
요약 보고서
이 리서치에서는 패치된 취약점의 근본 원인을 찾기 위해 대규모 언어 모델을 사용하는 방안을 조사했습니다.
Akamai는 패치 화요일(Patch Tuesday) 취약점의 근본 원인을 자율적으로 분석하고 자세한 보고서를 생성하는 PatchDiff-AI 다중 에이전트 시스템을 개발했습니다.
이러한 종류의 분석을 통해 보안팀은 방어 또는 공격을 목적으로 거의 즉시 취약점을 분석할 수 있습니다.
여러 전략을 사용한 결과, 시스템을 미세 조정해 공격 기법 분석 및 트리거 흐름을 포함한 완전히 자동화된 보고서를 생성하여 80% 이상의 성공률을 달성할 수 있었습니다.
패치 화요일 → 악용 수요일
Microsoft의 정기 업데이트 주기는 패치 화요일(매월 두 번째 화요일)에 집중되어 있으며, 이때 포괄적인 CVE 목록과 해당 수정 사항이 릴리스됩니다. 이러한 수정 사항은 핵심 시스템 파일을 패치하거나 교체하여 업데이트를 적용하는 패키징 형식인 MSU(Microsoft Standalone Update) 파일로 제공됩니다.
패치 화요일 이후에는 Microsoft 패치로 인해 발생한 취약점을 공격자들이 앞다투어 찾아내는 “악용 수요일”이 뒤따르는 경우가 많습니다. 공격자는 업데이트된 바이너리에 대해 바이너리 디핑을 수행함으로써 근본적인 보안 문제를 신속하게 파악하고 기업이 패치를 광범위하게 배포하기 전에 악용을 시도할 수 있습니다.
이와 유사한 방식으로, 보안팀 직원들은 탐지 및 방어를 위해 취약점의 근본 원인을 파악하고자 이러한 패치를 서둘러 분석하는 경우가 많습니다.
패치 디핑의 현 주소
오늘날 패치 디핑은 지루한 프로세스입니다. 취약한 코드를 성공적으로 탐지하려면 연구자는 다음을 수행해야 합니다.
취약점을 포함하고 있는 것으로 의심되는 파일 탐지
바이너리 디핑을 수행하여 변경 사항 식별
다른 일상적인 코드 업데이트에서 보안 관련 변경 사항 격리
의심스러운 부분을 분석하고 근본 원인 파악
호출 흐름을 동적으로 검사하여 잠재적인 트리거 경로 찾기
수정 패치의 완성도 평가
이러한 단계를 수행하는 데 몇 주가 걸릴 수 있는데, 매달 엄청난 양의 취약점이 동시에 공개되므로 문제는 점점 더 커집니다.
Akamai의 연구원들은 패치된 취약점을 신속하게 분석하고 근본 원인을 파악할 수 있는 더 나은 방법을 찾기 시작했습니다.
패치 디핑 분석에 LLM 사용
대규모 언어 모델(LLM)은 사용자 인풋과 함께 훈련된 데이터에 기반하여 통계적으로 타당하며 정확한 정보를 생성할 수 있습니다. 그러나 제한된 맥락 창(처리할 수 있는 데이터의 양과 운영 비용에 영향을 미침)과 악명 높은 모델 환각 등의 몇 가지 한계가 있습니다.
보안 부문의 취약점 평가 분야에 대한LLM의 기여에 관한 많은 논문이 수년에 걸쳐 발표되었습니다. 현재 LLM은 클로즈드 소스 소프트웨어를 분석하는 데는 어려움을 겪고 있으며 사람이 읽을 수 있는 코드의 존재가 공통점인 오픈 소스 및 웹 취약점과 관련해 훨씬 더 나은 성능을 보입니다.
OpenAI의 Aardvark 및 Claude Code 보안 검토 툴은 여전히 읽을 수 있는 소스 코드로 한정됩니다. 다른 한편에는 제로데이 발견을 목표로 하는 Google Project Zero의 Big Sleep이 있습니다. 어떠한 접근 방식도 바이너리를 클로즈드 소스로 분석하지 않습니다.
PatchDiff-AI 소개
Akamai의 리서치에서는 보안 패치의 근본 원인 분석(RCA)에 LLM을 사용하는 다른 접근 방식을 취합니다. 검증된 것으로 보이는 당사의 이론은 바이너리 “디핑”이 제공하는 추가적인 맥락이 복잡한 로우레벨 코드를 이해하는 LLM의 능력을 크게 향상시킨다는 것이었습니다.
이 작업을 위해 당사는 특정 플랫폼에 대한 Microsoft 기술 자료(KB) 업데이트의 분석을 자동화하는 다중 에이전트 시스템을 개발했습니다(그림 1). 이 시스템을 PatchDiff-AI라고 합니다.
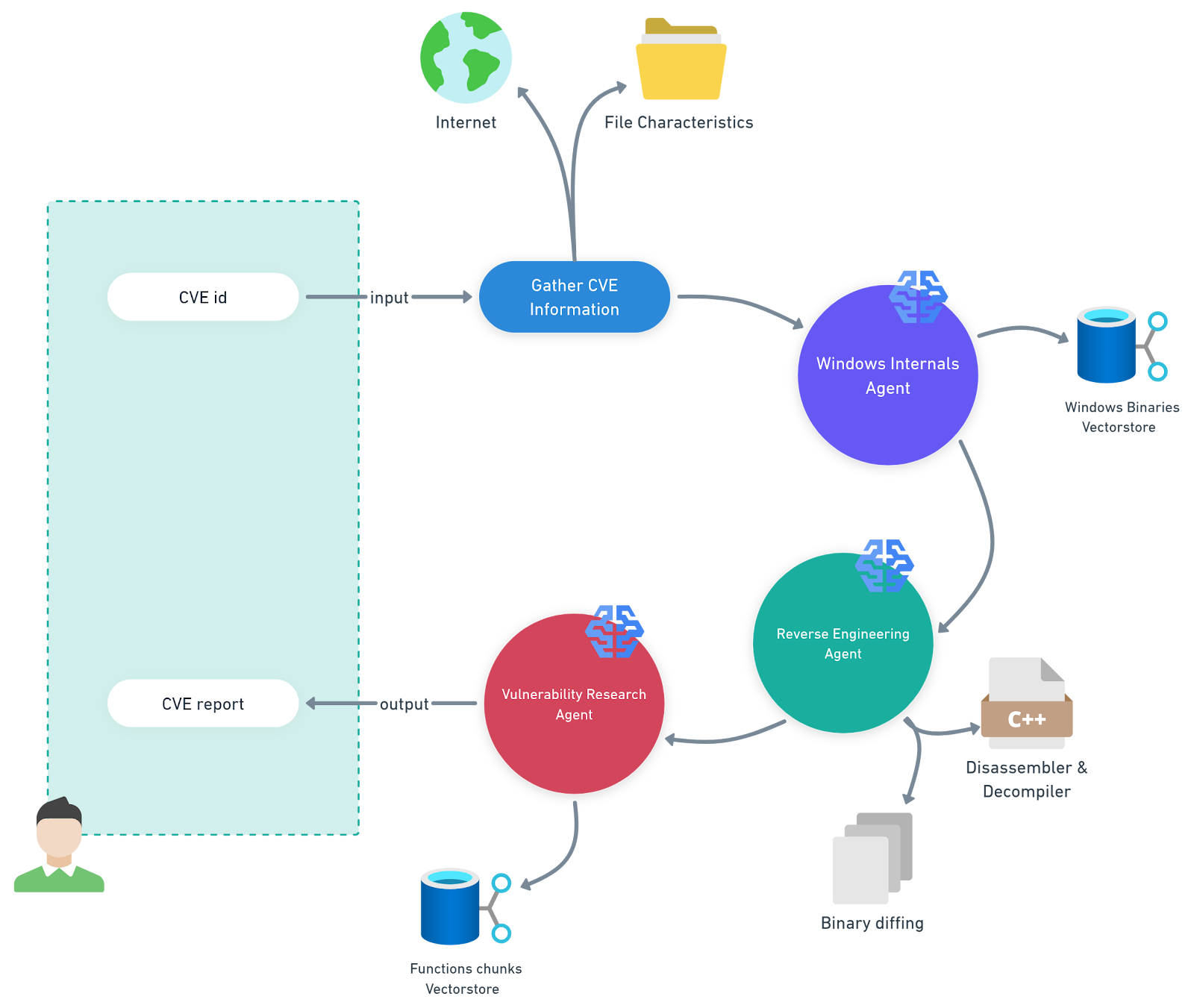 그림 1: 저희의 멀티 에이전트 시스템인 PatchDiff-AI의 일러스트레이션
그림 1: 저희의 멀티 에이전트 시스템인 PatchDiff-AI의 일러스트레이션
PatchDiff-AI 정의
Windows 내부 에이전트 - 이 에이전트는 Windows 바이너리와 해당 기능 메타데이터가 포함된 벡터 스토어로 뒷받침되는 RAG(Retrieval Augmented Generation) 파이프라인을 사용합니다. 이를 통해 에이전트는 분석 범위를 크게 좁히고 가장 관련성이 높은 구성요소에 집중할 수 있습니다.
리버스 엔지니어링 에이전트 - 이 에이전트는 최신 리버스 엔지니어링 툴을 사용해 관련 파일을 분석하고 디핑합니다. 이는 다른 에이전트가 사용할 수 있도록, 발견한 아티팩트를 전체 맥락에 추가합니다.
취약점 리서치 에이전트 - 이 에이전트는 맥락에 존재하는 모든 아티팩트와 기타 정보를 수집하고 일관된 보고서를 생성해 분석을 오케스트레이션합니다.
방법론
맥락 창의 제한과 환각으로 인해, LLM을 최대한 효과적으로 사용하려면 관련성이 높고 간결한 맥락을 제공하는 것이 중요합니다. 그러면 취약한 코드 구성요소를 격리하는 작업에서 높은 정확성을 유지하는 동시에 운영 비용을 절감할 수 있습니다.
분할 정복
구현에서 중요한 세부 사항 중 하나는 분석을 몇 가지 더 작고 구체적인 여러 작업으로 나누는 것이었습니다. 이러한 작업은 결국 에이전트 형태로 이루어집니다.
CVE에 대한 정보를 가져와 프로필 생성
관련 업데이트를 다운로드하고 기본 버전 파일에 델타 적용
Windows 내부 AI 에이전트를 생성해 취약점 메타데이터를 사용하여 관련 파일 격리
리버스 엔지니어링 AI 에이전트는 다음과 같은 작업을 수행합니다.
기호를 분해하고 적용한 다음 바이너리 디핑을 위해 내보냄
바이너리의 상관관계를 파악하고 변경 사항과 호출 흐름 식별
취약한 코드 블록 파악
가능한 취약점 경로를 렌디션(iterations)하여 교차 상관관계를 파악하고 가능한 최상의 결과를 찾는 취약점 리서치 AI 에이전트 구축
이렇게 분할했을 때의 주요 장점 중 하나는 각 작업 유형에 따라 특정 모델을 사용할 수 있다는 점이었습니다. OpenAI o4-mini는 파일 메타데이터를 보강하는 데 뛰어났으며, OpenAI o3는 의심스러운 취약한 코드에 대한 최종 심층 분석에 사용되었습니다.
작업에 적합한 모델을 선택한 것은 두 가지 면, 첫째로는 정확성, 둘째로는 비용 면에서 유용했습니다.
맥락 보강
LLM은 대량의 정보를 “기억”하는 머신입니다. 프롬프트를 통해 LLM을 호출하면 프롬프트 맥락 내에서 가장 관련성이 높은 정보를 제공하도록 LLM이 조정됩니다.
패치된 취약점에 대해 LLM에 제공할 수 있는 모든 정보는 보다 정확한 응답을 생성하고 취약한 코드를 찾을 가능성을 높이는 데 도움이 됩니다. 그러나 취약점에 대한 모호한 정보는 좋지 않은 결과를 초래할 수 있습니다.
분석 과정에서 취약점 메타데이터로 맥락을 보강하는 작업이 매우 중요했습니다. 이를 보강하기 위해 LLM에 KB 설명, 시스템 파일 설명, 바이너리 디핑 데이터를 제공했습니다. 이 접근 방식을 통해 분석해야 하는 변경 횟수를 좁힐 수 있었고, 나아가 LLM의 맥락 길이와 반복 횟수를 줄일 수 있었습니다.
결과
프레임워크를 평가하기 위해 다음 사항을 정확하게 파악하는 모델의 능력을 검사했습니다.
CVE에 해당하는 취약한 실행 파일
실행 파일 내의 취약한 함수
취약점의 근본 원인과 이를 정확하게 설명하는 능력
이러한 매개변수를 기반으로 지난 3건의 Windows 11 24H2 패치 화요일 릴리스를 분석했습니다. 툴을 실행하고 자동화된 보고서를 생성한 후, 선택한 결과를 수동으로 검사하고 최종 모델 응답의 정확도를 판단했습니다.
맥락을 개선하고 서로 다른 작업에 맞게 다양한 모델을 조정한 후, 최종적으로 다음과 같은 결과를 달성했습니다.
해당 CVE와 관련하여 패치된 실행 파일을 88.6%의 정확도로 올바르게 식별
83.9%의 정확도로 취약한 함수를 올바르게 발견
71.4%의 정확도로 취약점의 근본 원인을 올바르게 파악
정적 분석 툴이 충돌하거나 델타 패치를 적용할 수 없는 등의 불충분한 맥락으로 보고서를 생성할 수 없는 경우를 제외하면 올바른 코드 블록이 주어졌을 때의 모델 성공률을 추정할 수 있습니다. 이러한 경우, 맥락에서 올바른 코드 블록이 제공될 때의 LLM 성공률은 약 96%입니다(그림 2).
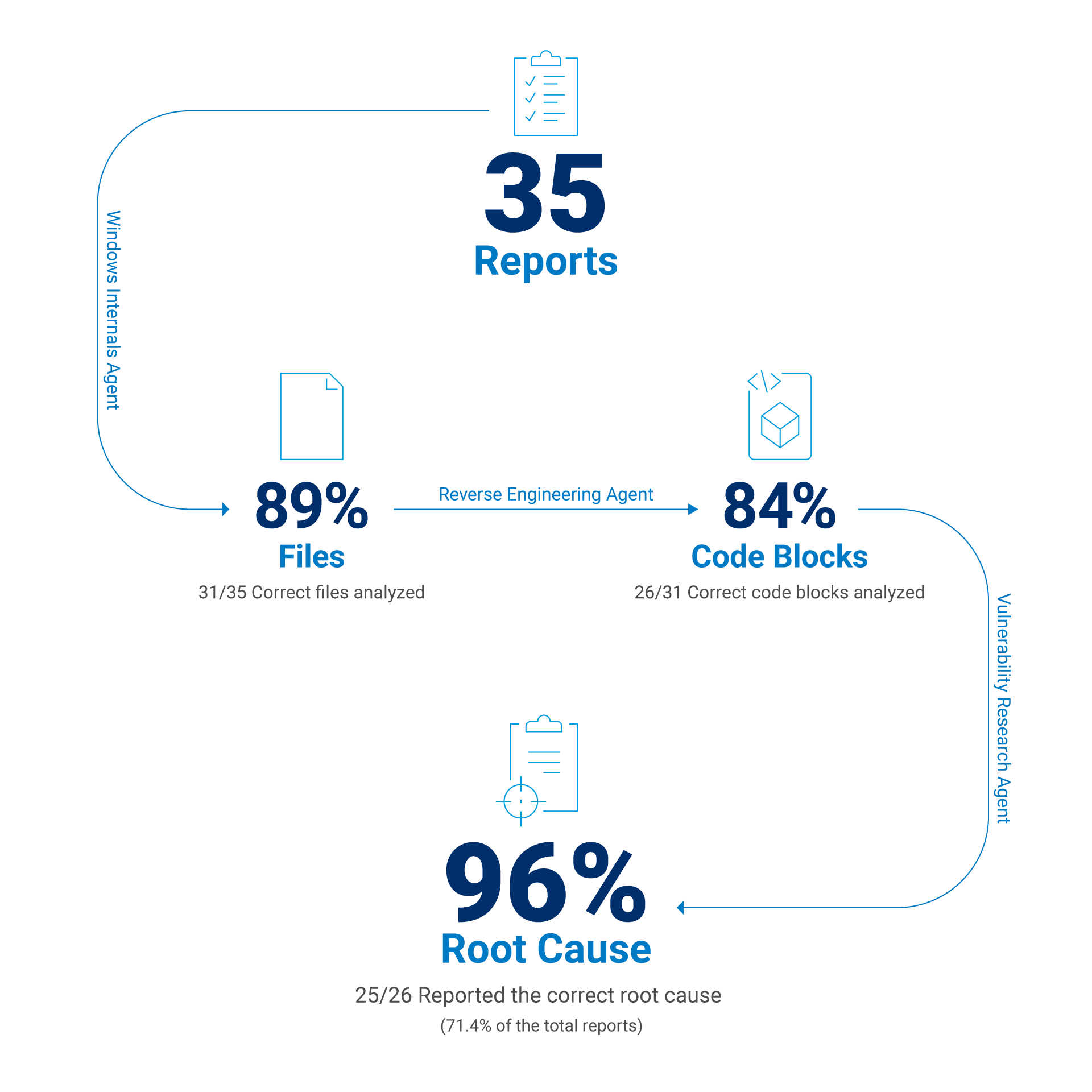 그림 2: 선택된 CVE 관련 보고서의 평가 결과
그림 2: 선택된 CVE 관련 보고서의 평가 결과
CVE 보고서와 해당 구성요소
그 결과, 꼼꼼히 조사하여 공유할 만한 몇 가지 흥미로운 사용 사례를 발견했습니다. 모든 사용 사례의 보고서 구조는 동일합니다.
보고서를 구성하는 CVE 세부 정보
보고서의 핵심 요소인 RCA
패치 전후를 비교할 수 있는 패치 코드 스니펫
취약점이 트리거되는 방식에 대한 하향식 개요
패치에 대한 강조 설명
취약점을 악용할 수 있는 공격 기법
취약점에 대한 명확하고 상세한 영향 분석
또한 모든 보고서의 마지막 섹션에서는 패치의 효과를 확인하고 패치를 우회할 수 있는 방법을 검토합니다.
사례 연구
다음 네 가지 사례 연구에서는 당사 프레임워크의 강점과 약점, 그리고 이 프레임워크가 완전히 실패한 부분을 알 수 있는 몇 가지 흥미로운 사례를 살펴봅니다.
사례 #1: 마운트 후 공격
Akamai가 분석한 취약점 중 하나는 CVE-2025-24991로, MSRC(Microsoft Security Response Center)에 따르면 “권한이 있는 공격자가 Windows NTFS에서 읽는 범위를 벗어나 로컬에서 정보를 공개할 수 있다”는 버그입니다. 또 다른 정보는 FAQ에서 확인할 수 있는데, 여기서는 “공격자는 취약한 시스템의 로컬 사용자를 속여 특수하게 조작된 VHD를 마운트해 취약점을 트리거할 수 있다”고 설명합니다.
이제 이 취약점은 NTFS 구성요소와 관련이 있는 것으로 밝혀졌으며, 이는 ntfs.sys의 개입을 암시할 수 있습니다.
또 다른 단서는 VHD 파일 마운팅에 의해 취약점이 트리거된다는 점입니다. 패치를 수동으로 분석하는 데는 짧아도 몇 시간이 걸렸겠지만, PatchDiff-AI 툴을 사용하여 그 시간을 몇 분으로 최소화할 수 있었습니다. 이러한 장점은 이 사례에서와 같이 근본 원인을 식별할 수 있는 명확한 경로가 없는 경우에도 툴이 제대로 작동한다는 점에서 더욱 극대화됩니다.
이 사례의 경우 이 시스템에서는 KB5053598 업데이트에서 파일에 적용된 가장 관련성 높은 17가지 변경 사항 내에서 근본 원인을 찾았다고 주장합니다. 보고서 전문은 GitHub 리포지토리에서 확인할 수 있으며, 아래에서는 당사에서 진행한 평가 프로세스를 다룹니다.
먼저, 이 툴은 관련 구성요소(실제로 ntfs.sys임)와 관련 함수 ReadRestartTable()을 출력합니다. 로직의 목적에 대한 간단한 설명도 출력합니다(그림 3).
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().다음으로, CWE 인덱스와 관련된 취약점 클래스가 있습니다. 이 사례에서는 CWE-125: 범위를 벗어난 읽기입니다. 이는 이 보고서를 작성할 때 LLM이 어떤 취약점을 찾고 있는지 이해하는 데 도움이 됩니다.
그림 4는 툴 RCA의 실제 아웃풋입니다. 이는 무엇이 잘못되었는지 명확하게 설명하고 문제를 정확하게 지적합니다.
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.IDA와 BinDiff를 사용하여 이러한 결과를 조사한 결과, 정확한 곳을 찾았음을 알 수 있었습니다. 또한 Microsoft는 취약점 수정 사항을 적용하지 않도록 기능 플래그를 사용하고 있으므로 예상치 못한 동작이 발생할 경우 되돌릴 수 있습니다(그림 5).
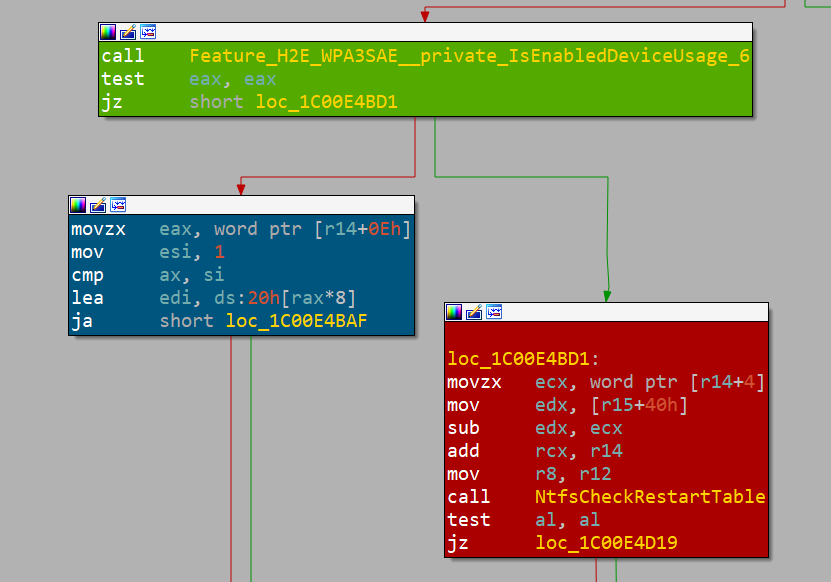 그림 5: Microsoft 피처 플래그(초록색 블록), 수정된 경로(파란색 블록), 그리고 취약한 경로(빨간색 블록)
그림 5: Microsoft 피처 플래그(초록색 블록), 수정된 경로(파란색 블록), 그리고 취약한 경로(빨간색 블록)
이 보고서에서는 함수의 디컴파일된 취약한 부분의 코드 스니펫을 찾아 취약한 코드를 검토할 수 있습니다(그림 6).
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```이 보고서의 하이라이트 중 하나는 하향식 트리거 섹션입니다. 이 섹션에서 LLM은 해당하는 경우 취약점을 트리거하기 위해 취해야 할 가능한 조치를 제안하며, 실용적인 악용 세부 정보를 제공합니다(그림 7).
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.후속 프롬프트를 활용하면 디컴파일된 코드를 추가로 분석하고 훨씬 더 많은 정보를 발견하며 최소한의 개념 증명(PoC)을 제안할 수도 있습니다.
또 다른 유용한 인사이트를 공격 기법 섹션에서 찾을 수 있으며, 여기서는 취약점 악용에 대한 대략적인 정보를 제공하므로 취약점의 범위, 그리고 공격자가 취약점을 악용하기 위해 무엇을 필요로 하는지 알 수 있습니다(그림 8).
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.나머지 섹션에서는 패치 자체에 대한 보다 일반적인 설명과 패치가 시스템의 보안에 미치는 영향에 대해 설명합니다. 그러나 마지막 섹션에서는 LLM에 패치의 취약점을 찾아내 수정 사항 내에서 또 다른 취약점을 금방 찾아낼 수 있는지 확인해 보라고 요청했습니다. 이 사례의 경우 LLM은 패치가 완벽하다고 다음과 같이 평가했습니다. “모든 오류 경로가 범위를 벗어나는 접속이 발생하기 전에 차단됩니다.”
사례 #2: 시스템을 십분 활용할 수 있는 최적의 상황
탐지 또는 방어에 중점을 둔 팀이 자동으로 생성된 IDA 데이터베이스와 BinDiff 아웃풋을 기준으로 보고서를 평가하는 것은 가치가 있으며, 그것만으로도 충분한 경우가 많습니다. 하지만 Akamai의 접근 방식은 한 차원 더 높습니다. 이 시스템은 경우에 따라 단순한 분석을 넘어 실제로 악용을 일으킬 수 있어 공격 목적에도 유용할 수 있습니다.
예를 들어, 2025년 6월 업데이트(KB5060842)에서 패치된 취약점인 CVE-2025-32713은 다음과 같이 기술되었습니다. “Windows Common Log File System Driver의 힙 기반 버퍼 오버플로우를 통해 권한이 부여된 공격자가 로컬에서 권한을 상승시킬 수 있습니다.” 약 2분 만에 Akamai의 툴은 문제의 원인이 CClfsLogFcbPhysical::ReadLogBlock()라고 지적하는 보고서를 생성했습니다.
이 시점에서 악용 문제를 해결하는 방법에는 두 가지가 있습니다.
함수와 호출자를 사용자 모드 호출까지 수동으로 되돌림
LLM이 해당 작업을 대신하고 PoC를 자율적으로 구현
단, 종종 그렇듯이 세 번째 옵션도 있습니다. 바로 하이브리드 접근 방식입니다. 간접 코드 흐름을 확인하고 바이너리의 논리 부분 간의 복잡한 연관 관계를 본인이 직접 파악하는 동안, 리버스 엔지니어링의 어려운 작업을 수행하도록 LLM에 지시하세요. 그러면 LLM이 더 나은 결과를 도출할 수 있습니다.
이러한 방법으로 당사에서는 불과 몇 시간 만에 BSOD(Blue Screen of Death) 악용을 달성했습니다(그림 9).
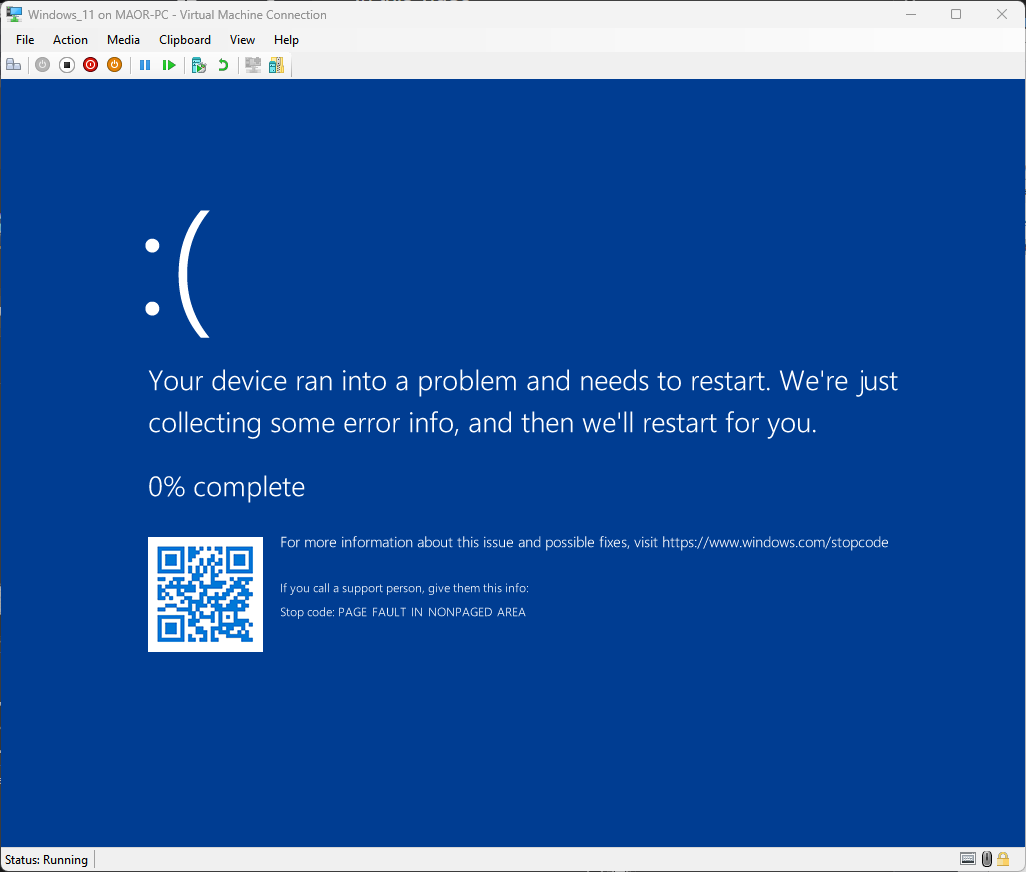 그림 9: CVE-2025-32713 PoC 실행 중 발생한 BSOD
그림 9: CVE-2025-32713 PoC 실행 중 발생한 BSOD
취약점 트리거 흐름을 이해하기 위한 여정은 RCA 섹션에 설명된 대로 제안된 취약한 코드를 평가하는 것으로 시작되었습니다. 패치가 보안 취약점을 수정하려 한다는 사실을 알게 된 연구자들은 인풋/아웃풋 제어(IOCTL) 0x80076832까지의 호출 흐름을 분석했습니다.
이에 대응하는 사용자 모드를 찾던 중, 두 후보가 발견되었습니다. 즉, clfsw32.dll이 해당 IOCTL을 호출하기 위한 직접 경로로 함수 ReadLogRecord를 내보내는 것이었습니다(그림 10).
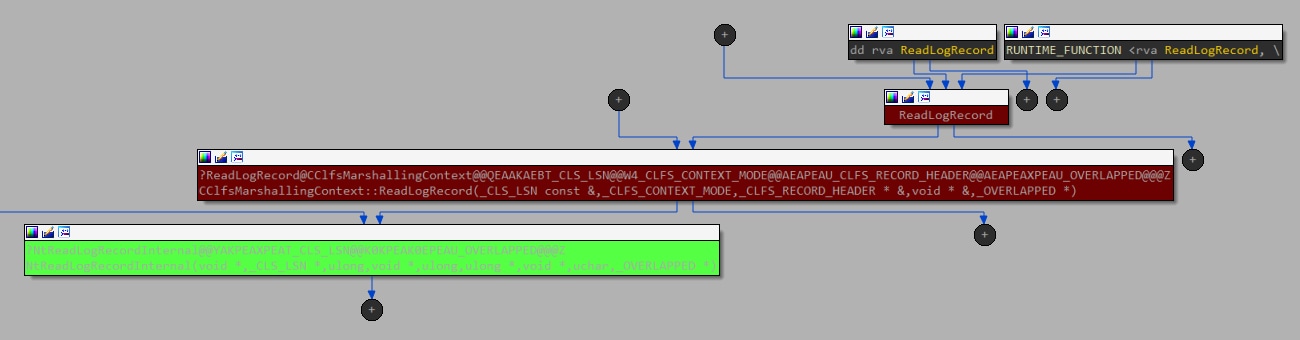 그림 10: 사용자 모드(User Mode)에서 익스포트된 메서드로 시작하여 커널 드라이버(IOCTL 호출 사용)까지 이어지는 호출 흐름 그래프(Call flow graph)
그림 10: 사용자 모드(User Mode)에서 익스포트된 메서드로 시작하여 커널 드라이버(IOCTL 호출 사용)까지 이어지는 호출 흐름 그래프(Call flow graph)
모든 단계에서 당사는 LLM이 해당 지식의 일부를 학습했다는 점을 고려하여 LLM이 로직을 리버스 엔지니어링하고 분석하는 데 어떻게 도움이 될 수 있는지를 평가했습니다. 그림 11은 제공된 버퍼 크기인 v4의 조건 요구사항을 LLM이 해결하는 과정을 보여줍니다.
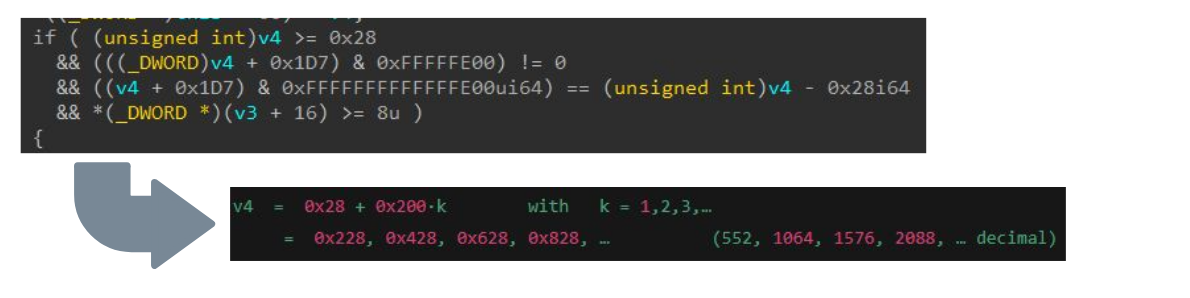 그림 11: LLM을 사용한 유효성 검사 분석
그림 11: LLM을 사용한 유효성 검사 분석
LLM이 도출한 관찰 결과에는 훌륭한 것도 있었지만, 그 결과가 오해를 일으킬 만한 사례도 있었습니다. CVE-2025-32713으로 다시 살펴보면 그 응답의 하나로 그림 12와 같은 내용이 보고서에 담겨 있었습니다.
“crafts the log header so that the page size (v48) exceeds the supplied buffer”이 응답은 상당히 혼란스러웠고 결국 취약한 코드를 트리거하는 방법을 이해하기 어렵게 했습니다. 사실 이로 인해 관련성이 전혀 없는 리서치를 진행하게 되어 연구원들은 이미 방어 조치가 적용된 .blf 파일 구조를 조작하려고 시도하기에 이르렀습니다. 나중에는 섹터마다 물리적 바이트와 논리적 바이트가 서로 다른 가상 디스크를 생성하고 디버깅을 통해 해당 동작을 분석했습니다.
LLM이 대부분의 작업을 처리했다고 해도 무방하지만, 경험 많은 연구원의 면밀한 감독이 필요했습니다. LLM은 지원이 올바르게 제공되어야 인간에게 도움이 되는 툴입니다.
이 모델은 때때로 비생산적인 방향으로 이끌 수 있으며, 효과를 제대로 발휘하려면 사람의 지도가 필수적입니다. 하지만 결과가 그 효용을 입증해 줍니다. LLM은 취약한 코드를 정확하게 탐지하고, 호출 흐름을 정확하게 추적했으며, v27의 잘못된 할당으로 인해 CcCopyRead()에서 오버플로우가 어떻게 발생했는지를 설명했습니다.
사례 #3: 건초 더미 속의 바늘
LLM 아웃풋을 주의해서 사용해야 하는 경우가 있습니다. 환각만이 LLM의 리스크는 아닙니다. 이러한 점을 다양한 LLM 인터페이스에서 거듭 강조하고 있습니다(예: “ChatGPT는 실수를 저지를 수 있습니다. 중요 정보를 확인하세요.”)
시스템에서 인풋과 아웃풋을 검증하고 여러 경로를 검사하여 근본 원인을 식별하려고 시도하지만 그래도 주의해야 합니다. 조건이 너무 광범위하고 모호하기 때문에 이러한 작업이 거의 불가능한 경우가 있습니다.
5월 KB5058411 업데이트의 CVE-2025-29974를 살펴보겠습니다. 취약점에 대한 MSRC 정보 페이지에는 “Windows 커널의 정수 언더플로우(랩 또는 랩어라운드)를 통해 권한이 없는 공격자가 인접 네트워크를 경유하여 정보를 공개할 수 있다”고 다소 모호하게 명시되어 있습니다.
다음으로, MSRC 페이지에서는 공격자가 근처에 있어야 한다고 명시되어 있습니다. 즉, 공격자가 무선 전송을 수신하려면 범위 내에 있어야 합니다. 이는 명백히 정보의 에어 갭 유출에 대한 이야기입니다. 그러나 그 방법이나 그에 사용되는 하드웨어는 불명확합니다. 이러한 맥락이 누락되면 유효한 보고서를 받을 가능성이 줄어듭니다.
CVE-2025-29974와 관련하여 당사에서는 툴을 실행하여 이름이 지정되지 않은 두 가지 함수인 sub_1408E6D3C 및 sub_1408FAD58에 대한 보고서를 받았습니다. 여기서는 편의를 위해 이를 primary()와 secondary()로 지칭하겠습니다. 그림 13은 해당 함수에 대한 BinDiff 화면으로, 여기서 두 함수가 너무 다르다는 점을 쉽게 알 수 있습니다.
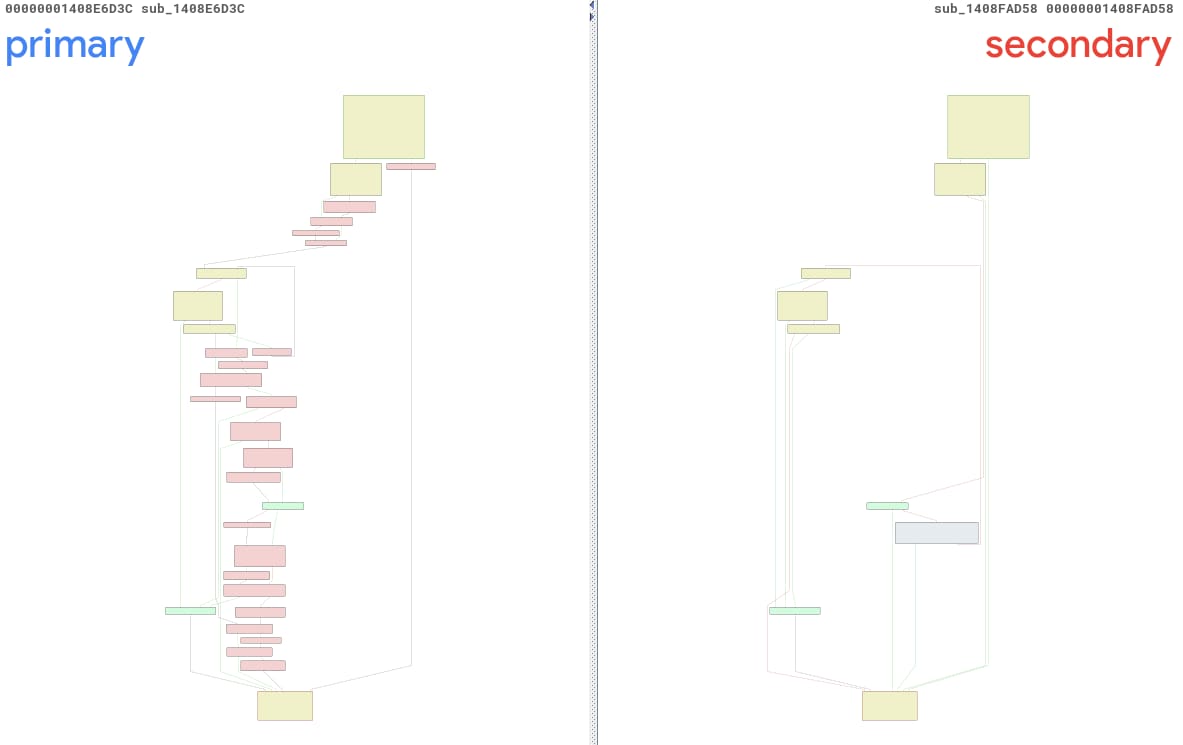 그림 13: PatchDiff-AI를 통해 자동으로 생성된 변경 사항의 BinDiff 뷰
그림 13: PatchDiff-AI를 통해 자동으로 생성된 변경 사항의 BinDiff 뷰
면밀히 살펴보면 다른 주소에 있는 전혀 다른 메서드인 sub_1408E7738가 정확한 주요 함수임을 식별할 수 있습니다. 이러한 혼선이 발생한 주된 이유는 해당 업데이트를 통해 ntoskrnl.exe 파일이 대폭 수정되었기 때문입니다. 3,791개의 함수가 수정되어 패치 전후의 정확한 쌍을 찾을 확률이 급격히 감소했습니다.
이 사례에 대한 보고서와 함께 제공된 신뢰도는 0.2로, 이는 보고서에서 찾아냈다고 하는 취약점의 정확도를 20%만 신뢰할 수 있음을 나타냅니다. 코드 블록 수정 횟수가 많은 데다가, 이러한 신뢰도로 인해 미흡한 결과가 나올 수밖에 없었습니다.
사례 #4: 너무 취약함
업데이트로 해결되는 구성요소에 여러 취약점이 있는 경우가 있습니다. 이는 하나의 로직 결함에 클래스가 서로 다른 일련의 취약점이 포함될 수 있기 때문에 드문 일이 아닙니다.
KB5055523(2025년 4월) 업데이트를 살펴보면 CVE-2025-24058, CVE-2025-24060, CVE-2025-24062, CVE-2025-24073, CVE-2025-24074라는 버그를 찾을 수 있습니다(그림 14). 이들 모두 바탕 화면 창 관리자(DWM)와 관련이 있으며 “CWE-20: 잘못된 인풋 검증으로 인한 것이기 때문에 모델 입장에서는 구별되지 않고 모호할 수 있습니다.
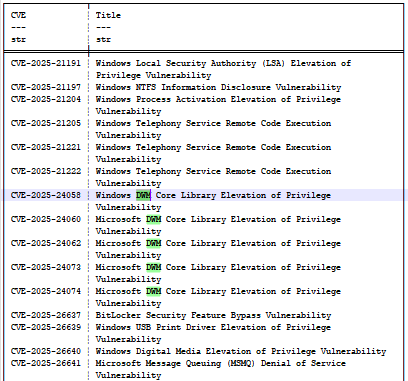 그림 14: 2025년 4월 업데이트 버그의 부분 목록
그림 14: 2025년 4월 업데이트 버그의 부분 목록
LLM 사용에는 단점이 있습니다. 일반적인 단점은 비용을 초래한다는 점입니다. LLM은 필요한 맥락이 일치하지 않는 경우에도 한 번의 렌디션(iterations)으로 작업을 수행하려고 시도합니다. 보다 정확한 결과를 얻으려면 휴리스틱을 통해 결과를 평가하고 LLM이 더 나은 변형을 만들 수 있도록 맥락을 세밀하게 조정해야 합니다.
Akamai는 2025년 4월 업데이트 버그 보고서를 사용해 해당 사용 사례의 결과를 평가했습니다. 근본 원인과 추가 정보를 비교 분석하여 여러 취약점이 LLM에 어떤 영향을 미칠 수 있는지 파악할 수 있었습니다(표).
CVE | 주요 오류 함수 | 버그 클래스 | 근본 원인 |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | 부적절한 인풋 검증으로 인한 힙 기반 메모리 손상 / 동적 어레이 확장 시 정수 오버플로우(CWE-787을 초래하는 CWE-20). | 동일한 PreSubgraph 정수 랩이 occlusion-info 버퍼 오버플로우 트리거 |
CVE-2025-24073 | COcclusionContext::PreSubgraph | 부적절한 인풋 검증으로 인한 힙 기반 버퍼 오버플로우/정수 오버플로우(메모리 손상을 초래하는 CWE-20) | 동일한 PreSubgraph 정수 랩이 occlusion-info 버퍼 오버플로우 트리거 |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | 범위를 벗어난 힙 쓰기를 초래하는 부적절한 인풋/범위 검증 | 동일한 PreSubgraph 정수 랩이 occlusion-info 버퍼 오버플로우와 다른 오버플로우를 트리거 |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | 해제된 오브젝트 포인터를 암시적 this 포인터로 전달함으로써 발생하는 UAF(use-after-free)/타입(type) 혼동(CWE-416, CWE-843) | 해제된 CD3DDevice 포인터가 CDeviceManager this로 재사용됨 |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | 호출자가 제공한 목록 길이에 대한 부적절한 인풋 검증으로 인한 힙 기반 버퍼 오버플로우(CWE-122를 초래하는 CWE-20) | CollectOverlayCandidates를 사용한 힙 오버플로우 |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | 포인터 잘림/부적절한 인풋 검증으로 인한 UAF(use-after- free)/권한 상승(CWE-704와 관련된 CWE-20) | 인수가 __int64로 확장됨, IsOverlayCandidateCollectionEnabled()가 추가됨 |
LLM을 통해 확인된 여러 취약점 및 해당 RCA
이 표는 단순히 보고서의 내용을 반영한 것입니다. 2025년 4월 업데이트 버그를 평가한 결과 CVE-2025-24074, CVE-2025-24073, CVE-2025-24060의 중복이 발견되었습니다. 세 가지 모두 사소한 변경이나 추가가 있는 동일한 함수를 참조합니다.
CVE-2025-24058(dwmcore.dll)에 포함된 내용은 CVE-2025-24060의 ComputeOverlayConfiguration과 중복되는 것으로 보입니다. 그러나 CVE-2025-24058(dwmcorei.dll)과 CVE-2025-24062는 완전히 다른 근본 원인을 해결하는 것으로 보입니다.
LLM은 결정론적인 시스템이 아니기 때문에 인풋은 동일해도 아웃풋은 달라질 수 있습니다. 인풋 맥락의 변경에 따라, 그 변경 내용이 아무리 경미하더라도 LLM의 아웃풋에 어떻게 영향을 미치고 두 가지 서로 다른 보고서가 생성되는지 관찰할 수 있습니다.
가격 측면의 이점
PatchDiff-AI는 다양한 LLM 모델을 갖춘 감독형 다중 에이전트 아키텍처를 기반으로 높은 정확도를 유지하는 동시에 비용을 절감합니다. OpenAI 모델을 사용해 하나의 보고서를 생성하는 데 드는 비용을 분석해 보면 최대 비용은 US$1.43에 달합니다.
실제로 당사의 경우 3월, 4월, 5월 업데이트에서 Windows 11 24H2 x64로만 필터링하여 131개의 보고서를 생성했습니다. 보고서당 평균 비용은 약 US$0.14였습니다. 매일(아니면 매시간) 얼마나 많은 취약점과 싸우고 있는지를 고려하면 규모가 커질수록 이러한 비용도 상당히 증가할 수 있습니다.
Windows 내부 및 취약점 리서치 에이전트의 확장된 개선과 같은 완전 자율 기능을 사용할 경우, 가격 계산 시 상한선은 있을 수 있지만 시스템의 비결정론적 특성 때문에 평균값을 도출할 수는 없습니다.
결론
사이버 보안 영역에서 AI, 특히 LLM의 활용은 앞날이 밝습니다. LLM은 매우 복잡하지만 방법론적인 프로세스를 간단한 워크플로우로 쉽게 변환할 수 있으며 다양한 보안팀의 파이프라인에 통합될 수 있습니다.
Akamai의 리서치에 따르면, 실용적이면서도 상당한 정확성과 합리적인 비용으로 취약점에 대해 완전히 자동화된 RCA가 가능합니다.
문제를 더 작은 작업으로 세분화하고, Windows 내부 추론, 리버스 엔지니어링 워크플로우, 취약점별 분석을 함께 사용하는 특화된 다중 에이전트 아키텍처에 문제를 조정함으로써 Akamai는 LLM이 기존의 한계를 극복할 수 있도록 했습니다. 이러한 방식과 PatchDiff-AI 지원 툴은 다른 제품 및 플랫폼에도 적용할 수 있습니다.
보안팀은 Akamai 시스템을 사용해 포괄적인 탐지 기능을 구축하고, 취약점을 효과적으로 방어하고, 시스템에 대한 침투 및 회귀 테스트를 만들 수 있습니다. 또한, Akamai 시스템은 알려진 취약점을 트리거하는 프로세스를 단축해 취약한 공유 코드 기반에 대해 더욱 심층적인 리서치를 수행하고 변형을 발견할 수 있도록 지원합니다.

태그


