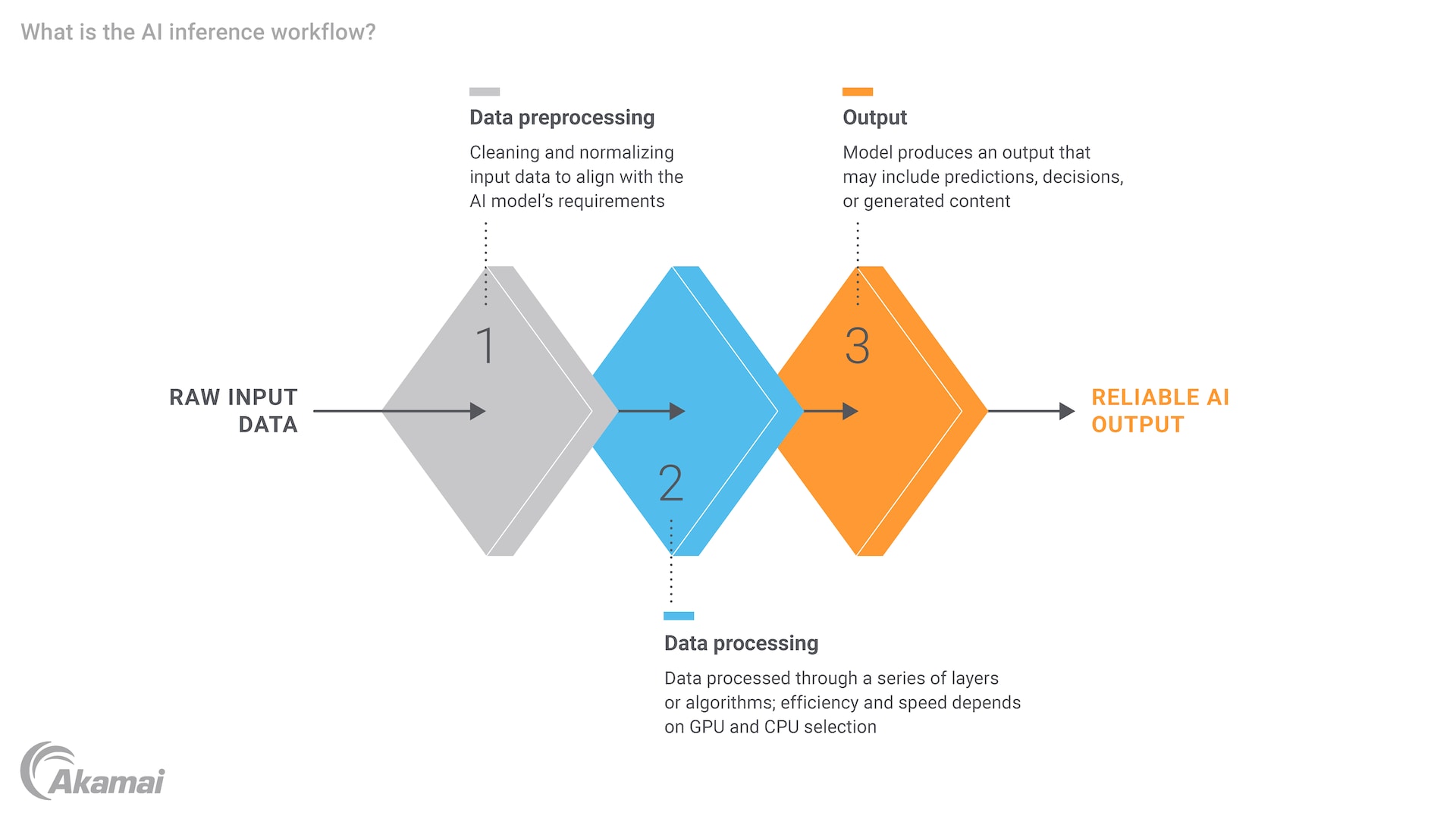
Der Prozess der KI-Inferenz umfasst mehrere wichtige Schritte, die jeweils eine sorgfältige Prüfung der Rechenressourcen und der Recheneffizienz erfordern. Zunächst müssen die Eingabedaten vorverarbeitet werden, damit sichergestellt ist, dass sie in einem für das Modell geeigneten Format vorliegen. Dies kann die Normalisierung von Daten, die Umwandlung von Text in numerische Vektoren oder die Anpassung von Bildgrößen beinhalten. Sobald die Daten vorbereitet sind, werden sie in das trainierte KI-Modell eingespeist, das den Input verarbeitet und einen Output generiert. Diese Ausgabe kann je nach Anwendung eine Prognose, eine Klassifizierung oder eine Entscheidung sein.
In einem medizinischen Kontext kann ein KI-Modell beispielsweise für die Diagnose von Krankheiten anhand medizinischer Bilder trainiert werden. Während der Inferenz würde das Modell das Bild eines neuen Patienten verarbeiten und eine Diagnose liefern. Diese könnte dann von einer medizinischen Fachkraft überprüft werden. Der gesamte Prozess muss effizient und genau sein, da Verzögerungen oder Fehler schwerwiegende Folgen haben können. Der Bedarf an Rechenleistung und Rechenressourcen ist offensichtlich, insbesondere in Szenarien, in denen das Modell große Datensätze und komplexe Aufgaben verarbeiten muss.
Die Rolle von KI-Inferenz-Engines
Eine KI-Inferenz-Engine ist eine Softwarekomponente, die die Ausführung von trainierten KI-Modellen verwaltet, um Latenz zu minimieren und die Workload-Performance zu optimieren. Diese Engines sind darauf ausgelegt, die rechenintensiven Aufgaben der Verarbeitung von Eingabedaten und der Generierung von Ausgaben zu bewältigen und sicherzustellen, dass das Modell in Echtzeit-Umgebungen effizient arbeitet. Fortschritte bei der Hardware, wie GPUs und CPUs, haben die Funktionen von Inferenz-Engines erheblich verbessert, sodass sie zunehmend komplexe und datenintensive Aufgaben bewältigen können.
NVIDIA hat beispielsweise mit seinen GPUs, die sich besonders gut für parallele Verarbeitungsaufgaben eignen, einen erheblichen Beitrag auf dem Gebiet der KI-Inferenz geleistet. Diese GPUs können die Latenz von Inferenz erheblich reduzieren und eignen sich daher ideal für Anwendungen, die Entscheidungen in Echtzeit erfordern. Darüber hinaus hat die Verbreitung von Edge Computing das Potenzial von KI-Inferenz zusätzlich erweitert. Die Verarbeitung kann näher an der Datenquelle erfolgen, wodurch die Notwendigkeit der Übertragung von Daten in zentralisierte Rechenzentren verringert und die allgemeine Performance verbessert wird.
Beispiele und Anwendungsfälle von KI-Inferenz
Die KI-Inferenz umfasst eine breite Palette von Anwendungen in verschiedenen Sektoren, die die Leistungsfähigkeit von trainierten KI-Modellen nutzen, um spezifische Probleme zu lösen. Im Gesundheitswesen wird KI-Inferenz für die Diagnose von Krankheiten, die Wirkstoffentdeckung und die Patientenüberwachung verwendet. So kann beispielsweise ein mit medizinischen Bildgebungsdaten trainiertes Deep-Learning-Modell schnell und präzise Krankheiten wie Krebs oder Pneumonie diagnostizieren und so dem medizinischen Fachpersonal wertvolle Erkenntnisse liefern.
Im Internet der Dinge (Internet of Things, IoT) spielt KI-Inferenz eine entscheidende Rolle, da mit ihrer Unterstützung intelligente Geräte autonome Entscheidungen treffen können. Beispielsweise kann ein Smart-Home-System KI-Inferenz verwenden, um Heizung und Kühlung auf der Grundlage von Belegungsmustern anzupassen. Im Rahmen eines Smart-City-Konzepts kann Inferenz dazu genutzt werden, den Verkehrsfluss zu optimieren und Staus zu reduzieren. Fortschritte bei KI-Funktionen, insbesondere bei der Objekterkennung, haben zu einer Verbesserung dieser Systeme geführt. Die Fähigkeit, Daten in Echtzeit zu verarbeiten und sofort auf die Daten zu reagieren, ist für den reibungslosen Betrieb dieser Systeme unerlässlich.
Eine weiteres wichtiges Anwendungsgebiet für KI-Inferenz bieten generative KI und LLMs (Large Language Models). Modelle wie ChatGPT, die auf Deep Learning und neuronalen Netzwerken basieren, verwenden Inferenz, um menschenähnlichen Text für Antworten auf Nutzereingaben zu generieren. Dies eröffnet neue Möglichkeiten für die Verarbeitung natürlicher Sprache und die Art und Weise, wie wir mit KI-Systemen interagieren. Dadurch werden solche Systeme intuitiver und nutzerfreundlicher.
Fazit
KI-Inferenz ist ein wichtiger Bestandteil moderner KI-Lösungen. Sie ermöglicht Entscheidungen Echtzeit und die Anwendung von trainierten Modellen auf neue, unbekannte Daten. Die Unterscheidung zwischen Training und Inferenz ist wichtig, da jede Phase ihre eigenen Anforderungen und Herausforderungen mit sich bringt. Während das Training die Entwicklung und Optimierung von Modellen umfasst, geht es bei der Inferenz darum, diese Modelle einzusetzen, um präzise und rechtzeitige Vorhersagen zu erhalten.
Angesichts der Fortschritte bei Hardware-Komponenten wie GPUs und beim Edge Computing sowie der Entwicklung optimierter Inferenz-Engines ist die Zukunft der KI-Inferenz vielversprechend. Diese Fortschritte sorgen nicht nur für eine bessere Skalierbarkeit von KI-Systemen, sondern ermöglichen es diesen Systemen auch, neue Datenherausforderungen und immer komplexere Aufgaben zu bewältigen. Im Zuge der Weiterentwicklung von KI wird die Bedeutung von effizienter Inferenz mit geringer Latenz weiter zunehmen, was Innovation fördert und in den unterschiedlichsten Branchen neue Möglichkeiten eröffnet.
Häufig gestellte Fragen
Beim Trainieren eines KI-Modells werden große Datensätze in einen Algorithmus eingespeist, um Muster zu lernen und zu identifizieren, was erhebliche Rechen- und Zeitressourcen erfordert. Die KI-Inferenz hingegen ist die Bereitstellungsphase, in der das trainierte Modell neue Daten verarbeitet, um Vorhersagen oder Entscheidungen zu treffen, wobei der Schwerpunkt auf geringer Latenz und Echtzeit-Performance liegt.
Zu den wichtigsten Schritte bei der KI-Inferenz gehören die Vorverarbeitung von Eingabedaten, mit der sicherstellt wird, dass die Daten in einem geeigneten Format vorliegen, dann die Einspeisung der Daten in das trainierte Modell und schließlich die Generierung einer Ausgabe in Form einer Vorhersage, einer Klassifizierung oder einer Entscheidung. Jeder Schritt erfordert eine sorgfältige Einschätzung der Rechenressourcen und der Recheneffizienz. Die Implementierung der passenden Architektur und der richtigen Datensysteme ist unerlässlich, damit sichergestellt ist, dass die KI effektiv mit verschiedenen Dateneingaben arbeiten und interagieren kann.
Eine KI-Inferenz-Engine ist eine Softwarekomponente, die die Ausführung von trainierten KI-Modellen verwaltet, um Latenz zu minimieren und die Workload-Performance zu optimieren. Sie erledigt die rechenintensiven Aufgaben der Verarbeitung von Eingabedaten und der Generierung von Ausgaben, wobei häufig GPUs zur Gewährleistung eines effizienten Echtzeit-Betriebs genutzt werden.
Niedrige Latenz ist bei KI-Inferenz von entscheidender Bedeutung, da Verzögerungen in Anwendungen, die Entscheidungen in Echtzeit erfordern, verheerend sein können. Das gilt zum Beispiel für autonomes Fahren, Chatbots oder intelligente Geräte. Schnelle Reaktionszeiten sorgen für einen reibungslosen und sicheren Betrieb des Systems.
KI-Inferenz findet in verschiedenen Bereichen Anwendung, etwa im Gesundheitswesen (z. B. Diagnose von Krankheiten, Wirkstoffentdeckung), im Bereich IoT (z. B. Smart-Home-Systeme, Smart Cities) und in der generativen KI (z. B. LLMs wie ChatGPT). Diese Anwendungen nutzen die Leistungsfähigkeit von trainierten Machine-Learning-Modellen, um bestimmte Probleme in Echtzeit zu lösen.
GPUs und CPUs sind für die KI-Inferenz unerlässlich, da sie die Rechenleistung bereitstellen, die zur effizienten Verarbeitung von Eingabedaten und zur Generierung von Output erforderlich ist. Insbesondere GPUs eignen sich gut für eine parallele Aufgabenverarbeitung, die die Latenz von Inferenz erheblich reduzieren kann.
Mit Edge-Computing kann KI-Inferenz näher an der Datenquelle erfolgen, was die Notwendigkeit der Übertragung von Daten in zentralisierte Rechenzentren reduziert. Das steigert die Gesamtperformance, da Latenz reduziert und die Echtzeitfunktionen von KI-Systemen verbessert werden, sodass diese Systeme effizienter und reaktionsschneller arbeiten.
Ja, KI-Inferenz wird im Gesundheitswesen häufig für Anwendungen wie Krankheitsdiagnose, Wirkstoffentdeckung und Patientenüberwachung eingesetzt. So kann beispielsweise ein mit medizinischen Bildgebungsdaten trainiertes Deep-Learning-Modell schnell und präzise Krankheiten wie Krebs oder Pneumonie diagnostizieren und so dem medizinischen Fachpersonal wertvolle Erkenntnisse liefern.
KI-Inferenz verbessert die Funktionen von IoT-Geräten, da sie ihnen ermöglicht, autonome Entscheidungen auf der Grundlage von Echtzeitdaten zu treffen. So kann beispielsweise ein Smart-Home-System mithilfe von KI-Inferenz Heizung und Kühlung auf der Grundlage von Belegungsmustern anpassen, oder eine Smart City verwendet KI-Inferenz, um den Verkehrsfluss optimieren und Staus reduzieren.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.

