
L'AI inferencing è il processo tramite il quale un modello di AI addestrato su specifici dataset acquisisce i dati di input e produce un output, come una previsione o una decisione. Si tratta dell'applicazione delle conoscenze apprese dalla fase di addestramento a nuovi dati invisibili.
L'intelligenza artificiale (AI) ha rivoluzionato numerosi settori, dall'assistenza sanitaria ai veicoli a guida autonoma, consentendo ai sistemi di prendere decisioni intelligenti in base ai dati. Il fulcro di questi sistemi basati sull'AI risiede nel processo dell'AI inferencing, una fase critica in cui vengono implementati modelli di AI addestrati per effettuare previsioni o prendere decisioni in tempo reale. Questo processo è essenziale per le applicazioni che richiedono risposte immediate, come le chatbot e le auto a guida autonoma, in cui la capacità di elaborare i dati di input e generare rapidamente output può risultare una questione di sicurezza ed efficienza.
Introduzione all'AI inferencing
L'AI inferencing è il processo tramite il quale un modello di apprendimento automatico addestrato acquisisce i dati di input e produce un output, come una previsione o una decisione. A differenza della fase di formazione, che prevede l'inserimento di grandi dataset in un algoritmo per apprendere modelli e relazioni, l'inferencing è l'applicazione di queste conoscenze apprese a dati nuovi e invisibili. Questa distinzione è fondamentale per comprendere il ruolo dell'AI inferencing nelle applicazioni reali. Ad esempio, nei veicoli a guida autonoma, il modello deve elaborare i dati dei sensori in tempo reale per decidere se è necessario sterzare, frenare e accelerare, tutte operazioni queste che richiedono una bassa latenza e un'elevata accuratezza.
Nell'ambito delle chatbot, l'AI inferencing consente l'elaborazione del linguaggio naturale (NLP) per comprendere e rispondere alle query degli utenti come in una conversazione. Questo processo decisionale in tempo reale è ciò che rende potenti e intuitive le applicazioni basate sull'AI, come chatbot e assistenti virtuali. La capacità di gestire dati invisibili e di effettuare previsioni accurate dimostra la solidità del modello di AI addestrato e l'efficienza del processo di inferencing.
Addestramento dell'AI o AI inferencing?
Lo sviluppo dei sistemi basati sull'AI prevede due fasi principali: l'addestramento dell'AI e l'AI inferencing. Durante la fase di addestramento dell'AI, i modelli di AI vengono alimentati con grandi dataset per apprendere e identificare gli schemi. Questo processo, spesso, richiede notevoli quantità di tempo e di risorse informatiche, poiché il modello deve regolare iterativamente i propri parametri per ridurre al minimo gli errori. Gli algoritmi utilizzati nell'addestramento, come le reti neurali del deep learning o apprendimento profondo, sono progettati per ottimizzare le performance del modello sui dati dell'addestramento.
Al contrario, l'AI inferencing è la fase di implementazione in cui il modello addestrato viene utilizzato per effettuare previsioni o prendere decisioni basate sui nuovi dati in entrata. L'attenzione è rivolta alla bassa latenza e alle performance in tempo reale, poiché i ritardi possono risultare dannosi in applicazioni come i veicoli a guida autonoma e i sistemi decisionali in tempo reale. I requisiti computazionali per l'inferencing sono generalmente inferiori a quelli per l'addestramento, ma richiedono comunque un uso efficiente dei processori, come GPU (Graphics Processing Unit) e CPU (Central Processing Unit), per garantire performance elevate e tempi di risposta rapidi. Per ulteriori informazioni sull'addestramento dell'AI e sull'AI inferencing, potete consultare la nostra introduzione all'apprendimento automatico e all'inferencing.
Le operazioni dell'AI inferencing
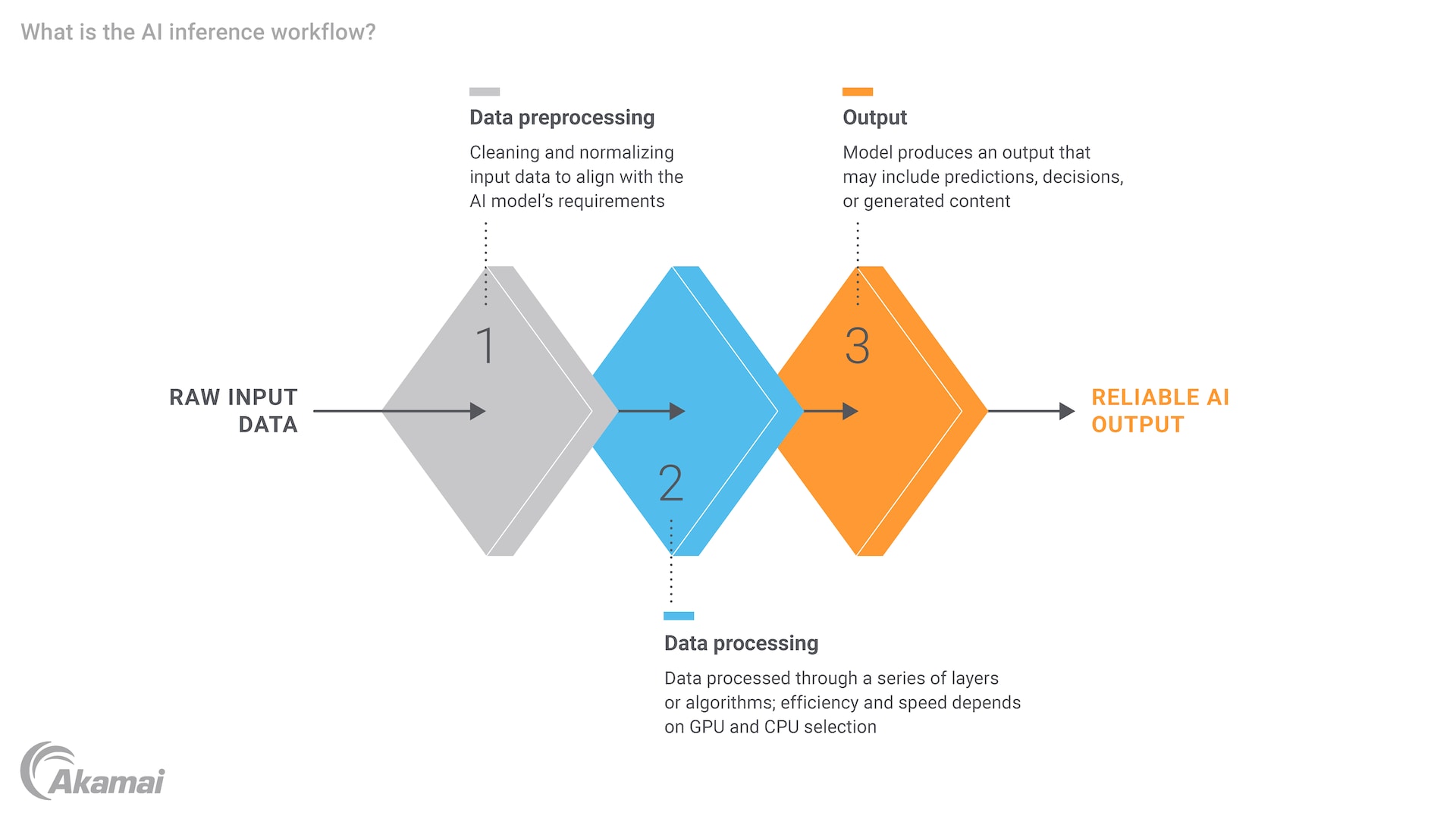
Il processo dell'AI inferencing comporta diversi passaggi fondamentali, ciascuno dei quali richiede un'attenta considerazione dell'efficienza e delle risorse computazionali. Innanzitutto, i dati di input devono essere pre-elaborati per garantire che il loro formato sia adatto al modello. In caso contrario, potrebbe essere necessario eseguire la normalizzazione dei dati, la conversione del testo in vettori numerici o il ridimensionamento delle immagini. Una volta preparati, i dati vengono inseriti nel modello di AI addestrato, che elabora l'input e genera un output. Questo risultato potrebbe essere una previsione, una classificazione o una decisione, a seconda dell'applicazione.
Ad esempio, in un ambiente sanitario, un modello di AI potrebbe essere addestrato per diagnosticare malattie sulla base di immagini mediche. Durante l'inferencing, il modello elabora l'immagine di un nuovo paziente e fornisce una diagnosi, che potrebbe essere poi riesaminata dal personale sanitario. L'intero processo deve essere efficiente e accurato, poiché ritardi o errori possono avere gravi conseguenze. La necessità di disporre di un adeguato livello di potenza e risorse computazionali è evidente, specialmente nei casi in cui il modello deve gestire grandi dataset e attività complesse.
Il ruolo dei motori di AI inferencing
Un motore di AI inferencing è un componente software che gestisce l'esecuzione di modelli di AI addestrati, ottimizzandoli per carichi di lavoro a bassa latenza e dalle performance elevate. Questi motori sono progettati per gestire le attività ad elevato utilizzo di calcolo relative all'elaborazione dei dati di input e alla generazione degli output, garantendo che il modello possa funzionare in modo efficiente negli ambienti in tempo reale. Le innovazioni introdotte nell'hardware, come GPU e CPU, hanno migliorato notevolmente le funzionalità dei motori di inferencing, consentendo loro di gestire attività sempre più complesse e ad elevato utilizzo di dati.
Ad esempio, NVIDIA ha apportato un contributo significativo al campo dell'AI inferencing con le sue GPU, particolarmente adatte per le attività di elaborazione parallela. Queste GPU possono ridurre notevolmente la latenza dell'inferencing, il che le rende ideali per le applicazioni che richiedono di prendere decisioni in tempo reale. Inoltre, l'aumento dell'Edge Computing ha ulteriormente ampliato il potenziale dell'AI inferencing, avvicinando maggiormente l'elaborazione all'origine dei dati, riducendo la necessità di trasferire i dati in data center centralizzati e migliorando le performance complessive.
Esempi e casi di utilizzo dell'AI inferencing
L'AI inferencing presenta un'ampia gamma di applicazioni in vari settori, ognuna delle quali sfrutta la potenza dei modelli di AI addestrati per risolvere problemi specifici. Nel settore sanitario, l'AI inferencing viene utilizzato per la diagnosi delle malattie, la progettazione dei farmaci e il monitoraggio dei pazienti. Ad esempio, un modello di apprendimento profondo addestrato sui dati di imaging medico consente di diagnosticare in modo rapido e accurato patologie come il cancro o la polmonite, fornendo preziose informazioni al personale sanitario.
Nell'IoT (Internet of Things), l'AI inferencing svolge un ruolo cruciale nel consentire ai dispositivi intelligenti di prendere decisioni autonome. Ad esempio, un sistema domotico potrebbe utilizzare l'AI inferencing per regolare l'impianto di condizionamento dell'aria in base al numero di persone che si trovano nell'abitazione oppure una città intelligente potrebbe utilizzarlo per ottimizzare il flusso del traffico e ridurre le congestioni. Le innovazioni nelle funzionalità dell'AI, in particolare nel rilevamento degli oggetti, hanno ulteriormente migliorato questi sistemi. La capacità di elaborare e rispondere ai dati in tempo reale è essenziale per il funzionamento ottimale di questi sistemi.
Un'altra applicazione degna di nota dell'AI inferencing si trova nel campo dell'AI generativa e dei grandi modelli linguistici (LLM). Modelli come ChatGPT, che si basano sull'apprendimento profondo e sulle reti neurali, utilizzano l'inferencing per generare testi di tipo umano in risposta agli input degli utenti. Ciò ha aperto nuove possibilità per l'elaborazione del linguaggio naturale e ha il potenziale di trasformare il nostro modo di interagire con i sistemi basati sull'AI, rendendoli più semplici e intuitivi.
Conclusione
L'AI inferencing è un componente fondamentale delle moderne soluzioni basate sull'AI perché consente di prendere decisioni in tempo reale e di applicare modelli addestrati a dati nuovi e invisibili. Comprendere la distinzione tra addestramento e inferencing è fondamentale perché ogni fase presenta una serie di requisiti e sfide. Mentre l'addestramento implica la creazione e l'ottimizzazione dei modelli, l'inferencing si concentra sulla loro implementazione per effettuare previsioni accurate e tempestive.
Il futuro dell'AI inferencing sembra promettente, con miglioramenti apportati all'hardware, tra cui le GPU e l'Edge Computing, e lo sviluppo di motori di inferencing ottimizzati. Queste innovazioni non solo miglioreranno la scalabilità dei sistemi basati sull'AI, ma consentiranno anche di gestire nuove sfide relative ai dati e attività sempre più complesse. Man mano che l'AI continua a evolversi, l'importanza di un inferencing efficiente e a bassa latenza non farà che aumentare, favorendo l'innovazione e aprendo nuove possibilità in vari settori.
Domande frequenti
L'addestramento di un modello di AI implica l'inserimento di grandi dataset in un algoritmo per apprendere e identificare i modelli, il che richiede notevoli quantità di tempo e risorse computazionali. L'AI inferencing, d'altro canto, è la fase di implementazione in cui il modello addestrato elabora i nuovi dati per effettuare previsioni o prendere decisioni, concentrandosi sulla bassa latenza e sulle performance in tempo reale.
I passaggi chiave dell'AI inferencing includono la preelaborazione dei dati di input per garantire che il loro formato sia adatto, l'inserimento dei dati nel modello addestrato e la generazione di un output, come una previsione, una classificazione o una decisione. Ogni passaggio richiede un'attenta considerazione delle risorse computazionali e dell'efficienza. L'implementazione dell'architettura e dei sistemi di dati appropriati è essenziale per garantire che l'AI possa operare e interagire in modo efficace con i vari input di dati.
Un motore di AI inferencing è un componente software che gestisce l'esecuzione di modelli di AI addestrati, ottimizzandoli per carichi di lavoro a bassa latenza e dalle performance elevate. Questo motore gestisce le attività ad elevato utilizzo di calcolo relative all'elaborazione dei dati di input e alla generazione degli output, spesso utilizzando le GPU per garantire un funzionamento efficiente in tempo reale.
La bassa latenza è fondamentale nell'AI inferencing perché i ritardi possono essere dannosi nelle applicazioni che richiedono di prendere decisioni in tempo reale, come veicoli a guida autonoma, chatbot e dispositivi intelligenti. I tempi di risposta rapidi garantiscono un funzionamento regolare e sicuro del sistema.
L'AI inferencing viene utilizzato in vari settori, tra cui quello sanitario (ad es., diagnosi di malattie, progettazione di farmaci), l'IoT (ad es., sistemi domotici, città intelligenti) e l'AI generativa (ad es., modelli LLM come ChatGPT). Queste applicazioni sfruttano la potenza dei modelli di apprendimento automatico addestrati per risolvere problemi specifici in tempo reale.
Le GPU e le CPU sono essenziali per l'AI inferencing perché forniscono la potenza di elaborazione necessaria per elaborare i dati di input e generare gli output in modo efficiente. Le GPU, in particolare, sono particolarmente adatte per le attività di elaborazione parallela, che possono ridurre notevolmente la latenza dell'inferencing.
L'Edge Computing consente all'AI inferencing di avvicinarsi maggiormente all'origine dei dati, riducendo la necessità di spostare i dati in data center centralizzati. Ciò migliora le performance complessive riducendo la latenza e migliorando le funzionalità in tempo reale dei sistemi basati sull'AI, rendendoli più efficienti e reattivi.
Sì, l'AI inferencing è ampiamente utilizzato nel settore sanitario per applicazioni quali diagnosi di malattie, progettazione di farmaci e monitoraggio dei pazienti. Ad esempio, un modello di apprendimento profondo addestrato sui dati di imaging medico consente di diagnosticare in modo rapido e accurato patologie come il cancro o la polmonite, fornendo preziose informazioni al personale sanitario.
L'AI inferencing migliora le funzionalità dei dispositivi IoT consentendo loro di prendere decisioni autonome sulla base dei dati in tempo reale. Ad esempio, un sistema domotico può utilizzare l'AI inferencing per regolare l'impianto di condizionamento dell'aria in base al numero di persone che si trovano nell'abitazione oppure una città intelligente può ottimizzare il flusso del traffico e ridurre le congestioni.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.

