
Sumário executivo
Nesta pesquisa, examinamos o uso de grandes modelos de linguagem para encontrar a causa raiz das vulnerabilidades corrigidas.
Desenvolvemos um sistema multiagente chamado PatchDiff-AI que analisa autonomamente a causa raiz das vulnerabilidades do Patch Tuesday e gera um relatório detalhado.
Esse tipo de análise pode ajudar as equipes de segurança a analisar vulnerabilidades quase instantaneamente, seja para fins defensivos ou ofensivos.
Ao utilizar várias estratégias, conseguimos ajustar nosso sistema para atingir uma taxa de sucesso superior a 80% na geração totalmente automatizada de relatórios, incluindo análise de vetores de ataque e fluxo de acionamento.
Patch Tuesday → Exploit Wednesday
O ciclo regular de atualizações da Microsoft concentra-se nas Patch Tuesdays, a segunda terça-feira de cada mês, quando a empresa divulga uma lista abrangente de CVEs e suas correções correspondentes. Essas correções são fornecidas como arquivos Microsoft Standalone Update (MSU), um formato de pacote que aplica atualizações corrigindo ou substituindo arquivos essenciais do sistema.
A Patch Tuesday é frequentemente seguida pelo que é conhecido como “Exploit Wednesday”, quando os invasores correm para descobrir as vulnerabilidades para as quais a Microsoft criou um patch. Ao realizar comparações binárias nos binários atualizados, os invasores podem identificar rapidamente os problemas de segurança subjacentes e tentar explorá-los antes que as organizações tenham implantado amplamente os patches.
Da mesma forma, os defensores muitas vezes se apressam em analisar esses patches para entender as causas das vulnerabilidades, a fim de criar detecções e mitigações.
O estado atual da comparação de patches
Hoje em dia, a difusão de patches é um processo tedioso. Para identificar com sucesso o trecho vulnerável do código, um pesquisador precisaria:
Identificar o arquivo que se suspeita conter a vulnerabilidade
Executar uma comparação binária para identificar as alterações
Isolar as alterações relacionadas à segurança de outras atualizações de código de rotina
Analisar as peças suspeitas e compreender a causa raiz
Examinar dinamicamente os fluxos de chamadas para encontrar possíveis vias de acionamento
Avaliar a conclusão da correção do patch
Essas etapas podem levar semanas para serem realizadas, um problema que é ainda mais ampliado pelo grande volume de vulnerabilidades que são divulgadas simultaneamente a cada mês.
Decidimos encontrar uma maneira melhor, que permitisse aos pesquisadores analisar rapidamente as vulnerabilidades corrigidas e compreender sua causa raiz.
Como usar LLMs para análise de diferenças de patches
Os modelos de linguagem grandes (LLMS) podem gerar estatisticamente informações razoáveis e precisas com base nos dados treinados, juntamente com as entradas do usuário. Mas existem algumas limitações, incluindo uma janela de contexto limitada (que afeta a quantidade de dados que pode processar e seus custos operacionais) e a famosa alucinação do modelo.
Ao longo dos anos, foram publicados muitos artigos sobre a contribuição dos LLMs para o campo da avaliação de vulnerabilidades no setor de segurança. Atualmente, os LLMs parecem ter dificuldades ao analisar software de código fechado e apresentam um desempenho muito melhor quando se trata de código aberto e vulnerabilidades da web, onde o ponto em comum é a presença de código legível por humanos.
O Aardvark e o revisor de segurança Claude Code da OpenAI ainda estão vinculados ao código-fonte legível. Por outro lado, há o Big Sleep do Google Project Zero, que visa descobrir vulnerabilidades de dia zero. Nenhuma das duas abordagens analisa o binário como código fechado.
Apresentando o PatchDiff-AI
Nossa pesquisa adota uma abordagem diferente, utilizando LLM para a análise de causa raiz (RCA) de patches de segurança. Nossa teoria, que parece ter sido validada, era que o contexto adicional fornecido pelo “diff” binário aumentaria significativamente a capacidade do LLM de compreender códigos complexos e de baixo nível.
Para essa tarefa, desenvolvemos um sistema multiagente que automatiza a análise das atualizações da Base de Conhecimento da Microsoft (KB) para uma plataforma específica (Figura 1). Chamamos de PatchDiff-AI.
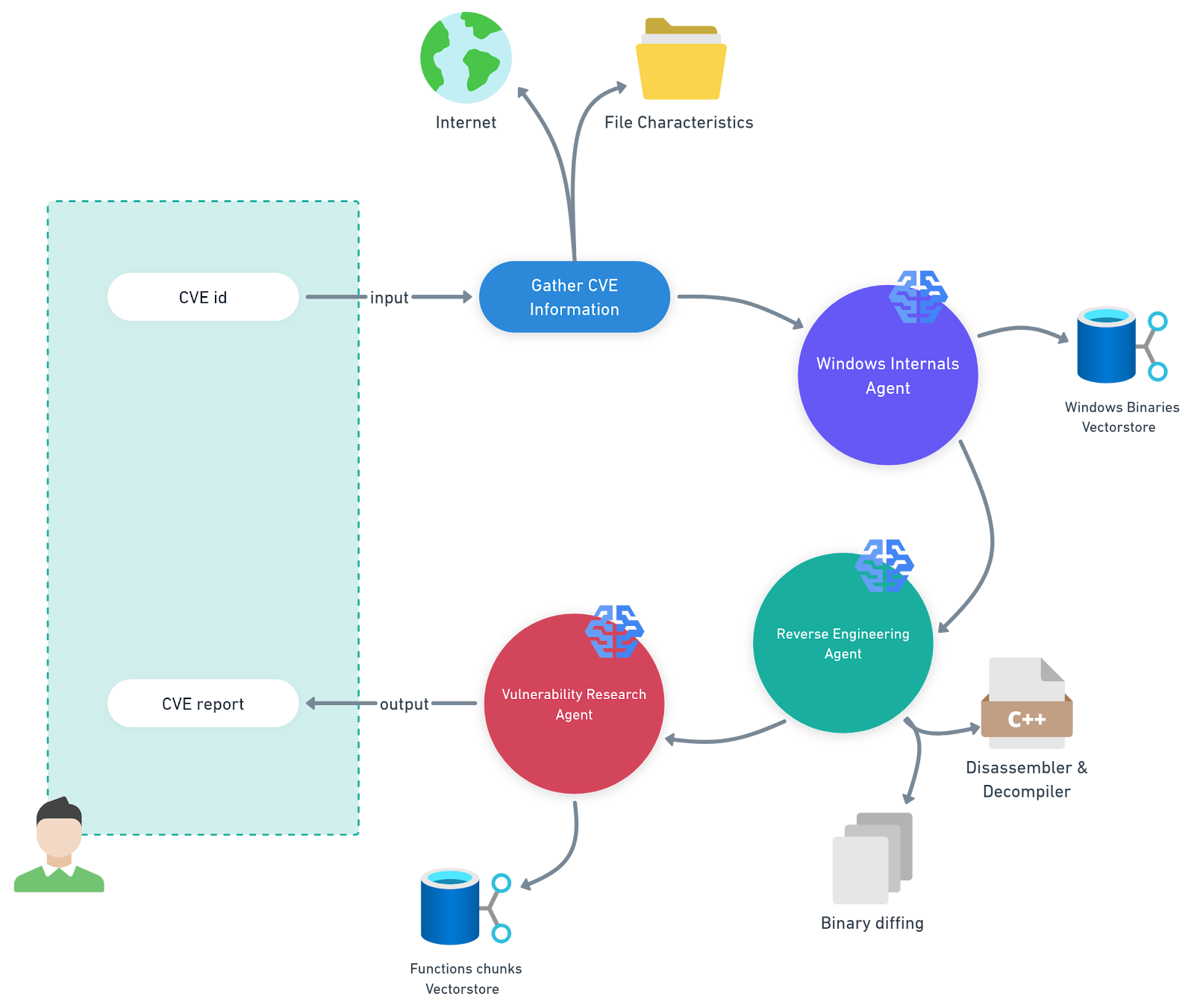 Fig. 1: Ilustração do nosso sistema multiagente, PatchDiff-AI
Fig. 1: Ilustração do nosso sistema multiagente, PatchDiff-AI
Definições PatchDiff-AI
Agente interno do Windows: esse agente usa um pipeline de geração aumentada por recuperação (RAG) apoiado por um armazenamento vetorial que contém binários do Windows e seus metadados de funcionalidade. Isso permite que o agente reduza significativamente o escopo da análise e se concentre nos componentes mais relevantes.
Agente de engenharia reversa: esse agente utiliza ferramentas avançadas de engenharia reversa para a análise e comparação dos arquivos relevantes. Ele anexará os artefatos encontrados ao contexto geral para que outros agentes possam utilizá-los.
Agente de pesquisa de vulnerabilidades: esse agente coordena a análise reunindo todos os artefatos e outras informações existentes no contexto e gerando um relatório consistente.
Metodologia
Devido às limitações da janela de contexto e à alucinação, é fundamental fornecer um contexto relevante e conciso para usar os LLMs da forma mais eficaz possível, mantendo alta precisão na tarefa de isolar componentes de código vulneráveis e, ao mesmo tempo, reduzindo os custos operacionais.
Dividir para conquistar
Um dos detalhes cruciais em nossa implementação foi dividir a análise em várias tarefas menores e focadas, que acabam funcionando como agentes:
Recuperar informações sobre o CVE para criar um perfil
Fazer o download das atualizações relevantes e aplicar as diferenças em relação aos arquivos da versão base
Criar um agente de IA interno do Windows para isolar os arquivos relevantes usando os metadados da vulnerabilidade
Crie um agente de IA de engenharia reversa que possa:
Desmontar e aplicar símbolos, depois exportá-los para comparação binária
Correlacionar os binários, identificar as alterações e os fluxos de chamadas
Identificar o bloco de código vulnerável
Crie um agente de IA para pesquisa de vulnerabilidades que itere por possíveis caminhos de vulnerabilidade para correlacionar e encontrar o melhor resultado possível
Uma das principais vantagens dessa divisão foi que ela nos permitiu usar modelos específicos para cada tipo de tarefa; o OpenAI o4-mini se destacou no enriquecimento de metadados de arquivos, enquanto o OpenAI o3 foi usado para a análise aprofundada definitiva do código suspeito de vulnerabilidade.
Selecionar o modelo certo para a tarefa foi benéfico em dois aspectos: primeiro, pela precisão e, segundo, pelos custos.
Enriquecimento do contexto
LLMs são máquinas que “lembram” uma grande quantidade de informações. Ao acionar o LLM com um prompt, ele será ajustado para fornecer as informações mais relevantes dentro do contexto do prompt.
Cada fragmento de informação que pudermos fornecer ao LLM sobre a vulnerabilidade corrigida ajudará a gerar uma resposta mais precisa e aumentará as chances de localizar o código vulnerável. No entanto, informações ambíguas sobre a vulnerabilidade resultarão em resultados insatisfatórios, se houver.
Enriquecer o contexto com os metadados de vulnerabilidade durante a análise revelou-se crucial. Para alcançar esse enriquecimento, fornecemos ao LLM descrições de KB, descrições de arquivos do sistema e dados binários de diff. Essa abordagem nos permitiu reduzir o número de alterações que precisamos analisar e, portanto, o comprimento do contexto e o número de iterações com o LLM.
Resultados
Para avaliar nossa estrutura, inspecionamos a capacidade do modelo de identificar corretamente:
O arquivo executável vulnerável correspondente ao CVE
A função vulnerável dentro do executável
A causa raiz da vulnerabilidade e explicá-la corretamente
Com base nesses parâmetros, analisamos as três últimas versões do Patch Tuesday para o Windows 11 24H2. Após executar nossa ferramenta e gerar um relatório automatizado, inspecionamos manualmente os resultados selecionados e determinamos a precisão da resposta final do modelo.
Após refinar o contexto e ajustar os vários modelos para as diferentes tarefas, finalmente alcançamos os seguintes resultados:
Identificou o executável correto que foi corrigido para o CVE em questão em 88,6% das vezes
Encontrou a função vulnerável correta 83,9% das vezes
Descobriu a causa raiz correta da vulnerabilidade em 71,4% das vezes
Se excluirmos as falhas na geração de relatórios causadas por contexto insuficiente, como falhas na ferramenta de análise estática ou incapacidade de aplicar um patch delta, podemos estimar a taxa de sucesso do modelo quando ele recebe o bloco de código correto. Nesse caso, a taxa de sucesso do LLM é de aproximadamente 96% quando o bloco de código correto é fornecido no contexto (Figura 2).
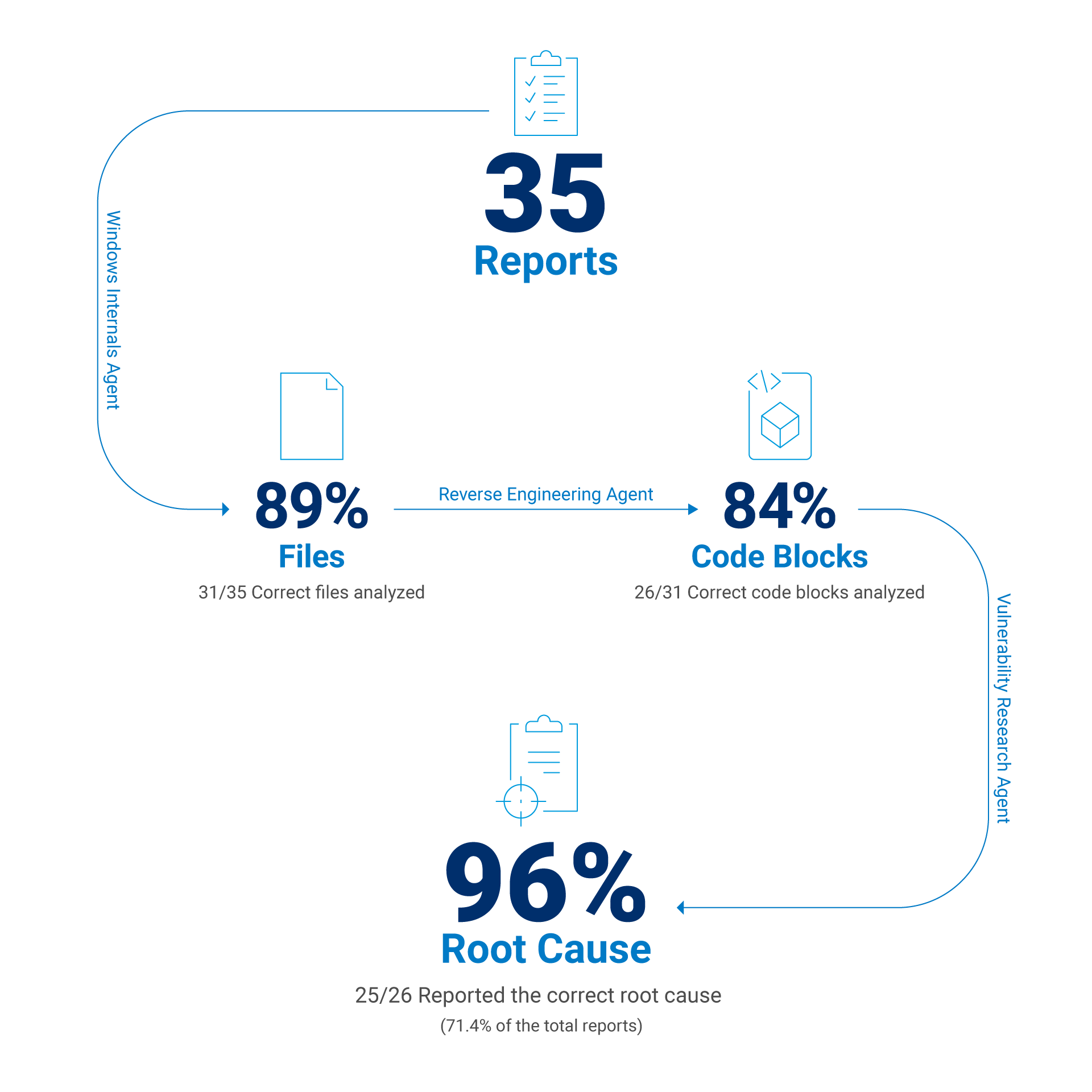 Fig. 2: Resultados da avaliação de relatórios selecionados sobre CVEs
Fig. 2: Resultados da avaliação de relatórios selecionados sobre CVEs
Um relatório CVE, por favor. Obrigado.
Como resultado, encontramos vários casos de uso interessantes que gostaríamos de compartilhar e investigar a fundo. Cada caso de uso tem a mesma estrutura de relatório:
detalhes de CVE que constroem o relatório
A RCA: o cerne do relatório
Um trecho do código do patch, antes e depois
Visão geral de cima para baixo de como a vulnerabilidade pode ser acionada
Uma descrição destacada do patch
Um vetor de ataque que poderia explorar a vulnerabilidade
Um impacto claro e detalhado da vulnerabilidade
Além disso, a última seção de cada relatório tenta questionar a eficácia do patch e analisar uma possível maneira de burlá-lo.
Estudos de caso
Nos quatro estudos de caso a seguir, exploraremos alguns casos interessantes que destacam onde nossa estrutura se destaca, onde ela enfrenta dificuldades e onde falha completamente.
Caso nº 1: Montar e quebrar
Uma das vulnerabilidades que analisamos foi a CVE-2025-24991, um bug que, de acordo com o Centro de Resposta de Segurança da Microsoft (MSRC), permite que um invasor autorizado divulgue informações localmente por meio de uma leitura fora dos limites no Windows NTFS. Outra informação vem da seção de perguntas frequentes, que afirma: “Um invasor pode induzir um usuário local em um sistema vulnerável a montar um VHD especialmente criado que, então, acionaria a vulnerabilidade”.
Agora, a vulnerabilidade está claramente relacionada ao componente NTFS, o que pode definitivamente implicar o envolvimento de ntfs.sys.
Outra pista é o fato de que a vulnerabilidade é acionada por um arquivo VHD montado. Analisar o patch manualmente provavelmente levaria horas, na melhor das hipóteses, mas o uso da ferramenta PatchDiff-AI reduziu esse tempo para alguns minutos. Isso é ainda mais reforçado pelo fato de que nossa ferramenta funciona tão bem quando não há um caminho óbvio para identificar a causa raiz, como foi o caso aqui.
Nesse caso, o sistema afirma ter encontrado a causa raiz entre as 17 alterações mais relevantes feitas no arquivo na atualização KB5053598. O relatório completo pode ser encontrado em nosso repositório GitHub, e nosso processo de avaliação segue abaixo.
Primeiro, nossa ferramenta gera o componente relevante, que é de fato o ntfs.sys, e a função relevante ReadRestartTable(). Ele também exibe uma breve explicação sobre o que a lógica foi projetada para fazer (Figura 3).
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().Em seguida, temos a classe de vulnerabilidade correlacionada ao índice CWE, que neste caso é CWE-125: Leitura fora dos limites. Isso nos ajudará a entender qual vulnerabilidade o LLM está procurando ao compor este relatório.
A Figura 4 mostra o resultado real da RCA da nossa ferramenta. Ele descreve claramente o que deu errado e identifica o problema com precisão.
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.A inspeção desses resultados usando IDA e BinDiff revela que esse é realmente o local correto. E sabemos disso porque a Microsoft está usando sinalizadores de recurso para desativar a correção da vulnerabilidade; dessa forma, ela pode ser revertida em caso de comportamento inesperado (Figura 5).
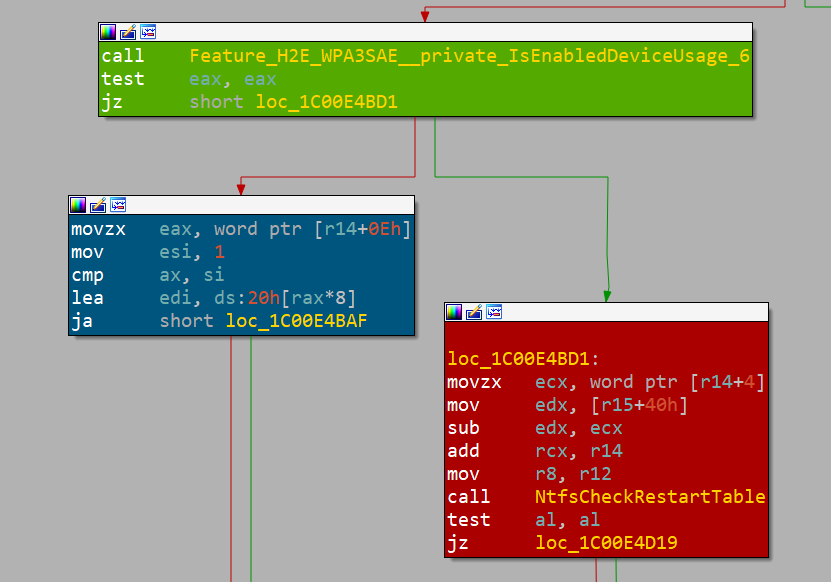 Fig. 5: Feature flag da Microsoft (bloco verde), caminho corrigido (bloco azul) e caminho vulnerável (bloco vermelho)
Fig. 5: Feature flag da Microsoft (bloco verde), caminho corrigido (bloco azul) e caminho vulnerável (bloco vermelho)
No relatório, podemos encontrar os trechos de código da parte vulnerável da função descompilada e revisar o código vulnerável (Figura 6).
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```Um dos destaques do relatório é a seção sobre acionamento de cima para baixo. Nesta seção, o LLM sugere possíveis etapas que devem ser seguidas para acionar a vulnerabilidade, quando aplicável, chegando a apresentar detalhes práticos de exploração (Figura 7).
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.Quando combinada com prompts de acompanhamento, nossa ferramenta analisa ainda mais o código descompilado e revela significativamente mais informações, podendo até mesmo sugerir uma prova de conceito (PoC) mínima.
Outra informação útil pode ser encontrada nas seções sobre vetores de ataque, que fornecem uma visão geral da exploração de vulnerabilidades. Isso dá uma ideia do alcance da vulnerabilidade e do que um invasor precisa para explorá-la (Figura 8).
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.As seções restantes fornecem uma descrição mais geral do patch em si e seu impacto na segurança do sistema. No entanto, na última seção, pedimos ao LLM para tentar desafiar o patch e ver se havia uma possível vitória rápida ao identificar outra vulnerabilidade dentro da correção. Neste caso, avaliou-se que o patch está completo: "Todos os caminhos de erro agora são acionados antes de qualquer acesso fora do intervalo potencial."
Caso nº 2: Quando as estrelas se alinham
É valioso, e muitas vezes suficiente para equipes focadas em detecção ou mitigação, avaliar o relatório em relação ao banco de dados IDA gerado automaticamente e à saída BinDiff. No entanto, nossa abordagem vai além e pode ser útil também para fins ofensivos, pois, em alguns casos, o sistema pode ir além da análise e realmente produzir uma exploração funcional.
Por exemplo, a CVE-2025-32713, uma vulnerabilidade que foi corrigida na atualização de junho de 2025 (KB5060842), foi descrita como: "O estouro de buffer baseado em pilha no driver do sistema de arquivos de log comum do Windows permite que um invasor autorizado eleve privilégios localmente." Em aproximadamente dois minutos, nossa ferramenta gerou um relatório que rastreou o problema até CClfsLogFcbPhysical::ReadLogBlock()..
Neste momento, existem duas maneiras de enfrentar o desafio da exploração.
Reverta manualmente a função e suas chamadas até a chamada no modo de usuário
Deixe que o LLM faça isso por nós e crie autonomamente um PoC
No entanto, como costuma acontecer, há uma terceira opção: a abordagem híbrida. Peça ao LLM para fazer o trabalho pesado da engenharia reversa enquanto você determina os fluxos indiretos do código e resolve as conexões complexas entre as partes lógicas do binário. Isso permitirá que o LLM apresente melhores resultados.
Com essa prática, conseguimos uma exploração da tela azul da morte (BSOD) em apenas algumas horas (Figura 9).
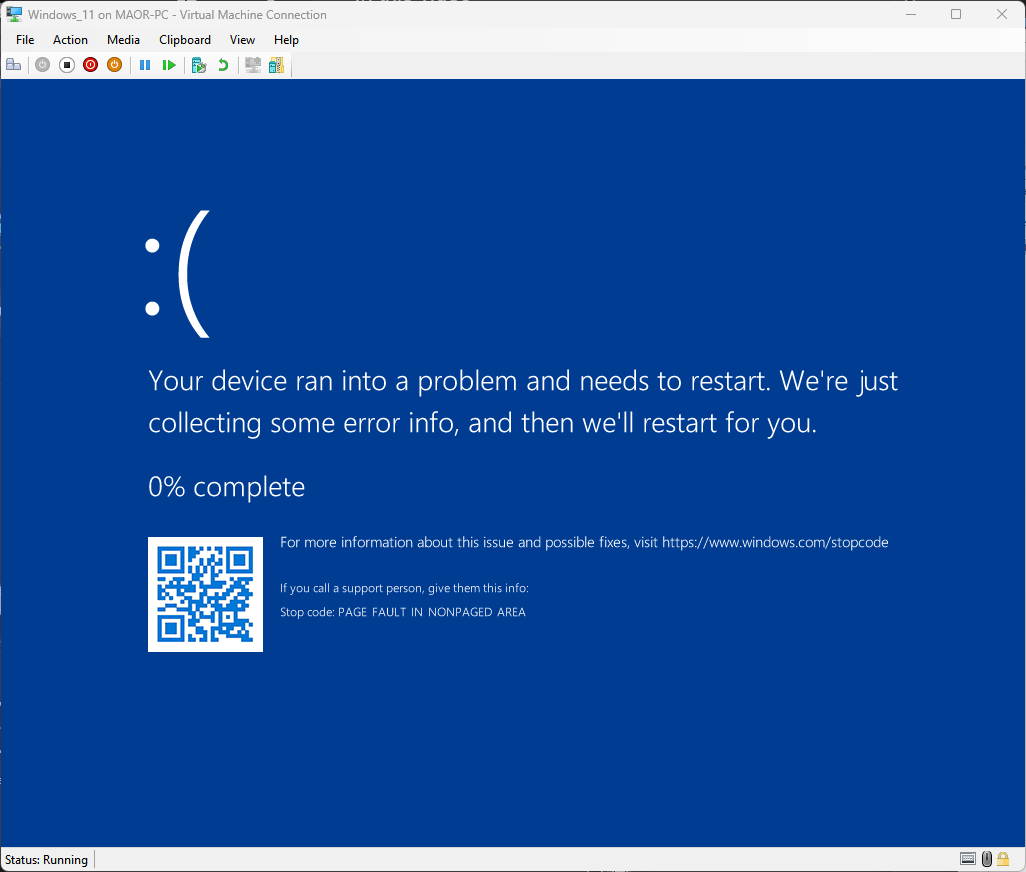 Fig. 9: BSOD durante a execução da PoC do CVE-2025-32713
Fig. 9: BSOD durante a execução da PoC do CVE-2025-32713
A jornada para compreender o fluxo de gatilhos de vulnerabilidade começou com a avaliação do código vulnerável sugerido, conforme descrito na seção RCA. Depois que percebemos que o patch tenta corrigir uma falha de segurança, analisamos o fluxo de chamadas até o controle de entrada/saída (IOCTL) 0x80076832.
Ao procurar as contrapartes no modo de usuário, encontramos dois candidatos, já que o clfsw32.dll exporta a função ReadLogRecord com um caminho direto para chamar este IOCTL (Figura 10).
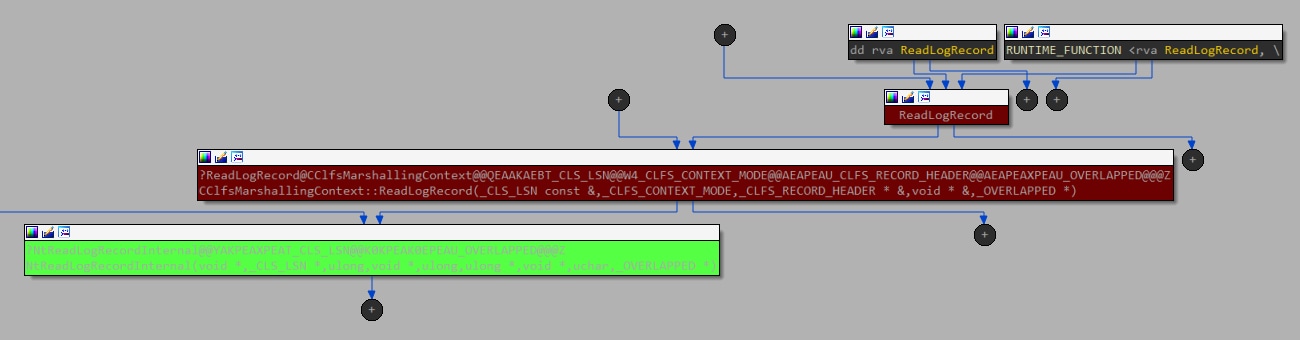 Fig. 10: Gráfico do fluxo de chamadas, começando com um método exportado do modo de usuário até o driver de kernel (usando a chamada IOCTL)
Fig. 10: Gráfico do fluxo de chamadas, começando com um método exportado do modo de usuário até o driver de kernel (usando a chamada IOCTL)
A cada etapa, avaliamos como o LLM pode ajudar a reverter e analisar a lógica, considerando que ele foi treinado com partes desse conhecimento. A Figura 11 mostra como isso poderia resolver a exigência da condição para a v4, que é o tamanho do buffer que fornecemos.
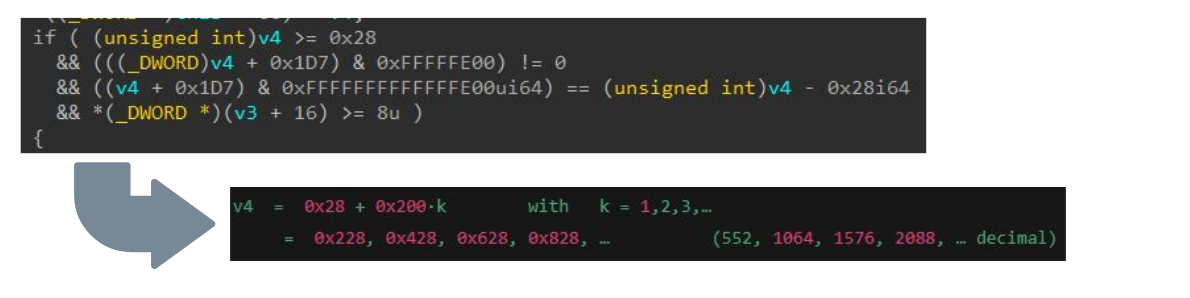 Fig. 11: Uso de LLM para analisar uma verificação de validação
Fig. 11: Uso de LLM para analisar uma verificação de validação
Embora tenhamos testemunhado algumas observações excelentes que o LLM conseguiu encontrar, houve alguns casos em que os resultados foram enganosos. Voltando ao CVE-2025-32713, em uma de suas respostas, nosso relatório continha a citação mostrada na Figura 12.
“crafts the log header so that the page size (v48) exceeds the supplied buffer”Essa resposta foi bastante confusa e, no fim das contas, nos impediu de entender como acionar o código vulnerável. Na verdade, isso nos levou a um caminho de pesquisa totalmente irrelevante (tentamos manipular a estrutura do arquivo .blf que já tinha medidas de mitigação em vigor). Posteriormente, criamos discos virtuais com diferentes bytes físicos e lógicos por setor e analisamos seu comportamento por meio de depuração.
É justo dizer que o LLM realizou a maior parte do trabalho, mas foi necessária uma supervisão rigorosa por parte de um pesquisador experiente. Os LLMs são uma ferramenta para auxiliar os seres humanos, desde que a assistência seja prestada corretamente.
O modelo pode ocasionalmente desviar-se para direções improdutivas, e a orientação humana era essencial para mantê-lo no caminho certo. Dito isto, os resultados falam por si: O LLM identificou corretamente o código vulnerável, rastreou com precisão o fluxo de chamadas e explicou como a atribuição incorreta de v27 levou ao estouro em CcCopyRead().
Caso nº 3: Uma agulha no palheiro
Há casos em que é necessário ter cuidado com os resultados do LLM. As alucinações não são o único risco das LLMs; isso é reiterado repetidamente nas várias interfaces das LLMs (por exemplo, “O ChatGPT pode cometer erros. Verifique informações importantes.")
A mesma precaução se aplica aqui, embora o sistema tente validar suas entradas e saídas e examinar vários caminhos para identificar a causa raiz. Há momentos em que isso é quase impossível, pois as condições são muito amplas e ambíguas.
Vamos pegar o CVE-2025-29974 da atualização KB5058411 de maio. A página de informações do MSRC sobre a vulnerabilidade afirma que “o subfluxo inteiro (wrap ou wraparound) no kernel do Windows permite que um invasor não autorizado divulgue informações em uma rede adjacente”, o que pode ser um pouco obscuro.
Em seguida, vemos que a página do MSRC menciona que o invasor deve estar próximo; ou seja, o invasor deve estar dentro do alcance para receber transmissões de rádio. Está claramente se referindo à exfiltração de informações por meio de lacunas de segurança. No entanto, o que não está claro é como, ou através de qual hardware. Essa falta de contexto reduz as chances de se obter um relatório válido, se é que há alguma.
Em relação ao CVE-2025-29974, executamos nossa ferramenta e recebemos um relatório sobre duas funções não identificadas: sub_1408E6D3C e sub_1408FAD58. Para facilitar, vamos nos referir a eles como primary() e secondary(). A Figura 13 é uma visualização BinDiff dessas funções, e é fácil perceber que elas são bem diferentes... diferentes demais, na minha opinião.
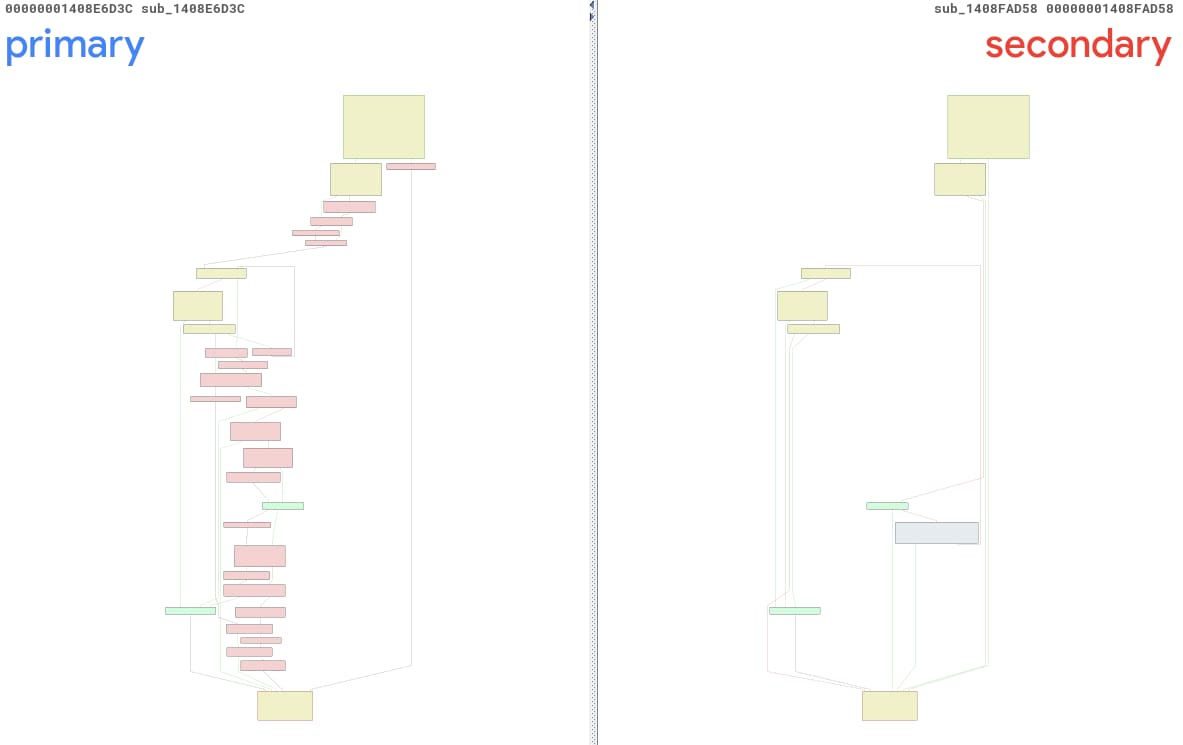 Fig. 13: Visualização do BinDiff das alterações criada automaticamente usando o PatchDiff-AI
Fig. 13: Visualização do BinDiff das alterações criada automaticamente usando o PatchDiff-AI
Após uma análise mais detalhada, podemos identificar a função primary correta como sub_1408E7738, um método completamente diferente, localizado em um endereço diferente. A principal razão para essa confusão é o fato de que o ntoskrnl.exe foi altamente modificado por meio dessa atualização. Foram modificadas 3.791 funções, o que fez com que a probabilidade de encontrar os pares antes e depois corretos diminuísse drasticamente.
O nível de confiança fornecido juntamente com o relatório para este caso foi de 0,2, indicando uma confiança de 20% de que o relatório localizou a vulnerabilidade correta. Esse nível de confiança, juntamente com o elevado número de modificações nos blocos de código, corresponde aos resultados insatisfatórios.
Caso nº 4: Muito vulnerável
Há casos em que o componente apresenta várias vulnerabilidades que são corrigidas pela atualização. Isso não é incomum, já que uma única falha lógica pode conter uma cadeia de vulnerabilidades com diferentes classes.
Se analisarmos a atualização KB5055523 (abril de 2025), podemos encontrar um conjunto de bugs denominados CVE-2025-24058, CVE-2025-24060, CVE-2025-24062, CVE-2025-24073 e CVE-2025-24074 (Figura 14). Todos eles estão relacionados ao gerenciador de janelas da área de trabalho (DWM) e são resultado do “CWE-20: Validação inadequada de entradas”, o que as torna indistintas e ambíguas para o modelo.
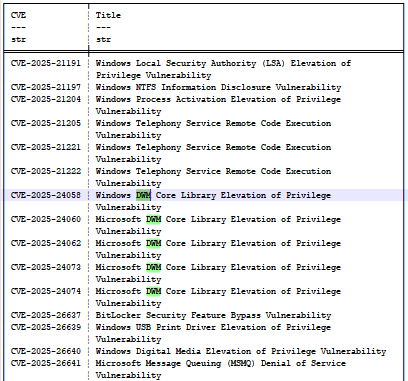 Fig. 14: Lista parcial dos bugs da atualização de abril de 2025
Fig. 14: Lista parcial dos bugs da atualização de abril de 2025
O uso de LLMs traz vantagens e desvantagens. O ponto em comum entre todos eles é o fator custo. O LLM tentará concluir a tarefa em uma única iteração, mesmo que o contexto necessário não esteja alinhado. Para obter resultados mais precisos, devemos avaliar os resultados por meio de heurística e refinar o contexto para que ele possa criar uma mutação melhor.
Utilizamos os relatórios dos erros da atualização de abril de 2025 para avaliar o resultado desse caso de uso. Ao comparar a causa raiz e as informações adicionais, conseguimos entender como as múltiplas vulnerabilidades podem afetar o LLM por meio de sua análise (Tabela).
CVE | Função(ões) defeituosa(s) primária(s) | Classe de bugs | Causa raiz |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | Corrupção de memória baseada em heap causada por validação inadequada de entrada / excesso de inteiros durante o crescimento dinâmico da matriz (CWE-20, leva a CWE-787). | O mesmo wrap inteiro PreSubgraph aciona o estouro do buffer de informações de oclusão |
CVE-2025-24073 | COcclusionContext::PreSubgraph | Excesso de buffer baseado em pilha/excesso de inteiro devido a uso inadequado de validação de entrada (CWE-20, leva à corrupção da memória) | O mesmo wrap inteiro PreSubgraph aciona o estouro do buffer de informações de oclusão |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | Validação inadequada de entrada/limites, levando à gravação fora dos limites da pilha | O mesmo wrap inteiro PreSubgraph aciona o excesso de buffer de informações de oclusão e outro excesso |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | Uso após liberação/Confusão de tipos resultante da passagem de um objeto liberado ponteiro como o ponteiro this implícito (CWE-416, CWE-843) | Ponteiro CD3DDevice liberado reutilizado como CDeviceManager este |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | Estouro de buffer baseado em pilha decorrente da validação inadequada da entrada de comprimentos de lista fornecidos pelo chamador (CWE-20, leva a CWE-122) | Estouro de pilha usando CollectOverlayCandidates |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | Truncagem de ponteiro/validação inadequada de entrada levando ao uso após livre/elevação de privilégios (CWE-20, relacionado com CWE-704) | Argumentos ampliados para __int64; adicionado IsOverlayCandidateCollectionEnabled() |
Várias vulnerabilidades e sua RCA determinada por meio do LLM
A tabela é apenas um reflexo do conteúdo dos relatórios. A avaliação dos bugs da atualização de abril de 2025 revela a duplicação dos CVE-2025-24074, CVE-2025-24073 e CVE-2025-24060. Todos os três se referem às mesmas funções, com pequenas alterações ou acréscimos.
CVE-2025-24058 (dwmcore.dll) parece se sobrepor à consideração do CVE-2025-24060 sobre ComputeOverlayConfiguration. No entanto, CVE-2025-24058 (dwmcorei.dll) e CVE-2025-24062 parecem abordar causas fundamentais totalmente diferentes.
Como o LLM não é um sistema determinístico, a saída pode variar mesmo com uma entrada idêntica. Podemos observar como mudanças no contexto de entrada, por menores que sejam, podem afetar a saída do LLM e resultar em dois relatórios diferentes.
A etiqueta de preço
O PatchDiff-AI baseia-se em uma arquitetura multiagente supervisionada, com diferentes modelos LLM, para reduzir custos e manter alta precisão. A composição dos custos da geração de um relatório utilizando modelos OpenAI resulta em um custo máximo de US$1.43.
Na prática, geramos 131 relatórios a partir das atualizações de março, abril e maio, filtrados apenas para Windows 11 24H2 x64. O custo médio foi de aproximadamente US$0.14 por relatório. Quando se considera quantas vulnerabilidades são combatidas diariamente (se não a cada hora), esses custos podem ser significativos quando escalonados.
Quando recursos totalmente autônomos são ativados, como refinamento estendido nos internos do Windows e agentes de pesquisa de vulnerabilidades, o cálculo do preço pode ser limitado; no entanto, ele não pode ter um valor médio devido à natureza indeterminada do sistema.
Conclusão
O futuro do uso da IA, e especificamente dos LLMs, no domínio da cibersegurança é promissor. Os LLMs podem facilmente transformar um processo muito complicado, mas metodológico, em um fluxo de trabalho simples e podem ser integrados aos pipelines de várias equipes de segurança.
Nossa pesquisa demonstra que uma RCA totalmente automatizada de vulnerabilidades não só é possível, mas também prática, com precisão significativa e custo razoável.
Ao fragmentar o problema em microtarefas e ajustá-lo a uma arquitetura multiagente especializada que combina raciocínio interno do Windows, fluxos de trabalho de engenharia reversa e análise específica de vulnerabilidades, permitimos que os LLMs superassem suas limitações tradicionais. Essa prática (e a ferramenta complementar PatchDiff-AI) também pode ser generalizada para outros produtos e plataformas.
Com nosso sistema, as equipes de segurança podem criar detecções abrangentes, mitigar vulnerabilidades de forma eficaz e criar testes de penetração e regressão para seus sistemas. Além disso, nosso sistema pode ajudar a encurtar o processo de acionamento de vulnerabilidades conhecidas, permitindo pesquisas adicionais e a descoberta de variantes na base de código compartilhada vulnerável.

Tags


