
Big Data bezieht sich auf extrem große und komplexe Datensätze, die mit herkömmlichen Tools nicht effektiv verwaltet, verarbeitet oder analysiert werden können. Es umfasst strukturierte, halbstrukturierte und unstrukturierte Daten, die aus verschiedenen Quellen wie sozialen Medien, IoT-Geräten und Transaktionssystemen generiert werden.
Big Data hat die moderne Welt revolutioniert und alles von personalisierten Produktempfehlungen bis hin zu Fortschritten im Gesundheitswesen beeinflusst. Jeder Klick, jede Wischbewegung und jede Transaktion, die wir durchführen, trägt zur Ausweitung der digitalen Datenspuren bei. Diese Datenexplosion verspricht eine vernetztere, effizientere und intelligentere Welt. Im Gegensatz zu traditionellen Datensystemen, die mit komplexen Datensätzen Schwierigkeiten haben, kann Big Data aufgrund seiner Vielfalt, Skalierbarkeit und Geschwindigkeit erfolgreich genutzt werden. Von der Weiterentwicklung von Algorithmen für maschinelles Lernen bis hin zur Entscheidungsfindung in Echtzeit – die Anwendungen von Big Data zur Lösung von Problemen und zur Verbesserung von Erfahrungen sind so umfangreich und vielfältig wie ihre Quellen.
Big Data definiert
Big Data bezieht sich auf die großen Datenmengen, die die digitale Welt mit hoher Geschwindigkeit erzeugt, darunter strukturierte, halbstrukturierte und unstrukturierte Daten. Diese erfordern fortschrittliche Tools für ihre Speicherung, Analyse und Verarbeitung. Big Data umfasst Datensätze, die herkömmliche Datensysteme wie Tabellen oder relationale Datenbanken möglicherweise nicht mehr effektiv verwalten können. Stattdessen stützt sich Big Data auf spezialisierte Plattformen wie Hadoop, Data Lakes und Cloud Computing.
Die Bedeutung von Big Data
Big Data ist ein geschäftskritisches Tool, mit dem Unternehmen bessere, schnellere und fundiertere Entscheidungen treffen können. Durch die Analyse großer Datensätze aus verschiedenen Datenquellen können Unternehmen Trends und Korrelationen ermitteln und Kundenpräferenzen verstehen, die bisher nicht erkennbar waren. Diese wertvollen Erkenntnisse verbessern nicht nur die Entscheidungsfindung, sondern ermöglichen Unternehmen auch, Marktveränderungen vorherzusagen, Strategien anzupassen und einen Wettbewerbsvorteil zu erzielen. In Branchen wie Finanzen, Gesundheit und Einzelhandel fördert Big Data Innovationen, verringert Risiken und ermöglicht Unternehmen Flexibilität in einer sich schnell verändernden Welt.
Arten von Big Data
Big Data gibt es in drei Hauptformen, die jeweils einzigartige Herausforderungen und Möglichkeiten für Verarbeitung und Analyse bieten.
- Strukturierte Daten: Diese Art von Daten ist hochgradig organisiert und in vordefinierten Formaten gespeichert, in der Regel in relationalen Datenbanken. Strukturierte Daten lassen sich mit herkömmlichen Tools wie SQL einfach durchsuchen, abfragen und analysieren. Beispiele sind Kundendatensätze, Finanztransaktionen und Bestandsdaten. Da sie in gut organisierter Form vorliegen, sind diese Daten für Systeme wie Business Intelligence-Plattformen und Data Warehouses geeignet, die auf konsistente und vorhersagbare Datenformate angewiesen sind.
- Unstrukturierte Daten: Unstrukturierte Daten folgen keinem spezifischen Format oder Schema, was die Speicherung und Analyse erschwert. Beispiele sind Textdateien, Bilder, Videos, E-Mails und Beiträge in sozialen Medien. Diese Art von Daten macht den Großteil der täglich generierten großen Datenmengen aus und erfordert spezielle Tools wie Algorithmen für maschinelles Lernen oder die Verarbeitung natürlicher Sprache (NLP), um aussagekräftige Erkenntnisse gewinnen zu können. Unstrukturierte Daten sind von entscheidender Bedeutung für Branchen wie Medien, Marketing und Gesundheitswesen, in denen umfangreiche kontextbezogene Informationen entscheidend sind.
- Halbstrukturierte Daten: Halbstrukturierte Daten bilden einen mittleren Bereich zwischen strukturierten und unstrukturierten Daten. Sie weisen Elemente von beiden auf, zum Beispiel identifizierbare Felder oder Tags innerhalb eines ansonsten flexiblen Formats. Beispiele sind XML- und JSON-Dateien sowie Sensordaten von IoT-Geräten. Zwar fehlt hier die stringente Organisation strukturierter Daten, doch halbstrukturierte Daten sind einfacher zu verarbeiten als gänzlich unstrukturierte Daten und werden häufig in Webanwendungen, im E-Commerce und in Initiativen zur Datenintegration verwendet.
Quellen von Big Data
Big Data wird aus einer Vielzahl von Datenquellen generiert, die sowohl digitale als auch physische Bereiche umfassen.
- Social-Media-Plattformen: Plattformen wie Facebook, Twitter, Instagram und LinkedIn erzeugen täglich hohe Mengen an Rohdaten durch Beiträge, Kommentare, Likes und Multimedia-Inhalte. Diese unstrukturierten Daten bieten Einblicke in das Nutzerverhalten, die Stimmungsanalyse und Interaktionstrends und unterstützen Unternehmen bei der Optimierung ihrer Kundenerlebnisse und Marketingstrategien.
- IoT-Geräte (Internet of Things): Milliarden von vernetzten Geräten wie Smart-Home-Systeme, Wearables und Industriesensoren erzeugen fortlaufend Sensordaten. Diese Maschinendaten ermöglichen Anwendungen in den Bereichen vorausschauende Wartung, Umgebungsüberwachung und intelligente Stadtplanung. Dabei stellt die Echtzeit-Verarbeitung sicher, dass Informationen rechtzeitig verfügbar sind.
- E-Commerce- und Transaktionsdaten: Online-Einzelhandelsplattformen, Banksysteme und Point-of-Sale-Terminals generieren Transaktionsdaten mit Kaufdetails, Kundenverhalten und Preistrends. Mit diesen Daten können Unternehmen den Bestand optimieren, personalisierte Empfehlungen erstellen und die Betriebseffizienz steigern.
- Streaming-Datenquellen: Datenströme aus Echtzeitsystemen wie Finanzmärkten, Wetterbeobachtung und Live-Sport-Updates liefern in hohem Tempo neue Einblicke.
- Medien und Internet: Nachrichtenkanäle, Videoplattformen und Websites produzieren gewaltige Mengen unstrukturierter Daten in Form von Artikeln, Videos, Bildern und Kommentaren. Darüber hinaus liefern Webtraffic-Daten einschließlich Clickstream-Daten und Sitzungsprotokollen Erkenntnisse zu Nutzerverhalten und Trends. Diese Erkenntnisse sind für die Verbesserung von Nutzeroberflächen und digitalen Marketingstrategien unerlässlich.
- Open Source: Öffentlich verfügbare Daten aus staatlichen Datenbanken, Forschungsstudien und Open-Access-Plattformen liefern eine Fülle von Informationen für Analysen. Daten wie demografische Statistiken, Klimadaten und wissenschaftliche Forschungsdatenspeicher können beispielsweise von Organisationen für die Erstellung von Richtlinien, für Innovationen und für soziale Initiativen verwendet werden.
Die fünf „V“ von Big Data
Big Data zeichnet sich durch fünf Hauptattribute aus, die oft als die fünf „V“ bezeichnet werden.
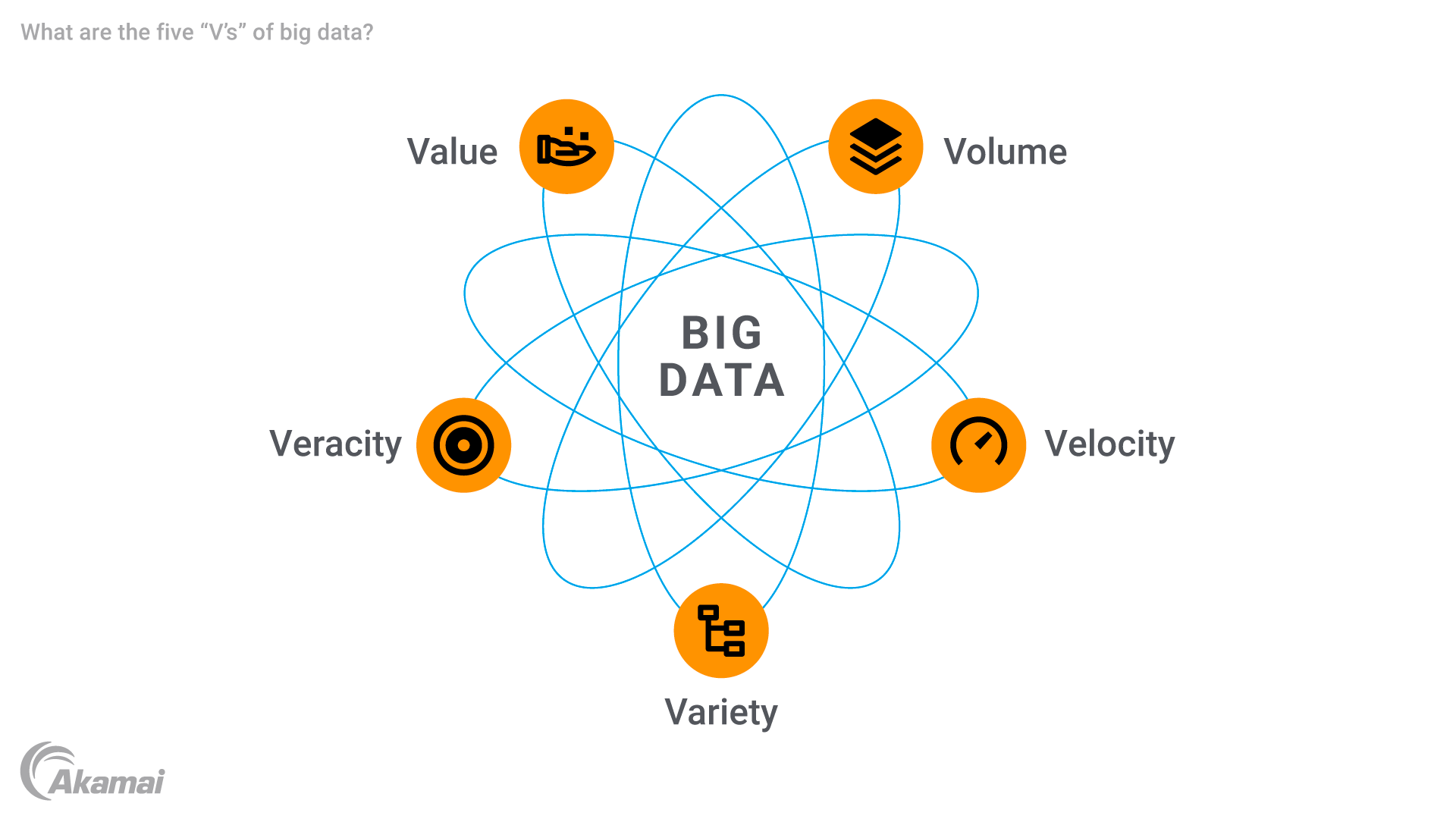
- Volumen: Das charakteristischste Merkmal von Big Data ist seine immense Größe. Unternehmen arbeiten mit Datenmengen, die in Terabyte, Petabyte oder sogar Exabyte angegeben werden. Diese enorme Menge an Daten erfordert fortschrittliche Datenspeicherlösungen, um eine effiziente Speicherung und Verarbeitung möglich zu machen.
- Geschwindigkeit (Velocity): Big Data wird in unglaublicher Geschwindigkeit generiert und verarbeitet, oft in Echtzeit. Ob beim Streaming von IoT-Geräten, Social-Media-Feeds oder Finanztransaktionen: Der schnelle Datenfluss erfordert robuste Technologien, die die Hochgeschwindigkeitsdatenverarbeitung bewältigen können, um zeitnahe Einblicke zu gewährleisten. Geschwindigkeit ist besonders wichtig bei Anwendungen wie Betrugserkennung und vorausschauender Wartung, bei denen Verzögerungen zu erheblichen Verlusten führen können.
- Vielfalt: Big Data ist auch durch eine Vielzahl von Datentypen gekennzeichnet. Beispiele reichen von herkömmlichen relationalen Datenbankdatensätzen bis hin zu Multimedia-Inhalten, Sensordaten und Metadaten. Diese Vielfalt erfordert ausgeklügelte Tools für die Datenintegration und -analyse, da sich herkömmliche Systeme für die Handhabung solcher komplexen Datensätze nicht gut eignen.
- Richtigkeit (Veracity): Angesichts der riesigen Mengen an erfassten Rohdaten ist die Sicherstellung von Datenqualität und -genauigkeit eine große Herausforderung. Inkonsistente, unvollständige oder ungenaue Daten können die Zuverlässigkeit von Prognosen und anderen Erkenntnissen erheblich beeinträchtigen. Die Richtigkeit unterstreicht die Bedeutung der Bereinigung, Validierung und Verwaltung von Daten, um Vertrauen in die Analyseergebnisse aufzubauen.
- Wert (Value): Das ultimative Ziel von Big Data besteht darin, wertvolle Erkenntnisse zu gewinnen, die die Entscheidungsfindung vorantreiben, den Betrieb optimieren und Chancen schaffen können. Die Verwendung von Big Data ermöglicht Unternehmen, Rohdaten zu erfassen und umsetzbare Ergebnisse zu entwickeln, die das Kundenerlebnis verbessern, die Betriebseffizienz steigern oder Innovationen in Bereichen wie dem Gesundheitswesen und dem Einzelhandel vorantreiben können.
Die Geschichte und Entwicklung von Big Data
Das Konzept von Big Data entwickelte sich in den 1990er Jahren, als sich Unternehmen mit der Verwaltung und Analyse großer Datenmengen konfrontiert sahen, die die Funktionen herkömmlicher Systeme, wie z. B. relationale Datenbanken, überforderten. Anfänglich wurde die Notwendigkeit einer skalierbaren Speicherung und Verarbeitung betont, da Unternehmen immer mehr Rohdaten aus unterschiedlichen Quellen erfassten.
Die Entwicklung von Technologien wie Hadoop (2006) beschleunigte die Entwicklung von Big Data. Das verteilte Framework von Hadoop ermöglichte die Speicherung und Verarbeitung großer Datenmengen über mehrere Server hinweg und überwindet die Einschränkungen zentralisierter Systeme. Gleichzeitig wurden NoSQL-Datenbanken eingeführt, um unstrukturierte und halbstrukturierte Daten flexibler und schneller zu verarbeiten und so die Grundlage für moderne Big-Data-Analysen zu bilden.
Der Anstieg des Cloud Computing in den 2010er Jahren hat das Big Data Management weiter verändert. Mit Plattformen wie AWS und Google Cloud konnten Unternehmen die Datenspeicherung und -verarbeitung ohne erhebliche Infrastrukturinvestitionen skalieren.
Die Einführung des Internets der Dinge (IoT) führte zu einem Anstieg der Echtzeit-Sensordaten, was die globale Datenproduktion exponentiell erhöhte. Fortschrittliche Technologien wie Streaming-Analysen, KI-gestützte Tools und Algorithmen für maschinelles Lernen wurden entwickelt, um diese Komplexität zu bewältigen.
Derzeit entwickelt sich Big Data durch Innovationen in den Bereichen künstliche Intelligenz, Edge Computing und Data Science weiter.
Big Data-Herausforderungen
Big Data bietet enorme Chancen, bringt aber auch technische, organisatorische und finanzielle Herausforderungen mit sich.
- Datenverwaltung und -integration: Die Integration verschiedener Datenquellen in einheitliche Big-Data-Plattformen wie Data Lakes, Data Warehouses und Streaming-Systeme ist komplex. Schlechte Verwaltung führt zu Ineffizienzen, Duplizierung und verpassten Erkenntnissen.
- Datenqualität und Variabilität: Big Data enthält oft inkonsistente oder unvollständige Informationen, insbesondere aus unstrukturierten Datenquellen wie sozialen Medien. Die Aufrechterhaltung der Qualität und der Umgang mit der Variabilität der Datenpunkte sind entscheidend, um Fehler bei der Datenanalyse zu vermeiden.
- Bedarf an Fachkräften: Der Bedarf an Fachwissen in den Bereichen Big Data Analytics, maschinelles Lernen und Data Science hat zu einer Kompetenzlücke geführt, die erhebliche Investitionen in die Rekrutierung oder Schulung von Data Scientists und Datenanalysten erforderlich macht.
- Infrastrukturkosten: Die Verwaltung großer Datenmengen erfordert kostspielige Lösungen wie Cloud Computing, Hadoop und NoSQL-Datenbanken, insbesondere für die Echtzeitverarbeitung und -speicherung.
- Sicherheit und Datenschutz: Die Gewährleistung der Sicherheit sensibler Rohdaten von IoT-Geräten und aus anderen Quellen ist unerlässlich. Unternehmen stehen vor Herausforderungen in Bezug auf Verschlüsselung, Datenschutz-Compliance und sichere Speicherung.
- Skalierbarkeit und Flexibilität: Mit zunehmendem Datenwachstum müssen Systeme skaliert werden, ohne Leistung zu verlieren. Unternehmen müssen sich an neue Big-Data-Technologien und -Anforderungen anpassen.
Wie Big Data funktioniert
In Unternehmen wird Big Data in mehreren Phasen verarbeitet, die es möglich machen, riesige Informationsmengen zu sammeln, zu speichern und zu analysieren, um Rohdaten in verwertbare Erkenntnisse umzuwandeln.
- Datenerfassung: Der Prozess beginnt mit der Erfassung von Daten aus Quellen wie IoT-Geräten, die Sensordaten in Echtzeit generieren, und Social-Media-Plattformen, wobei unstrukturierte Daten wie Beiträge und Videos erzeugt werden. Weitere Quellen sind Transaktionssysteme, mobile Apps und Streaming-Daten von Live-Events. Dadurch wird sichergestellt, dass ausreichend Daten für erweiterte Analysen zur Verfügung stehen.
- Datenspeicherung: Die gesammelten Daten werden in Data Lakes gespeichert, die für verschiedene Rohformate entwickelt wurden, einschließlich strukturierter, halbstrukturierter und unstrukturierter Daten. Data Warehouses organisieren Daten für spezifische analytische Anforderungen, während Cloud-Computing-Plattformen eine skalierbare, kostengünstige Speicherung für die Verwaltung großer Datenmengen bieten.
- Datenverarbeitung: Tools wie Hadoop und Spark verarbeiten verteilte Daten, indem sie in verwaltbare Chunks aufgeteilt werden. Cloudplattformen bieten auch Ressourcen für die Bereinigung, Transformation und Integration von Daten, um die Datenqualität zu gewährleisten. Dieser Schritt bereitet Daten auf prädiktive Analysen und andere fortschrittliche Anwendungen vor.
- Datenvisualisierung: Verarbeitete Daten werden mithilfe von Tools wie Tableau und Power BI präsentiert, die Dashboards und visuelle Hilfsmittel wie Diagramme und Heatmaps verwenden. Diese vereinfachen komplexe Datensätze und ermöglichen Entscheidungsträgern die Untersuchung von Trends und Korrelationen, was eine schnellere und zuverlässigere Entscheidungsfindung ermöglicht.
Anwendungen und Anwendungsfälle von Big Data
Big Data verändert Branchen weltweit, liefert umsetzbare Erkenntnisse, steigert die Effizienz und fördert Innovationen.
- Gesundheitswesen: Big Data ermöglicht Prognosemodelle und Patientenüberwachung in Echtzeit durch Sensordaten von tragbaren Geräten wie Smartwatches. Krankenhäuser verwenden große Datenmengen, um Behandlungspläne zu personalisieren, genetische Informationen zu analysieren und Operationen zu optimieren, wodurch die Wartezeit der Patienten verkürzt und die Versorgung verbessert wird.
- Business Intelligence und Einzelhandel: Unternehmen nutzen Big-Data-Analysen, um Preisgestaltungsstrategien zu verfeinern, Nachfrage zu prognostizieren und Marketing zu personalisieren. E-Commerce-Plattformen wie Amazon optimieren den Lagerbestand und passen die Preise dynamisch an, während Transaktionsdaten die Betrugserkennung in Finanzdiensten unterstützen.
- KI und Big Data: KI-Systeme sind auf große Datensätze angewiesen, um Modelle für Bilderkennung, natürliche Sprachverarbeitung und Betrugserkennung zu trainieren. Selbstfahrende Autos und virtuelle Assistenten wie Alexa nutzen Big Data, um die Entscheidungsfindung und Personalisierung zu verbessern.
- IoT (Internet of Things): IoT-Geräte generieren Echtzeit-Datenströme zur Performance-Optimierung und vorausschauenden Wartung. Intelligente Thermostate empfehlen energiesparende Einstellungen, und die Landwirtschaft verwendet IoT-Sensoren zur Überwachung der Bodenfeuchte und zur Verbesserung der Effizienz.
- Lieferkette und Logistik: Datenströme von GPS- und RFID-Sensoren verbessern die Sendungsverfolgung, die Routenoptimierung und die Bestandsverwaltung. Prädiktive Analysen stellen sicher, dass die richtigen Produkte auf Lager sind. Sie sparen Kosten und verbessern die Liefergenauigkeit.
- Finanzen und Bankwesen: Big Data hilft bei der Erkennung von Betrug, der Verbesserung des Risikomanagements und der Kreditbewertung. Algorithmen analysieren Transaktionshistorien auf Anomalien hin, und Investmentbanken nutzen sie für algorithmischen Handel und Preisprognosen.
- Medien- und Unterhaltungsbranche: Plattformen wie Netflix nutzen Big Data, um Inhalte zu empfehlen und die Interaktion durch die Analyse der Benutzerpräferenzen zu verbessern. Medienunternehmen optimieren Werbestrategien, indem sie Zielgruppen mithilfe von Social-Media-Analysen ansprechen.
- Fertigungsindustrie: Sensordaten von Geräten werden in Echtzeit analysiert, um Ausfälle vorherzusagen und Wartungsarbeiten zu planen. Big Data liefert auch Informationen zur Produktkonstruktion, indem Kundenfeedback und Nutzungsmuster ausgewertet werden.
- Bildungswesen: Big Data personalisiert Lernerfahrungen durch die Analyse von Bewertungen und Interaktionskennzahlen. Es unterstützt Universitäten bei der Optimierung von Einschreibungsprognosen und der effizienten Zuweisung von Ressourcen.
- Energie- und Versorgungssektor: Big Data optimiert den Energieverbrauch und integriert erneuerbare Quellen. Intelligente Stromnetze nutzen Echtzeitüberwachung, und Raffinerien analysieren seismische Daten, um Kosten und Umweltauswirkungen zu reduzieren.
Wichtige Big-Data-Lösungen und -Technologien
Für eine effektive Verwaltung von Big Data sind fortschrittliche Tools und Technologien für die Speicherung, Verarbeitung, Analyse und Visualisierung erforderlich, um verwertbare Erkenntnisse aus großen, komplexen Datensätzen zu gewinnen.
- Datenspeicherlösungen bilden die Grundlage für die Verwaltung von Big Data. Data Lakes speichern unverarbeitete Rohdaten, wobei strukturierte, halbstrukturierte und unstrukturierte Daten einbezogen werden. Data Warehouses dagegen organisieren Daten für einfache Abfragen und Berichte. Skalierbare und kostengünstige Cloudplattformen bewältigen effizient steigende Datenmengen.
- Datenverarbeitungs- und -analysetools wandeln Rohdaten in nutzbare Erkenntnisse um. Frameworks wie Hadoop ermöglichen die verteilte Verarbeitung großer Datensätze, während sich Apache Spark auf die Datenverarbeitung in Echtzeit spezialisiert hat und maschinelles Lernen unterstützt. ETL-Tools (Extract, Transform, Load) wie Talend bereiten Daten für die Analyse vor, indem sie die Daten auf optimale Weise extrahieren, transformieren und laden.
- Datenbanken für Big Data decken verschiedene Formate ab. NoSQL-Datenbanken wie MongoDB und Cassandra verwalten unstrukturierte Daten mit Skalierbarkeit, während relationale Datenbanken wie MySQL strukturierte Daten effektiv verarbeiten.
- Tools zur Datenvisualisierung machen Erkenntnisse zugänglich. Tools wie Tableau und Power BI erstellen interaktive Dashboards und vereinfachen komplexe Datensätze. Benutzerdefinierte Visualisierungen werden mit Tools wie D3.js für bestimmte Webanwendungen erstellt.
- Big-Data-Analyseplattformen wie Google BigQuery und Amazon Redshift ermöglichen schnelle Abfragen und Analysen, während umfassende Systeme wie Cloudera die Speicherung, Verarbeitung und Analysen in einer Lösung kombinieren.
- KI und Tools für maschinelles Lernen stützen sich bei der Modellentwicklung auf Big Data. Frameworks wie TensorFlow und PyTorch verarbeiten riesige Datensätze, während Plattformen wie Google AutoML die KI für nicht-Experten zugänglich machen.
- Streaming- und Echtzeittechnologien wie Apache Kafka verwalten Echtzeit-Datenströme von IoT-Geräten und sozialen Medien, während Flink Analysen für sofortige Erkenntnisse bietet.
- Sicherheits- und Governance-Lösungen sorgen für Sicherheit und Compliance. Verschlüsselungstools schützen sensible Daten, und Plattformen wie Collibra gewährleisten die Datenqualität und die Einhaltung gesetzlicher Vorschriften.
- Integrationstools wie Apache NiFi automatisieren die Datenverschiebung zwischen Systemen und ermöglichen so eine nahtlose Zusammenarbeit und eine effektive Verwaltung komplexer Datenökosysteme.
Häufig gestellte Fragen
Big Data unterstützt Unternehmen dabei, fundierte Entscheidungen zu treffen, Trends zu erkennen, die Kundenerfahrung zu verbessern und den Betrieb zu optimieren. Branchen wie das Gesundheitswesen, die Finanzbranche und der Einzelhandel profitieren von einer höheren Innovations- und Wettbewerbsfähigkeit.
Big Data wird aus den unterschiedlichsten Quellen generiert, darunter soziale Medien, IoT-Geräte, E-Commerce-Plattformen, Finanztransaktionen, Streaming-Daten und öffentliche Datenbanken.
Ein Data Lake speichert Rohdaten in ihrem nativen Format und bietet Flexibilität im Hinblick auf unterschiedliche Anwendungsfälle. Ein Data Warehouse organisiert Daten in strukturierten Formaten, um Abfragen und Business Intelligence-Anwendungen zu vereinfachen.
Zu den Herausforderungen gehören die Verwaltung der Datenqualität, die Gewährleistung der Sicherheit, die Integration verschiedener Quellen, der Umgang mit Infrastrukturkosten und die Suche nach Fachleuten zur Analyse und Interpretation der Daten.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.

