
ビッグデータとは、従来のツールでは効果的に管理、処理、分析できない、非常に大規模で複雑なデータセットを指します。これには、ソーシャルメディア、IoT デバイス、トランザクションシステムなどのさまざまなソースから生成される、構造化データ、半構造化データ、非構造化データが含まれます。
ビッグデータは、パーソナライズされたお勧め商品からヘルスケアの進歩まで、あらゆるものに活用されており、現代社会を変革しています。クリックやスワイプ、トランザクションを行うたびに、誰もが情報の拡大し続けるデジタルフットプリントに寄与しています。このようなデータの爆発的増加は、より接続された、効率的でインテリジェントな世界への可能性を秘めています。複雑なデータセットに苦慮している従来のデータシステムとは異なり、ビッグデータは多様性、規模、スピードを活かして成長を遂げています。ビッグデータは、機械学習アルゴリズムの進歩からリアルタイムの意思決定まで、問題の解決や体験向上のために使用されており、そのアプリケーションもソース同様に膨大で多様性に富んでいます。
ビッグデータ:定義
ビッグデータとは、デジタル世界で高速に生成される大量の(構造化、半構造化、非構造化)データを指し、その保存、分析、処理には高度なツールが必要です。これには、スプレッドシートやリレーショナルデータベースなど従来のデータシステムでは効果的に管理できないデータセットが含まれます。このため、ビッグデータは Hadoop、データレイク、クラウドコンピューティングなど、専用プラットフォームに依存しています。
ビッグデータの重要性
ビッグデータは、組織がより適切かつ迅速に、より多くの情報に基づいた意思決定を行うことを可能にする、ビジネスクリティカルなツールです。多様なデータソースからの大規模なデータセットを分析することで、企業はこれまで検知できなかったトレンドや相関関係を特定し、顧客の嗜好を把握することができます。これらの貴重な知見は、意思決定の強化に加えて、組織が市場の変化を予測し、戦略を適応させ、競争力を獲得するためにも役立ちます。金融、ヘルスケア、小売などの業界では、ビッグデータを活用することでイノベーションを促進し、リスクを軽減できるだけでなく、急速に変化する世界で組織がアジリティを維持することが可能になります。
ビッグデータの種類
ビッグデータには主に 3 つの形態があり、それぞれが処理と分析に固有の課題と機会をもたらします。
- 構造化データ:このタイプのデータは高度に整理され、予め定義された形式で保存されるもので、通常はリレーショナルデータベースに格納されます。構造化データは、SQL など従来のツールを使用して簡単に検索、クエリー、分析することができます。例としては、顧客レコード、金融取引、在庫データなどがあります。きちんと整理されているため、ビジネス・インテリジェンス・プラットフォームやデータウェアハウスなど、一貫性のある予測可能なデータ形式に依存するシステムに適しています。
- 非構造化データ:非構造化データは特定の形式やスキーマに従っていないため、保存と分析がより困難になります。例としては、テキストファイル、画像、動画、電子メール、ソーシャルメディアの投稿などがあります。このタイプのデータは、日々生成される大量の情報の大部分を占めており、有意義な知見を抽出するためには、機械学習アルゴリズムや自然言語処理(NLP)などの専用ツールが必要です。非構造化データは、豊富なコンテキスト情報が鍵となるメディア、マーケティング、ヘルスケアなどの業界にとって重要です。
- 半構造化データ:半構造化データは、構造化データと非構造化データの中間を表します。柔軟な形式の中の識別可能なフィールドやタグなど、両方の要素が含まれます。例としては、XML、JSON ファイル、IoT デバイスからのセンサーデータなどがあります。構造化データのように厳格に整理されてはいませんが、半構造化データは純粋な非構造化データよりも処理が容易で、Web アプリケーション、e コマース、データ統合などのイニシアチブでよく使用されます。
ビッグデータのソース
ビッグデータは、デジタル領域と物理領域の両方にまたがる広範なデータソースから生成されます。
- ソーシャル・メディア・プラットフォーム:Facebook、Twitter、Instagram、LinkedIn などのプラットフォームは、投稿、コメント、「いいね!」、マルチメディアコンテンツを通じて、毎日大量の生データを生成しています。この非構造化データは、ユーザーのふるまい、感情分析、エンゲージメントの傾向に関する知見を提供し、企業による顧客体験やマーケティング戦略の改善に役立ちます。
- IoT(モノのインターネット)デバイス:スマート・ホーム・システム、ウェアラブル、産業用センサーなど、数十億台のコネクテッドデバイスがセンサーデータを継続的に生成します。この機械データにより、リアルタイム処理とタイムリーな知見の獲得が実現され、予知保全、環境監視、スマートシティ計画などのアプリケーションが可能になります。
- e コマースと取引データ:オンライン小売プラットフォーム、銀行システム、POS 端末は、購入の詳細、顧客のふるまい、価格の傾向など、取引データを生成します。このデータは、在庫の最適化、パーソナライズされたお勧めの作成、運用効率の向上に役立ちます。
- ストリーミング・データ・ソース:金融市場、気象監視、ライブスポーツの最新情報などのリアルタイムシステムからのデータストリームは、動的な知見をもたらします。
- メディアと Web:ニュース配信、動画プラットフォーム、Web サイトは、記事、動画、画像、コメントなどの形式で、膨大な量の非構造化データを提供します。さらに、クリックストリームやセッションログなどの Web トラフィックデータは、ユーザーのふるまいや傾向に関する知見を提供します。これらは、ユーザーインターフェースやデジタルマーケティング戦略の改善に不可欠です。
- オープンソース:政府のデータベース、研究調査、オープンアクセスプラットフォームから公開されているデータは、分析に豊富な情報を提供します。たとえば、組織は人口統計データ、気候データ、科学研究リポジトリなどのデータをポリシー作成やイノベーション、社会的イニシアチブに使用することができます。
ビッグデータの 5 つの「V」
ビッグデータは 5 つの主要な属性で特徴付けられ、これらはよく 5 つの「V」と呼ばれます。
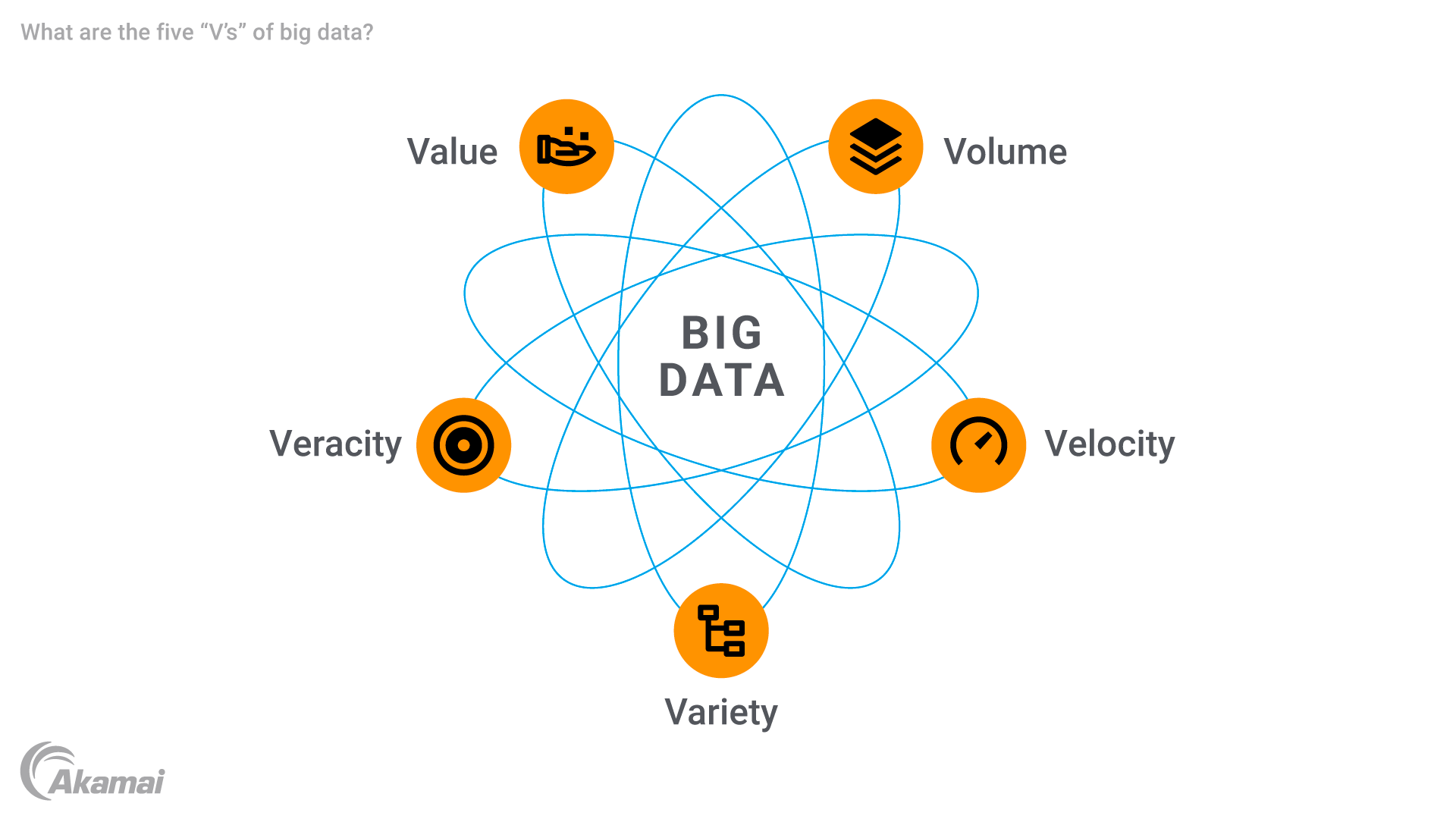
- 量(Volume):ビッグデータの最大の特徴は、その規模の大きさです。組織は、テラバイト、ペタバイト、さらにはエクサバイト単位で表される情報量を取り扱います。この膨大な量のデータを効率的に保存して処理するためには、高度なデータ・ストレージ・ソリューションが必要です。
- 速度(Velocity):ビッグデータは驚くほどのスピードで、多くの場合リアルタイムで生成・処理されます。IoT デバイス、ソーシャル・メディア・フィード、金融取引のどれからストリーミングする場合でも、タイムリーな知見を得るためには、高速なデータフローに高速なデータ処理で対応できる堅牢なテクノロジーが必要です。速度は、不正検知や予知保全など、遅延が大きな損失につながる可能性のあるアプリケーションでは特に重要です。
- 多様性(Variety):ビッグデータは、幅広いデータタイプによっても特徴付けられます。例としては、従来のリレーショナル・データベース・レコードから、マルチメディアコンテンツ、センサーデータ、メタデータまで多岐にわたります。従来のシステムでは、こういった複雑なデータセットを十分に処理できません。この多様性に対応するためには、データ統合と分析のための高度なツールが必要です。
- 正確性(Veracity):大量の生データが収集されるため、データの品質と正確性を確保することが大きな課題となります。一貫性のない、不完全な、あるいは不正確なデータは、予測分析やその他の知見の信頼性低下を招く可能性があります。正確性は、データのクリーニング、バリデーション、管理を通じて、分析結果に対する信頼を構築することの重要性を際立たせています。
- 価値(Value):ビッグデータの最終的な目標は、意思決定の促進、業務の最適化、機会創出に役立つ貴重な知見を引き出すことです。ビッグデータを使用することで、組織は生の情報を取得して、顧客体験の向上や運用効率の強化、ヘルスケアや小売などの分野におけるイノベーションの推進につながる実用的な成果を生み出すことができます。
ビッグデータの歴史と進化
ビッグデータの概念は、組織がリレーショナルデータベースなどの従来のシステムの機能を超える大規模なデータセットの管理と分析に直面していた 1990 年代に生まれました。初期の議論では、企業が多様なソースからより多くの生データを収集するようになるに伴い、スケーラブルなストレージと処理の必要性が強調されました。
2006 年の Hadoop のようなテクノロジーの開発により、ビッグデータの進化が加速しました。Hadoop の分散型フレームワークにより、複数のサーバーにわたる大規模なデータセットの保存・処理が可能になり、集約型システムの制約が克服されました。同時に、NoSQL データベースが導入され、非構造化データや半構造化データをより柔軟かつ高速に処理できるようになり、現代のビッグデータ分析の基盤が形成されました。
2010 年代に台頭したクラウドコンピューティングは、ビッグデータ管理をさらに変革しました。AWS や Google Cloud などのプラットフォームを使用することで、企業はインフラに多額の投資をすることなく、データの保存と処理をスケーリングすることが可能になりました。
モノのインターネット(IoT)の出現により、リアルタイムのセンサーデータが急増し、世界でデータの産出が飛躍的に増加しました。ストリーミング分析、AI を活用したツール、機械学習アルゴリズムなどの高度なテクノロジーは、この複雑さに対処するために開発されました。
今日、ビッグデータは人工知能、エッジコンピューティング、データサイエンスのイノベーションによって進化し続けています。
ビッグデータの課題
ビッグデータは大きな機会をもたらしますが、技術的、組織的、財務的な課題ももたらします。
- データ管理と統合:データレイク、データウェアハウス、ストリーミングシステムなどの統一されたビッグデータのプラットフォームに、多様なデータソースを統合することは複雑な作業です。適切に管理しなければ、非効率性や重複、知見の逸失につながります。
- データの品質とばらつき:特にソーシャルメディアのような非構造化データからのビッグデータには、一貫性のない情報や不完全な情報が含まれていることがよくあります。データ分析のエラーを回避するためには、品質を維持し、データポイントのばらつきを管理することが不可欠です。
- スキルを備えた従業員の必要性:ビッグデータ分析、機械学習、データサイエンスの専門知識に対するニーズによってスキルギャップが生まれ、データサイエンティストやデータアナリストの採用やトレーニングに多額の投資が必要になります。
- インフラコスト:大量のデータを管理するためには、特にリアルタイムの処理と保存のために、クラウドコンピューティングや Hadoop、NoSQL データベースなどの高額なソリューションが必要となります。
- セキュリティとプライバシー:IoT デバイスやその他のソースから取得される機微な生データのセキュリティを確保することが不可欠です。組織は、暗号化、プライバシーコンプライアンス、安全なストレージに関する課題に直面しています。
- スケーラビリティと柔軟性:データの増加に伴い、パフォーマンスを低下させることなくシステムをスケーリングする必要があります。組織は、進化するビッグ・データ・テクノロジーと要件に適応する必要があります。
ビッグデータの仕組み
ビッグデータは、組織が膨大な情報を収集、保存、処理、分析し、生データを実用的な知見に変換することを可能にする一連のステップを通じて運用されます。
- データ収集:このプロセスは、センサーデータをリアルタイムで生成する IoT デバイスや、投稿や動画などの非構造化データを生成するソーシャル・メディア・プラットフォームなどのソースからデータを収集することから始まります。その他にも、トランザクションシステム、モバイルアプリ、ライブイベントからのストリーミングデータなどのソースがあります。これにより、高度な分析に適した包括的なデータが確保されます。
- データストレージ:収集されたデータは、構造化データ、半構造化データ、非構造化データなど、多様な形式の生データ向けに設計されたデータレイクに保存されます。データウェアハウスは、特定の分析ニーズに合わせてデータを整理します。一方、クラウド・コンピューティング・プラットフォームは、大規模なデータの管理に適したスケーラブルでコスト効率の高いストレージを提供します。
- データ処理:Hadoop や Spark などのツールは、データを管理可能なチャンクに分割することで分散処理に対応します。また、クラウドプラットフォームは、データのクリーニング、変換、統合にリソースを提供し、データ品質を確保します。このステップでは、予測分析やその他の高度なアプリケーション用にデータを準備します。
- データの可視化:処理されたデータは、Tableau や Power BI などのツールにより、グラフやヒートマップなどの視覚的補助やダッシュボードを使用して表示されます。これにより、複雑なデータセットがシンプル化され、意思決定者は傾向や相関関係を探り、より迅速かつ確実な意思決定を行うことが可能になります。
ビッグデータのアプリケーションとユースケース
ビッグデータは、実用的な知見を提供し、効率を高め、イノベーションを促進し、世界中で業界を変革しています。
- ヘルスケア:ビッグデータは、スマートウォッチなどのウェアラブルから取得したセンサーデータを通じて、予測モデルや患者のリアルタイム監視を実現します。病院では、大規模なデータセットを使用して、治療計画のパーソナライズ、遺伝子情報の分析、運用の最適化を行い、患者の待ち時間を短縮し、ケアを改善しています。
- ビジネスインテリジェンスと小売業:企業は、価格戦略の調整、需要の予測、マーケティングのパーソナライズにビッグデータ分析を利用します。Amazon などの e コマースプラットフォームでは、在庫を最適化し、価格を動的に調整することができ、金融サービスでは取引データが不正検知に役立ちます。
- AI とビッグデータ:AI システムは、大規模なデータセットを使用して、画像認識、自然言語処理、不正検知のモデルをトレーニングします。自動運転車や Alexa などの仮想アシスタントは、意思決定とパーソナライズの強化にビッグデータを使用します。
- IoT(モノのインターネット):IoT デバイスは、パフォーマンスの最適化と予知保全に利用できるリアルタイムのデータストリームを生成します。スマートサーモスタットが省エネ設定を推奨し、農業では IoT センサーを使用して土壌の水分量を監視し、効率を向上させています。
- サプライチェーンと物流:GPS や RFID センサーからのデータストリームにより、荷物の追跡、ルート最適化、在庫管理を改善しています。予測分析で適切な製品の在庫確保やコスト削減、デリバリー精度の向上を実現しています。
- 金融および銀行:ビッグデータは、不正行為の検知、リスク管理の強化、クレジットスコアリングの強化に役立ちます。アルゴリズムでトランザクション履歴を分析し、異常を検出するほか、投資銀行ではアルゴリズム取引や価格予測にも使用しています。
- メディアおよびエンターテイメント:Netflix のようなプラットフォームは、ビッグデータを使用してコンテンツを提案し、ユーザーの好みを分析することでエンゲージメントを強化しています。メディア企業は、ソーシャルメディア分析を通じて視聴者をターゲット化することで、広告戦略を最適化しています。
- 製造業:機器からのセンサーデータをリアルタイムで分析し、故障を予測してメンテナンスのスケジュールを策定します。ビッグデータは、顧客のフィードバックや使用パターンを評価することで、製品設計にも情報を提供します。
- 教育:ビッグデータを通じて評価とエンゲージメント指標を分析することで、学習体験をパーソナライズしています。大学では、在籍者数の予測を最適化し、リソースを効率的に割り当てるために役立ちます。
- エネルギーおよび公益事業:ビッグデータは、エネルギー消費を最適化し、再生可能エネルギー源を統合します。スマートグリッドはリアルタイム監視を使用し、石油会社は地震データを分析してコストと環境への影響を低減しています。
不可欠なビッグ・データ・ソリューションとテクノロジー
ビッグデータを効果的に管理し、大規模で複雑なデータセットから実用的な知見を抽出するためには、ストレージ、処理、分析、可視化の高度なツールとテクノロジーが必要です。
- データ・ストレージ・ソリューションは、ビッグデータ管理の基盤を形成します。データレイクには未加工の生データが保存され、構造化データ、半構造化データ、非構造化データを格納します。一方、データウェアハウスは、データを整理してクエリーとレポート作成を容易にします。スケーラブルでコスト効率に優れたクラウドプラットフォームは、増加するデータ量に効率的に対応します。
- データ処理および分析ツールは、生データを実用的な知見に変換します。Hadoop などのフレームワークは、大規模なデータセットの分散処理を可能にします。リアルタイムのデータ処理を専門とする Apache Spark は、機械学習をサポートします。Talend などの ETL(抽出、変換、ロード)ツールは、データを効果的に抽出、変換、ロードすることで、分析用のデータを準備します。
- ビッグデータ用のデータベースは、多様な形式に対応しています。MongoDB や Cassandra などの NoSQL データベースは、スケーラビリティを備えた非構造化データを管理し、MySQL などのリレーショナルデータベースは構造化データを効果的に処理します。
- データ可視化ツールは、知見へのアクセスを提供します。Tableau や Power BI などのツールは、インタラクティブなダッシュボードを作成し、複雑なデータセットをシンプル化します。特定の Web アプリケーション向けに D3.js などのツールを使用してカスタムの可視化を行うことができます。
- Google BigQuery や Amazon Redshift などのビッグデータ分析プラットフォームは、クエリーと分析を高速化します。一方、Cloudera などの包括的なシステムは、ストレージ、処理、分析を 1 つのソリューションに統合しています。
- AI と機械学習ツールは、モデル開発にビッグデータを活用しています。TensorFlow や PyTorch などのフレームワークは大規模なデータセットを処理し、Google AutoML などのプラットフォームは専門家でなくとも AI にアクセスできるようにします。
- Apache Kafka などのストリーミングテクノロジーとリアルタイムテクノロジーは、IoT デバイスやソーシャルメディアからのリアルタイムのデータストリームを管理します。Flink は分析結果を提供し、即座に知見を得ることができます。
- セキュリティソリューションとガバナンスソリューションは、安全性とコンプライアンスを確約します。暗号化ツールは機微な情報を保護します。Collibra などのプラットフォームはデータ品質を維持し、規制コンプライアンスを確約します。
- Apache NiFi のような統合ツールは、システム間のデータ移動を自動化し、シームレスなコラボレーションと複雑なデータエコシステムの効果的な管理を可能にします。
よくあるご質問
ビッグデータは、組織の情報に基づいた意思決定、傾向の特定、顧客体験の向上、運用の最適化に役立ちます。ヘルスケア、金融、小売などの業界がイノベーションを推進し、競争力を維持することを可能にします。
ビッグデータは、ソーシャルメディア、IoT デバイス、e コマースプラットフォーム、金融取引、ストリーミングデータ、パブリックデータベースなど、さまざまなソースから生成されます。
データレイクは、生データをネイティブ形式で保存し、多様なユースケースに柔軟に対応できます。データウェアハウスは、データを構造化された形式に整理してクエリーを容易にし、ビジネス・インテリジェンス・アプリケーションで利用しやすくします。
データ品質の管理、セキュリティの確保、多様なソースの統合、インフラコストの処理、データの分析と解釈を行うスキルを備えた人材の確保などの課題があります。
Akamai が選ばれる理由
Akamai は、オンラインビジネスの力となり、守るサイバーセキュリティおよびクラウドコンピューティング企業です。市場をリードするセキュリティソリューション、優れた脅威インテリジェンス、そして世界中の運用チームが、あらゆるところで企業のデータとアプリケーションを多層防御で守ります。Akamai のフルスタック・クラウドコンピューティング・ソリューションは、世界で最も分散されたプラットフォーム上で、パフォーマンスと手頃な価格を両立します。安心してビジネスを展開できる業界トップクラスの信頼性、スケール、専門知識の提供により、Akamai は、あらゆる業界のグローバル企業から信頼を獲得しています。

