

When Destiny is Knocking on Your Door Again - Data Mining CDN Logs to Refine and Optimize Web Attack Detection


A few years ago, I wrote a blog post trying to explain, with humor, why choosing application security as a career path is destiny derived by my parents calling me "Or", and why a personal name that is a conditional word can sometimes be challenging in daily routines, since some attack payloads contain conditional words.
As years passed and enterprise security has now become my "thing", the voices of destiny started their magic again. So I thought it is a good time to have some fun and combine new habits with old ones. I decided to use some data mining and machine learning techniques on web attack data to try to optimize and refine attack detection capabilities.
In this blog, we will show how Content Delivery Network (CDN) logs classified as SQL injection attacks can be used to refine and optimize security rules, improve detection of future attacks, and detect emerging attacks targeting new vulnerabilities.
The process used includes elements taken from Natural Language Processing (NLP) to analyze SQL injection payloads, clean and curate them, break them into keywords and find the best relation between them to be able to get new and valuable insights.
Rule them all - optimizing web attacks detections rules
Method, challenges and data
The executed experiment being presented from this point forward will use SQL injection attack payloads as seen on the Akamai CDN platform. These are real world payloads being used in the wild to test or execute SQL Injection attacks on Akamai customers.
Before deep diving into the technical aspects of this experiment, let's touch base on what SQL injection is all about and why analyzing SQL injection payloads is challenging but also introduces opportunities.
SQL injection is an attack method that attempts to inject SQL payload into a vulnerable web application. Once injected, the payload is executed on the database server used by the web application.
SQL is a standard language for storing, manipulating and retrieving data in databases. It is also flexible and can be executed to do the same/similar functionality by using different syntax. The flexibility in SQL programming language is also the reason why defending against SQL injection attacks is challenging, since it introduces the ability to evade and obfuscate detection.
The most common technique being used to find and exploit SQL injection will require the attacker to send to the targeted web application many customized attack SQL payloads until it is able to find the injection point into the specific web application being targeted and can exploit that vulnerability.
Both flexibility and attack payload volume create challenges and opportunities on the defensive side in detection of SQL injection attacks.
The defensive challenges are the ability to write and execute detection rules that are accurate, cover all attack techniques and are optimized in terms of performance.
The defensive opportunities are derived from the varied attack payloads being used in SQL injection attacks; therefore, in this research exercise, we will try to explore those opportunities.
As part of the research, we consider each SQL injection payload as a textual document, break each payload into the keywords that compound it, and try to find relations between different keywords across all used SQL injection payloads samples.
The objective of the research is to find new insights based on the relation between SQL injection payloads keywords; once finding relation between keywords, we will explore the opportunity of gaining new insights that might lead to performance improvements and detection of new vulnerabilities being abused in the wild.
The data used as part of this research includes payloads of a variety of SQL injection attacks. Payloads can differ as a result of customization,For example, the PostgreSQL relational database will use a function: "pg_sleep(2)" to delay execution of the server process for 2 seconds while MS SQL Server syntax for the same functionality will look like - WAITFOR DELAY '00:00:02'.
In order to simplify the explanation for the used techniques, we will use 7 simple SQL injection payloads to make the steps in the data mining process clearer to understand.
Step 1 - normalization of data
The first step in the data mining process is to process the initial 7 SQL injection payloads and make sure we can normalize them by replacing logical functionalities represented by different SQL syntax to a generic representation, replace time with a generic template, replace enumerated column names and remove SQL punctuations and delimiters.
For example, as seen in figure 1, on payload number 6, both logical expressions 1=1 and 2=2 were replaced on figure 2 to become the same keyword <LogicalEqualDigits>.
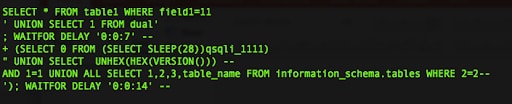 Fig 1.: initial SQL injection payloads
Fig 1.: initial SQL injection payloads
 Fig 2.: normalized SQL injection payloads
Fig 2.: normalized SQL injection payloads
Normalizing and cleaning the data enable us to focus on the most significant keywords and templates. This then allows us to be able to capture the relation between them.
Step 2 - keywords frequency
The second step of the data mining process is to choose the most frequent words being used. Keywords and template frequency can give us some indication of which SQL keywords are more frequently used in SQL injection payloads. That information can lead to making sure those keywords are properly prioritized to be matched before other payloads.
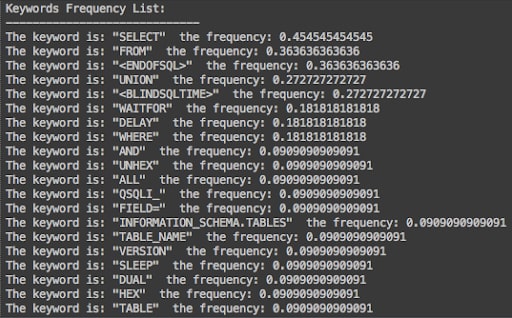 Fig 3.: SQL injection keywords frequency
Fig 3.: SQL injection keywords frequency
When processing payload keywords, we should make sure we use the most frequent keywords since processing large data-sets might have computational limitations. In the case of the 7 samples experiment, with a small number of keywords, this limitation is less relevant.
Step 3 - keywords matrix and distance
The third step in our data mining process of SQL injection attack payloads would be to start building a matrix that will help express the relation between the different keywords on the different payloads samples.
In order to do that, we built a matrix: each row represents a different SQL injection payload and columns represents all possible keywords. If the keywords were used in a given payload, the value will be one; if not, the value will be zero, as seen in figure number 4.
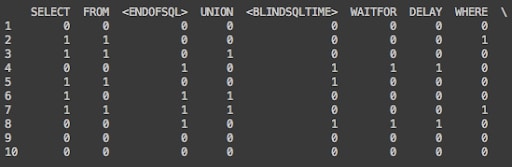 Fig 4.: payloads and keywords matrix
Fig 4.: payloads and keywords matrix
In order to better represent the relation between different keywords, we transposed the matrix so rows representing different keywords and columns represent different sample payloads, as seen in figure 5.
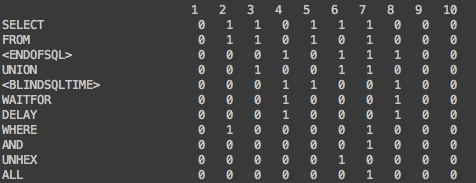 Fig 5.: payloads and keywords matrix after transposition
Fig 5.: payloads and keywords matrix after transposition
The distance between each possible pair of keywords is done by using Jaccard distance: the size of the intersection divided by the size of the union of the sample set. The value of the distance between each pair of keywords will be represented as the value between 0 - 1.
When the value is equal to 0, that represents the strongest relation between two keywords. Each time one of the paired keywords appeared on one of the sampled payloads, the other keyword appeared on that payload as well.
When the value is equal to 1, that represents the weakest relation between two keywords, meaning the two paired keywords never appeared on the same sampled payload.
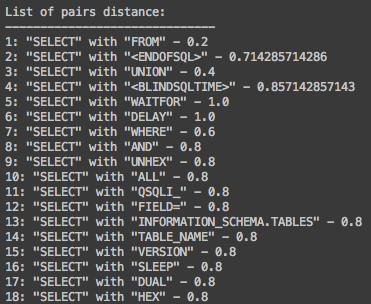 Fig 6.: List of paired keywords and their Jaccard distance value
Fig 6.: List of paired keywords and their Jaccard distance value
For example, as seen in figure number 6, keywords "SELECT" and "FROM" in line number 1, have a strong relation with a Jaccard distance value of 0.2. In order to better understand that value, we can look at figure number 1, which contains the original SQL injection payloads, where "SELECT" appears on 5 of the sampled payloads and the keyword "FROM" appears on 4 of those appearances as well.
The strength of the relation between keywords, such as "SELECT" and "FROM", is not surprising from SQL syntaxial point of view - these keywords are used frequently to express SQL code that query data. This gives us an indication that the initial results represent adequately the hidden relation between examined keywords.
In the following steps, we try to determine how this relation can better help with reshaping attack detection rules and what new insights can be emerged out of keywords relations.
Step 4 - keywords clustering
In the following step, we will execute clustering between different pairs of keywords, based on the Jaccard distance, to build an hierarchical clustering that will enable us to have clear visibility to the relationship between all sampled keywords.
The algorithm that was used to execute the hierarchical clustering was Ward, since it's minimum variance criterion minimizes the total within-cluster variance.
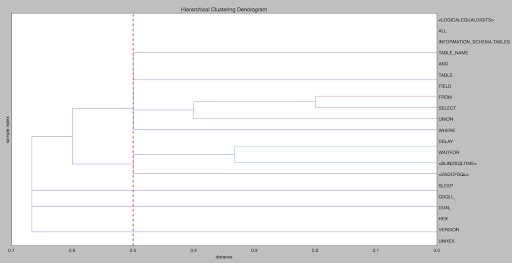 Fig 7.: sampled payloads - hierarchical clustering dendrogram
Fig 7.: sampled payloads - hierarchical clustering dendrogram
Figure 7 shows us that "SELECT" and "FROM" were clustered and that "UNION" was also clustered with them, as according to the data it appears to have a strong relation with them. Each cluster joined distance is increasing as more keywords with reduced strength to the other members of the cluster joined that cluster (as appears in figure number 7 graph horizontal values). The cut-off point (red line on figure number 7) will be determined based on the preferences on cluster strength;, the preference on cluster strength will reflect the size and number of members for each cluster.
Real world results - using the power of CDN
Findings
Now it's time to use real world SQL injection attack payloads in scale. In order to do so, we used Akamai's CDN visibility to web attacks targeting Akamai customers, we sampled over 500,000 SQL injection attack payloads that were used against our customers and analysed them using the same technique explained above.
In order to avoid computational and performance challenges, only the top 60 most frequently used keywords were used. The outcome shows us some interesting results that align with some of the pre-experiment expectations and validate the accuracy of the result.
We were able to see that keywords "WAITFOR" and "DELAY", which are commonly used to execute variants of an SQL injection attack called blind SQL injection, were clustered with zero distance between them. Zero distance means that, each time the first appears in a SQL injection payload, the other will appear as well. This example validates that the data mining process is working, since from an SQL syntaxial point of view those keywords should be paired to make the SQL functionality of delaying query processing work. On top of that, according to the frequency of keywords, these keywords are in the 5th and 6th place - meaning that any improvement in the performance for security rules that are associated with those keywords will lead to significant positive performance impact.
The second example for validity of the executed data mining process is the clustering of "THEN", "ELSE", and "END". These keywords are known to be used together to create logical conditional statements; therefore, it only makes sense that these keywords appear together in SQL injection payloads.
Looking into the clustering tree also showed some new insights into the relation between keywords that represent SQL columns and tables names. For example, keywords such as "USERS" and "EMAIL" were clustered, "USERS" representing table name while the "EMAIL" representing column name. Those keywords were used as part of a SQL injection vulnerability exploit that was relevant a few years back, this makes sense as the used data was from the past years.
Insights and derived implementations
So now comes the question: what can we learn from the SQL injection payloads data mining process result? Here are some insights and derived implementations:
Improving security rules performance
An easy and important way to improve security rules performance would be to use the frequency of the keywords as derived from their usage in the wild. By reshaping security rules to prioritized rules matching order to first try to match rules that contain frequently used keywords will result with higher chances of early matching and improvement in performance. This technique is more relevant to rules matching mechanisms that were implemented as sequential matching and not parallel.
Another improvement in performance can be achieved by using clustered keywords to introduce rules that will avoid or replace the usage of much more complex regular expression rules. For example the "WAITFOR" "DELAY" we used previously; the fact that those keywords are highly related can enable us to execute simple text pattern matching that is known as better in performance when compared to regular expressions matching. Using simple pattern matching and avoiding execution of regular expressions can lead to improvement in performance involved in the effort of rules matching.
Finding new vulnerability abuse in the wild
A new SQL injection vulnerability, targeting websites in the wild, might result in unique keywords representing specific table and column names to be clustered. This kind of clustering can help with finding those active SQL injection campaigns in the wild being able to detect those vulnerabilities being abused.
Summary
Disclaimer - I am not a machine learning expert, just a big fan that loves to learn new stuff. Therefore, the described experiment is focused on the high level description of chosen technique being used and the possible insights and implementation and less on the measurements and the accuracy of alternative techniques. More to that, the assumption is that there are probably much more robust and axotic algorithems and techniques to execute the suggested data mining process.
While this research returns interesting and insightful outcomes, it can be enhanced to include attributes that can help with crafting more accurate security rules. Such indicators can be the order of the keywords, for example "WAITFOR" "DELAY" that as derived from syntax will always appear in the same order.
SQL injection vulnerabilities have been around for over 20 years and are still considered the #1 item in the applications risk OWASP Top 10 document. We need to continuously innovate and enhance our detection capabilities to be able to reduce the risk of being exposed to this vulnerability.
At this time and age, data that is categorized as being volumetric, with many variations being streamed in velocity will give those that own it the upper hand. Data can give us the opportunity to excel, innovate and find new insights never seen before even in legacy and obsolete territories.
In a personal note, to my friends, colleagues and readers, I encourage you all to find your path of innovation, follow your instincts and dreams, have some fun and listen as your destiny might be knocking on your door.

