

Evading Link Scanning Security Services with Passive Fingerprinting


Link scanners are a critical component in multiple classes of security products including email security suites, websites that suggest direct inspection of a suspicious link, and others. Behind the scenes, these services use web clients to fetch the contents of a link. This is, by definition, a bot, what we often nickname "a good bot." This research discusses scenarios where threat actors apply classic tactics used against "bad bots" to evade detection by link scanners. Our focus is on passive techniques that are transparent to the security tool, allowing an attacker a clean and easy bypass.
The tool that was used as part of this research will be unveiled during BlackHat Europe 2020 and will be released as an open-source project on GitHub.
Malware authors usually spread their illicit goods to new victims by:
Leveraging remote code execution exploits. Nowadays it is considered rare to hold an unknown remote code execution chain of exploits.
Sending an attachment or a link to a malicious file, using social engineering to lure the victim to run it.
Attacks involving directly sending the payload are addressed either by anti-virus software or by sandboxes and won't be discussed today. The services we examine are designed to solve the challenge posed by the second scenario - inspecting suspicious links. These products are protecting us by actively probing the link and applying a series of tests with a clear verdict, allowing or blocking access to the link.
The most common products embedding a link scanner are those scanning incoming emails. It is a must even for small businesses today, with services available as an integral part of Office 365 and G-Suite subscriptions or as a standalone product. When an email with a link is received, the scanner typically sends an HTTP GET request to the resource in question and will scan the response as if it was a binary attached to the email.
Note that although auto-scanning incoming emails with links is the most common use for this tactic, it is far from being the only one. There are services that will scan a link independently of its content. Another example is sandbox products, which allow submission via URL.
When meeting someone in the street, you can learn facts about him or her in two different ways - you can either ask a question or alternatively observe and listen to their activity. The latter approach is analogous to passive fingerprinting, when we do not perform any action, just observe the behavior of an object. In our context, this object is not a person, it is a web client sending us a request for a web resource.
We define passive web client fingerprinting as measuring different properties and features of incoming requests at any level (from physical to application layer) in a way that will only inspect features observable in a regular network transaction. The key trait is that a server performing passive fingerprinting is ideally indistinguishable from a regular one. For comparison, active web client fingerprinting often involves running code on the client-side and has its own pros and cons.
About a year ago we had a Eureka moment -
Link scanners are a key component in multiple products, an inseparable part of a good defense-in-depth modern security posture.
A critical component of getting the link's content is a web client, products cannot analyze what they don't see.
Passive fingerprinting is virtually indistinguishable from the client systems point of view.
Is it possible to passively fingerprint a security tool? If so, can we provide it a false, benign response while providing potential victims to malicious content?
The short answer is - yes.
Each web client behaves a bit differently as a result of multiple factors: physical and network infrastructure, operation system, network stack, software constraints, and the actual implementation a developer opted for.
Our goal in this research was to prove that by passively collecting hints left behind by any of the above factors, we can distinguish between a real human using a real browser and automated software used by security vendors.
Here at Akamai, we have successfully identified "bad" bots for years, so it wasn't a surprise that we were able to prove our hypothesis in real-world scenarios.
We performed the following experiment:
Set up a server simulating a potential threat actor. This server was built from scratch, implementing only publicly-known passive fingerprinting tactics.
Selected a prevalent security service that inspects links.
Trigger a request to the server from the security tool.
For example, in order to test an email security product, we sent a message to an account we set up in advance that is protected by the product. The content included a link to a website hosted on our dedicated server. Since our server was set up fresh for this task, it was safe to assume that any incoming traffic was a result of link scanning activity. We repeated this process with a different URL for any inspected service, guaranteeing there's no cross-contamination between the experiments. Some of the errors and features we observed during our experiments are listed below. Note that all of the information we provide here was disclosed to the relevant vendors months in advance, and most of them have fixed the issues we detected. Nevertheless, since not all did, and due to the fact that our goal is not to shame but to improve the overall state of security, we do not name any names, nor provide explicit fingerprints for any vendor.
It is also worth mentioning that all tested products showed at least a single disclosing trait. This means passive fingerprinting is an extremely potent tactic and may allow an attacker to overcome any relevant product.
Obsolete Browser Versions
Years ago, vendors realized they needed to include a spoofed HTTP User-Agent header since some threat actors already filtered incoming requests according to this header (or lack thereof) as described in a previous blog post.
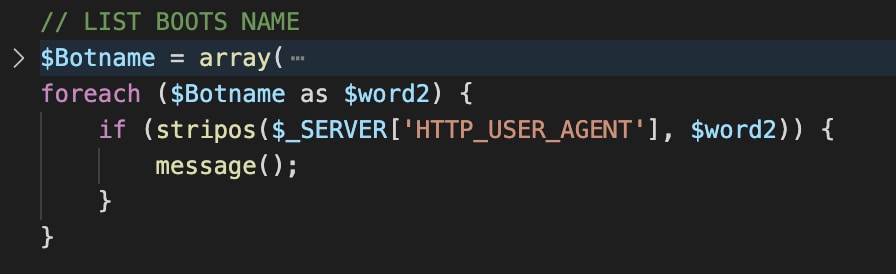
Sadly, in software development, code that operates as expected is often overlooked. Spoofed headers introduced years ago are still in use today. While many browsers use Chrome versions that are a couple of years old, the record-holder was a client using an Internet Explorer 6 (!!!) user-agent header. Internet Explorer was released on August 27, 2001, and has not been supported since January 12, 2016.
Another class of products suffering from this issue is sandboxes. Creating a working sandbox image is very tricky and updates are usually disabled. As a result, this type of machine is very static. From our inspection, it seems that some vendors download content from the suspicious link using browser automation, living-off-the-land within their own virtual machine. This means that the failure to update the browser version periodically will cause this hacky engineering solution to become a ״fingerprintable״ artifact.
Hard-coded referer header
When you click a link on a web page, under most conditions, the target of the link will know where you came from, as this data is shown in the HTTP Referer header. Some vendors spoof this header in order to simulate a real browser. Assuming the malicious server was set at www.malicious.server.com, then the fake header is set to www.google.com/search?q=malicious.server.com, which is specific to the extent that it is unlikely to be real. Furthermore, in some contexts, this header is missing - as, for example, when a user clicks a link in the context of Outlook's email desktop client. If an attacker knows that the potential victim uses Outlook, he or she knows that any request containing any Referer header is a security tool.
Disclosing Via header
Another problematic HTTP header is Via, which under some (mis)configurations discloses the actual name of a proxy being used as part of the analysis infrastructure. Other headers that are typical to proxies like X-Forwarded-For might also leak information, but it wasn't present in the products we've inspected.
DNS PTR record
"Normal" DNS record, known as an A record, allows clients to resolve a URL to an IP. PTR records are the exact opposite - allowing clients to perform what's commonly known as reverse DNS lookup, i.e., get the URL associated with an IP. While not mandatory, a PTR record is useful in some scenarios, like verifying an IP resolves to a specific domain in the context of an anti-spam mechanism.
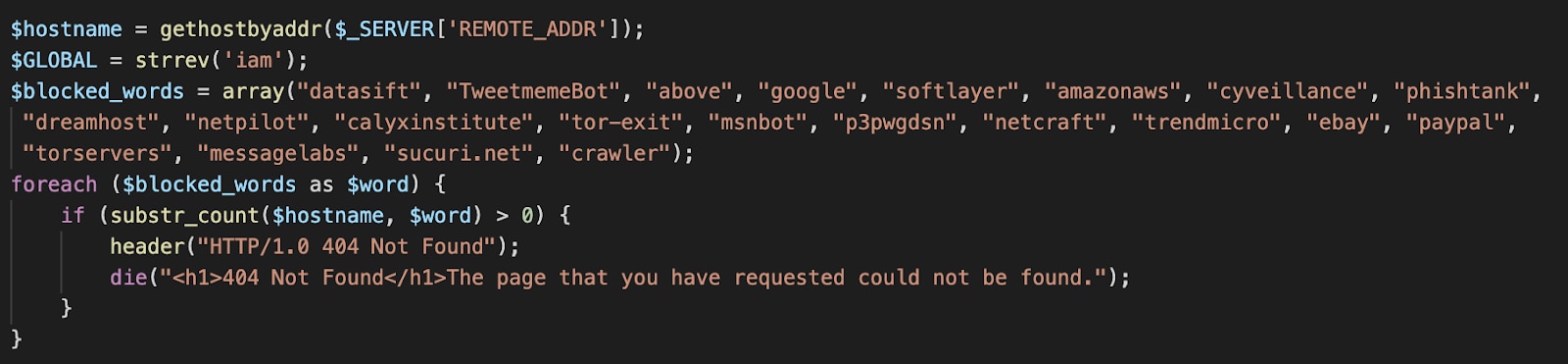
Curiously, some of the services we've examined had such a record, often pointing to the homepage of the service itself. This means that if you are seeing an incoming request from an IP and perform a reverse query, you will see it resolve to a page of the form scanning.product.vendorName.com, which is a strong hint for an attacker to avoid serving any malicious content.
Here as well, threat actors already implemented a similar approach, wrapping the reverse query with the GetHostByAddr API:
Disclosing AS
An Autonomous System (often abbreviated AS or ASN) is an entity tying IP address ranges to a network operator. We've observed two possible issues that result from checking the client's IP AS identity. The first involves large security vendors operating their own AS. Records associating an IP with an AS are public, so an attacker can check the originating AS of an incoming request and respond accordingly.
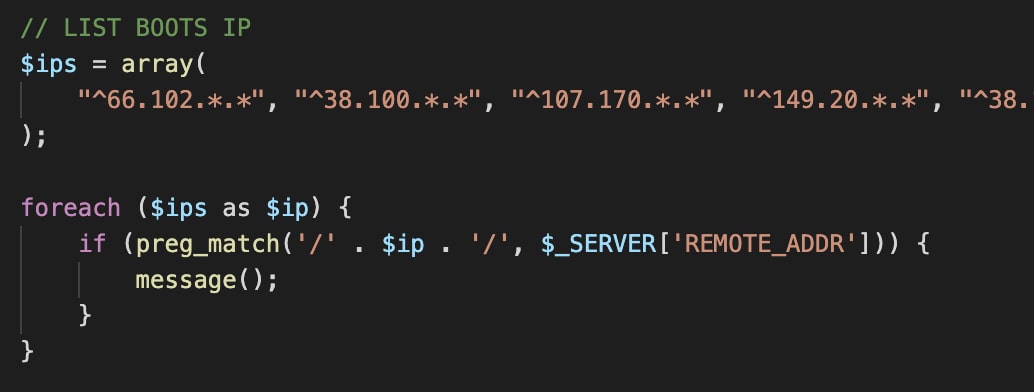
A second possible issue is an IP associated with cloud services like Amazon's AWS or Google's and Microsoft's equivalent services. Security services are often forced into using these services to analyze massive volumes of requests in a scalable way, which requires immense resources. Nevertheless, using an IP associated with these providers is a strong hint for a client who is not a real user, as the vast majority of potential victims do not operate a cloud machine or use such services as a gateway to the internet. This issue can be mitigated at least to some extent by using proxies properly.
It is worth noting that similar behavior was already observed in-the-wild as well, blacklisting directly by IP ranges:
Exotic MTU
A maximum transmission unit, or an MTU, defines the top limit for a packet size that can be transported in a single network-layer transaction. Values have a low spread, tightly correlating with different types of link-layer implementations. Ethernet for example usually implies a value of 1500, while DSL is 1492. Curiously, some hosting service providers have unique values that are present nowhere else and can be easily leveraged as a detection mechanism.
TCP features and user-agent correlation
Windows, Linux, and Mac implement the TCP stack differently. Flags and options being set alongside buffer window size are only some of the properties which allow us to create a TCP-level fingerprint. This results in a very potent tactic - first, detect the OS flavor by TCP parameters, then inspect the User-Agent header and the simplified OS, e.g.:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
If there's a contradiction between the value implied by TCP and the header - it is likely that we are looking at traffic from a scanner. This is a very common issue to observe since many vendors opt for Linux-based virtual machines, which are historically easier and cheaper to scale.
We would like to recommend Michal Zalewski's wonderful tool named p0f which, out-of-the-box, allows passive fingerprinting of specific TCP combinations with high confidence and holds an extensive repository of the aforementioned exotic MTU values.

Getting better
Because many parts of the aforementioned attacks are already happening in-the-wild, we must do better.
Are you a blue team member or leader? Be aware of the limitations of your tools, understand the scenarios which put your users at risk, and try to understand if you have a different mitigation strategy for it. For example, consider blocking malicious content by an analysis performed at the endpoint and not by a different client. Other highly advanced tools don't rely on any client, running state-of-the-art machine learning (ML) models on the URL itself. Akamai's Secure Internet Access Enterprise product is one good example.
Are you a vendor of a product involving link-scanning components? Know your own fingerprint and try to minimize it. Some improvements are trivial while others are costly and next to impossible. First, make the changes that don't have external costs - for example setting a correct reasonable user agent or removing redundant headers. Continuously maintaining an up-to-date user agent is a bit of a hassle, but even modifying it every few months should be sufficient to stay off the radar of attackers. In contrast, some fixes are complex and costly, such as replacing Linux-based VM infrastructure and using HTTP proxies sending countless requests a day.
Another consideration should be how difficult it is for an adversary to collect one of these indicators. For example, measuring and analyzing incoming requests MTU and TCP properties requires specialized software, like p0f, while blocking by user-agents can be achieved by editing well-documented configuration files, such as Apache's ״htacess״. Consider a scenario where an attacker has limited access to a compromised website - he or she might be capable of adding or editing files like ״htaccess״, but running a new process like p0f is a different story. Even if an attacker can run it under certain conditions, this process is very noisy and likely to draw unwanted attention.
The framework
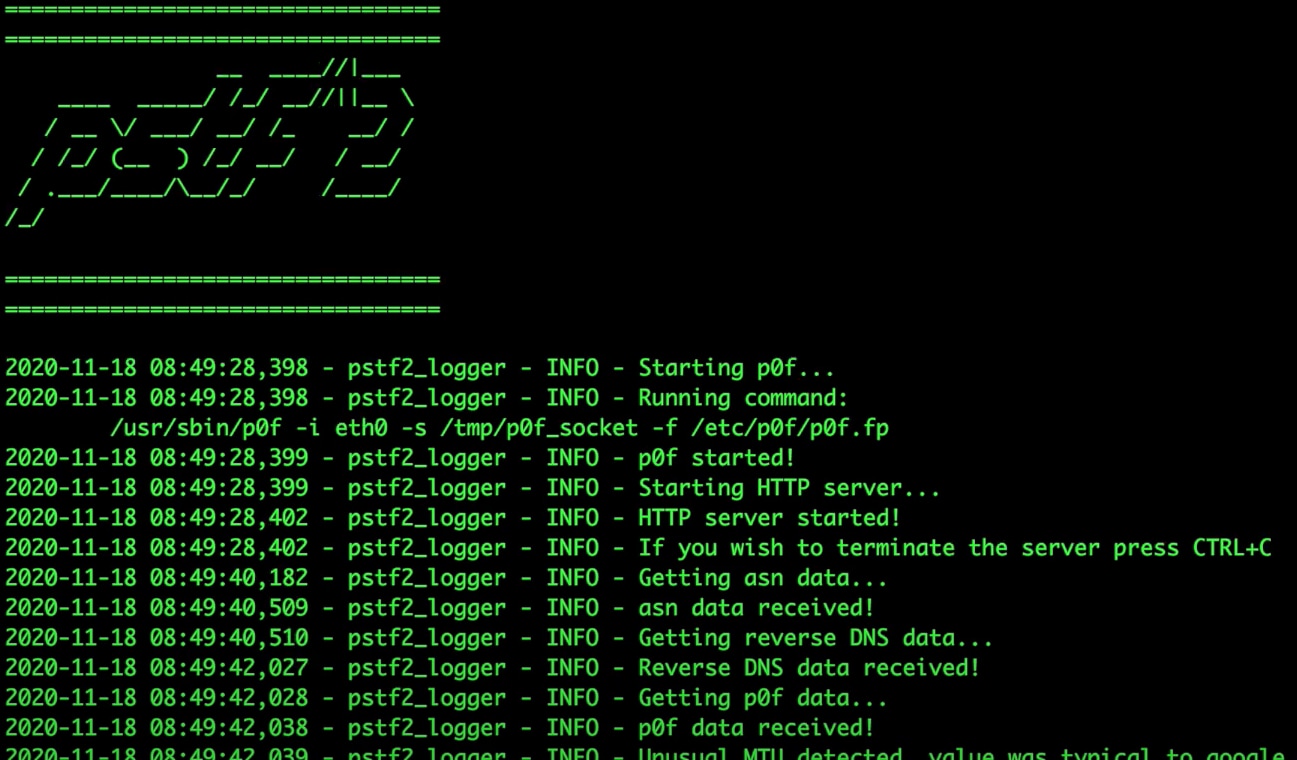
As part of our research, we developed a set of tools for processing incoming requests' features and sending custom responses. We named it pstf^2 - passive security tools fingerprinting framework. It includes a customized Python HTTP server that runs alongside a p0f instance and is designed to be capable of intercepting all of the above potential fingerprints. It differentiates between potential victims and security services and responds accordingly. When a "victim" is detected, the EICAR string is sent in response; otherwise, the client is redirected to a Rick Astley music video.
The framework is publicly available at:
https://github.com/G4lB1t/pstf2
As part of the repository, we also released a friendly docker image that simplifies the process of setting up the framework.
We purposefully did not release specific fingerprints for any of the security products, as mentioned before. This was not an oversight; we prefer to leave this as "an exercise for the reader".
Epilogue
In this research, we described how one may take known tactics and re-apply them against security products. We know as a fact that some of the tactics we discussed today are already in use by threat actors. How many others are in use that we are unaware of? We will never know without further research. We hope that this publication will raise awareness of this open gap in many security products. We feel sharing our expertise on bot detection is for the greater good of everyone.

