
エグゼクティブサマリー
この調査では、パッチ適用された脆弱性の根本原因を見つけるために大規模言語モデルを使用する方法を検証しました。
Akamai は、Patch Tuesday の脆弱性の根本原因を自律的に分析し、詳細なレポートを生成する、PatchDiff-AI というマルチエージェントシステムを開発しました。
このような分析は、セキュリティチームがほぼ瞬時に脆弱性を分析するための助けになり、防御目的と攻撃目的のいずれにも役立ちます。
複数の戦略を使用することで、システムを微調整し、完全に自動化されたレポート生成で 80% 以上の成功率を達成(攻撃ベクトル分析やフローのトリガーなど)することができました。
火曜日のパッチ(Patch Tuesday) → 水曜日のエクスプロイト(Exploit Wednesday)
Microsoft の定期的な更新サイクルは、毎月第 2 火曜日である Patch Tuesday に集中しており、CVE とそれに対応する修正の包括的なリストがリリースされます。これらの修正プログラムは、Microsoft スタンドアロンアップデート(MSU)ファイルとして配布されます。MSU ファイルは、コア・システム・ファイルにパッチを適用または置換することでアップデートを適用するパッケージ形式です。
Patch Tuesday の後に起こるのが、「Exploit Wednesday」と呼ばれるものです。これは、Microsoft がパッチを作成した脆弱性を攻撃者が競って解析するために発生します。更新されたバイナリに対してバイナリ差分を実行することで、攻撃者は根本的なセキュリティの問題を迅速に特定し、組織がパッチを広く展開する前にそれらの悪用を試みることが可能になります。
同様に、防御側はしばしば、検知方法と緩和策を作成するため、配布されたパッチを急いで分析し、脆弱性の根本原因を把握します。
パッチ差分解析の現状
今日では、パッチ差分解析は骨の折れる作業です。脆弱なコードの一片を特定するために、研究者は次のことを行う必要があります。
脆弱性が含まれている可能性があるファイルを特定する
バイナリ差分を実行して、変更箇所を特定する
セキュリティ関連の変更を他のルーチンコード更新から分離する
疑わしいパーツを分析し、根本原因を把握する
コールフローを動的に調査し、潜在的なトリガー手段を見つける
パッチ修正の完了を評価する
これらの手順の実行には数週間かかることがあり、毎月同時にリリースされる脆弱性の数が膨大であることから、この問題はさらに深刻化しています。
Akamai では、研究者がパッチを適用した脆弱性を迅速に解析し、その根本原因を把握できるようにする、より良い方法を見つけることに着手しました。
LLM を使用したパッチ差分解析
大規模言語モデル(LLM)は、ユーザー入力とともにトレーニング済みデータに基づいて、合理的で正確な情報を統計的に生成できます。しかし、限られたコンテキストウィンドウ(処理できるデータ量と運用コストに影響を与える)や悪名高いモデルのハルシネーションなど、いくつかの制限があります。
セキュリティ領域の脆弱性評価の分野において、LLM の貢献に関する多くの論文が、長年にわたって発表されてきました。今日、LLM はクローズド・ソース・ソフトウェアの解析に苦戦しているように見えますが、オープンソースと Web の脆弱性に関しては、人間が判読できるコードが存在するという共通点があるため、より高いパフォーマンスを発揮するようです。
OpenAI の Aardvark と Claude Code のセキュリティレビュー機能は、引き続き読み取り可能なソースコードに制限されています。一方、ゼロデイ脆弱性の発見を目指す Google Project Zero の Big Sleep というプロジェクトもあります。どちらのアプローチも、バイナリをクローズドソースとして分析しません。
PatchDiff-AI のご紹介
Akamai の調査は、セキュリティパッチの根本原因分析(RCA)に LLM を使用することで、異なるアプローチを採用しています。検証済みと思われる私たちの理論は、バイナリの「diff」によって提供される追加コンテキストが、複雑で低レベルのコードを理解するという LLM の能力を大幅に強化するというものでした。
このタスクでは、特定のプラットフォームの Microsoft Knowledge Base(KB)更新プログラムの分析を自動化するマルチエージェントシステムを開発しました(図 1)。私たちはこれを、「PatchDiff-AI」と呼ぶことにしました。
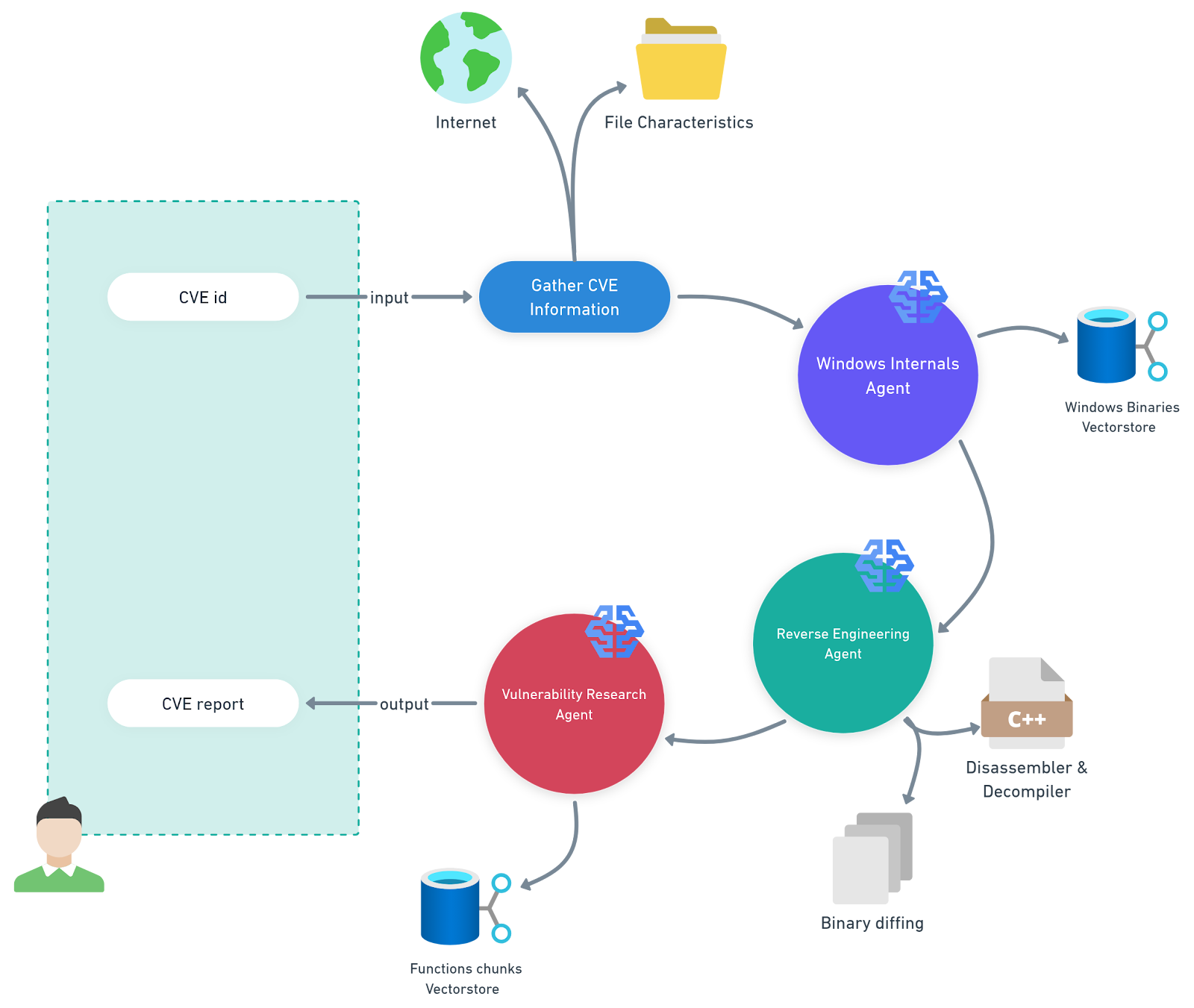 図 1:マルチエージェントシステム「PatchDiff-AI」の図解
図 1:マルチエージェントシステム「PatchDiff-AI」の図解
PatchDiff-AI の定義
Windows 内部エージェント — このエージェントは、Windows バイナリとその機能メタデータを含むベクターストアによってサポートされる検索拡張生成(RAG)パイプラインを使用します。これにより、エージェントは分析の範囲を大幅に絞り込み、最も関連性の高いコンポーネントに集中できるようになります。
リバース・エンジニアリング・エージェント — このエージェントは、関連ファイルの分析や比較(Diffing)のために高度なリバースエンジニアリングツールを使用します。抽出したアーティファクトは、他のエージェントが利用できるように全体のコンテキストに追加されます。
脆弱性調査エージェント — このエージェントは、コンテキスト内に存在するすべてのアーティファクトやその他の情報を収集し、一貫性のあるレポートを生成することで、分析をオーケストレーションします。
手法
コンテキストウィンドウの制限とハルシネーションのため、LLM を可能な限り効果的に使用するための関連性の高い簡潔なコンテキストを提供し、運用コストを削減しながら脆弱なコードコンポーネントを分離するタスクで高い精度を維持することが重要です。
分割して攻略
今回の実装における重要な詳細の 1 つは、分析を焦点を絞った小タスクに分割し、最終的にエージェントとして機能させることでした。
CVE に関する情報を取得してプロファイルを作成する
関連する更新をダウンロードし、ベース・バージョン・ファイルに対してデルタを適用する
Windows 内部 AI エージェントを作成し、脆弱性メタデータを使用して関連ファイルを分離する
次の処理を実行可能なリバースエンジニアリング AI エージェントを作成する。
シンボルを分解して適用し、バイナリ差分解析用にエクスポートする
バイナリを関連付け、変更とコールフローを特定する
脆弱なコードブロックを特定する
可能性のある脆弱性パスを反復処理して相互相関を図り、可能な限り最良の結果を見つける、脆弱性調査 AI エージェントを作成する
この分割の主な利点の 1 つは、タスクタイプごとに特定のモデルを使用できることです。OpenAI o4-mini はファイルメタデータの強化に優れており、OpenAI o3 は脆弱性の疑いのあるコードの究極の詳細分析に使用されました。
タスクに適したモデルを選択することには、2 つのメリットがありました。1 つ目は正確性、2 つ目はコストです。
コンテキストの強化
LLM は、大量の情報を「記憶」するマシンです。プロンプトを使用して LLM を呼び出すと、プロンプトのコンテキスト内で最も関連性の高い情報が提供されるように LLM が調整されます。
パッチを適用した脆弱性に関する情報を LLM に提供することで、より正確な応答を生成し、脆弱なコードを見つける可能性を高めることができます。ただし、脆弱性に関するあいまいな情報が紛れていると、結果の質は低下します。
分析中に脆弱性メタデータでコンテキストを強化することが重要であることが証明されました。コンテキストの強化を実現するために、私たちは LLM に KB の説明、システムファイルの説明、バイナリ差分データを投入しました。このアプローチにより、分析が必要な変更箇所の数を絞り込むことができたため、LLM でのコンテキストの長さと反復の数も絞り込むことができました。
結果
私たちのフレームワークを評価するために、モデルの機能を検査し、以下を正確に特定しました。
CVE に対応する脆弱な実行可能ファイル
実行可能ファイル内の脆弱な関数
脆弱性の根本原因とその正確な説明
これらのパラメーターに基づいて、Windows 11 24H2 の直近 3 回の Patch Tuesday のリリースを分析しました。私たちが開発したツールを実行して自動レポートを生成した後、選択した結果を手動で検査し、最終的なモデル応答の精度を判定しました。
コンテキストを調整し、さまざまなタスクに合わせて幅広いモデルを調整した結果、最終的に次のような結果が得られました。
問題の CVE に対してパッチが適用された正しい実行可能ファイルを 88.6% の確率で特定
確実に脆弱性のある機能を 83.9% の確率で発見
脆弱性の正しい根本原因を 71.4% の確率で特定
静的分析ツールのクラッシュやデルタパッチの適用不能など、コンテキストが不十分なために発生したレポート生成の失敗を除外すると、正しいコードブロックが与えられた場合のモデルの成功率を推定できます。このような場合、コンテキストで正しいコードブロックが与えられている場合、LLM の成功率は約 96% になります(図 2)。
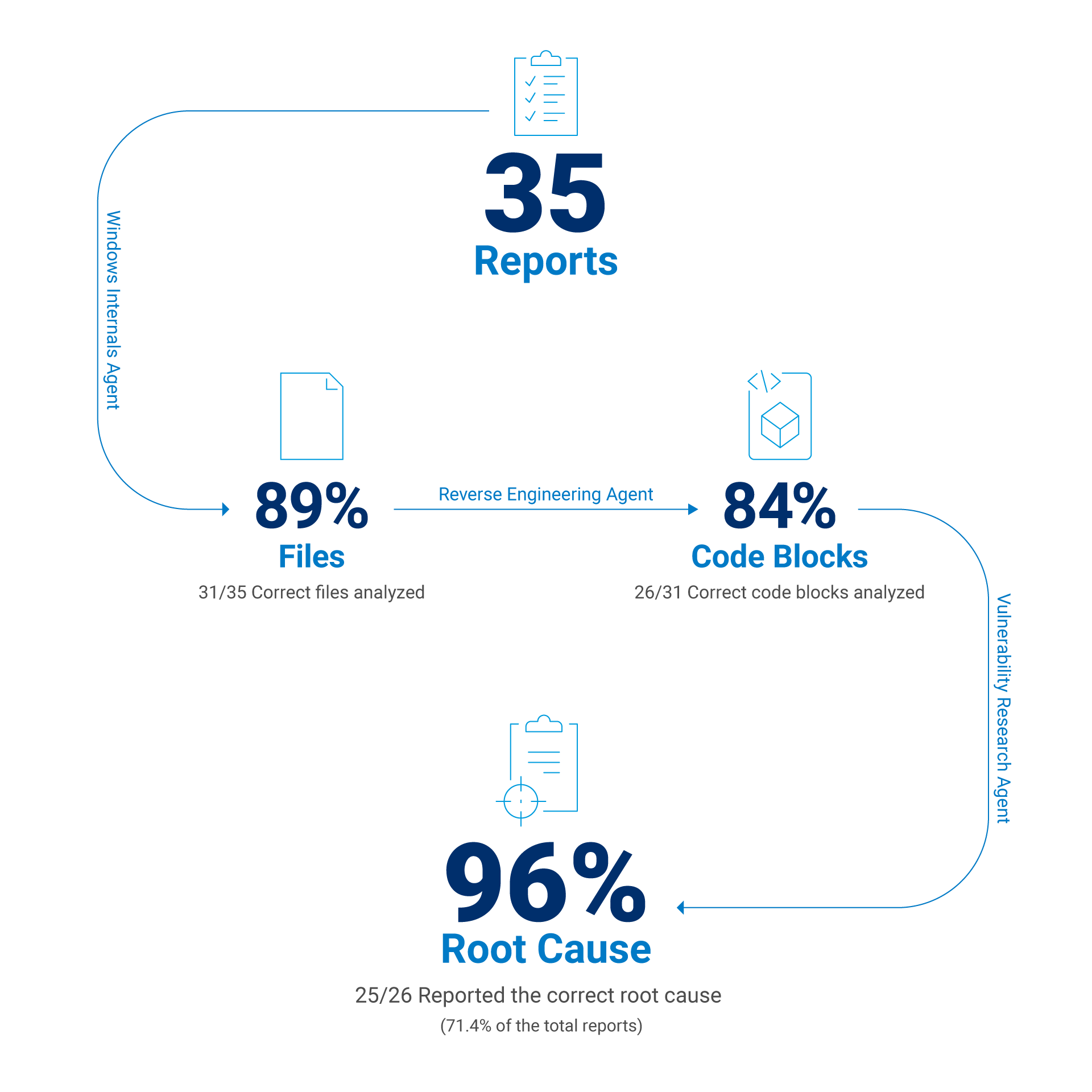 図 2:選択されたCVEに関するレポートの評価結果
図 2:選択されたCVEに関するレポートの評価結果
CVE レポートと、そのコンポーネント。
その結果、いくつかの興味深いユースケースに遭遇しました。そこで、それらを共有し、徹底的に調査したいと思います。すべてのユースケースには、以下のとおり同じレポート構造があります。
レポートを構成する CVE の詳細
RCA(レポートの核心)
パッチの前後のコードスニペット
脆弱性がトリガーされると考えられる方法に関するトップダウン概要
パッチに関する強調された説明
脆弱性を悪用する可能性のある攻撃ベクトル
脆弱性の明確で詳細な影響
さらに、各レポートの最後のセクションでは、パッチの有効性に疑問を呈し、パッチがバイパスされる可能性を確認します。
ケーススタディ
次の 4 つのケーススタディでは、私たちのフレームワークが秀でている点、苦戦している点、完全に失敗している点に焦点を当てた興味深い事例をいくつか紹介します。
ケース 1:マウントとブレーク
Microsoft Security Response Center(MSRC)によると、Akamai が分析した脆弱性の 1 つ、CVE-2025-24991 は、「Windows NTFS の境界外読み取りによって、攻撃者がローカルで情報を開示できてしまう」バグでした。FAQ にはさらに、「攻撃者は、脆弱なシステムのローカルユーザーをだまして、特別に細工された VHD をマウントさせ、脆弱性をトリガーする可能性があります」という情報が付け加えられています。
この脆弱性は明らかに NTFS コンポーネントに関連しており、確実に ntfs.sys の関与を示唆しているといえます。
もう 1 つの手がかりは、脆弱性がマウントされた VHD ファイルによってトリガーされるという事実です。パッチの手動分析は、最善を尽くしても何時間もかかる可能性があります。ところが、PatchDiff-AI ツールを使用することで、わずか数分で終えることができます。このことは、根本原因を特定するための明確なパスがない場合でも、Akamai の開発したツールが手動分析と同等の結果を提示できるという事実によってさらに説得力が高まります。
この場合、システムは KB5053598 アップデートでファイルに加えられた 17 件の最も関連性の高い変更の中に根本原因を見つけたと表示します。レポートの全文は GitHub リポジトリでご覧いただけます。私たちの評価プロセスは以下のとおりです。
まず、このツールは関連するコンポーネント(実際には ntfs.sys)と関連する関数 ReadRestartTable() を出力します。また、ロジックが何をするように設計されているかについての簡単な説明も出力します(図 3)。
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().次に、CWE インデックスに関連付けられた脆弱性クラスを確認します(この場合は CWE-125:Out-of-bounds Read(境界外の読み取り))。LLM がこのレポートを作成したときにどのような脆弱性を探しているかを理解するのに役立つ情報です。
図 4 は、ツールの RCA からの実際の出力です。何が問題であったかを明確に示し、問題を正確に特定します。
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.IDA と BinDiff を使用してこれらの結果を調べると、実際に正しい場所が記載されていることがわかります。また、Microsoft は機能フラグを使用して脆弱性修正プログラムをオプトアウトしていることがわかっているため、予期しない動作が発生した場合に同じやり方で元に戻すことができます(図 5)。
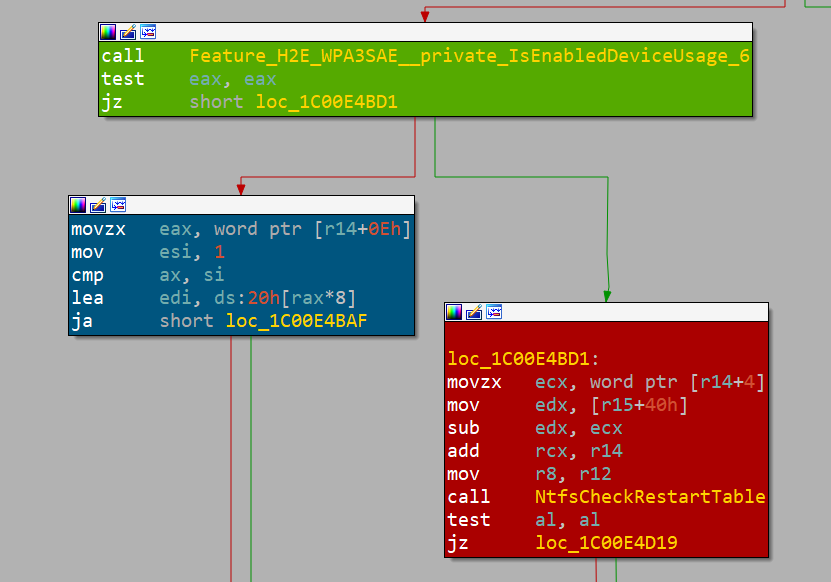 図 5:Microsoft フィーチャーフラグ(緑のブロック)、修正済みパス(青のブロック)、および脆弱なパス(赤のブロック)
図 5:Microsoft フィーチャーフラグ(緑のブロック)、修正済みパス(青のブロック)、および脆弱なパス(赤のブロック)
レポートでは、関数の逆コンパイルされた脆弱な部分のコードスニペットを見つけ、脆弱なコードを確認できます(図 6)。
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```レポートのハイライトの 1 つは、トップダウンのトリガーセクションです。このセクションでは、LLM が、脆弱性をトリガーするために実行する必要がある可能性のある手順を提案します。該当する場合は、実際の悪用の詳細を示します(図 7)。
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.このツールは、フォローアッププロンプトと組み合わせることで、逆コンパイルされたコードをさらに分析し、より多くの情報を明らかにし、最小限の概念実証(PoC)を提案することもできます。
もう 1 つの有用な知見が、攻撃ベクトルセクションにあります。ここでは、脆弱性の悪用を専門性の高い視点から解説するため、脆弱性の範囲と、攻撃者が悪用する必要があるものを把握できます(図 8)。
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.残りのセクションでは、パッチ自体とそのセキュリティ上のシステムへの影響について、より一般的な説明を提供します。ただし、最後のセクションでは、LLM をパッチに挑戦させ、修正プログラム内の別の脆弱性を特定することで迅速に成果が得られるかどうかを確認するよう依頼しました。今回の場合、パッチが完了したことが次のとおり評価されました。「すべてのエラーパスが、範囲外アクセスの可能性が生じる前に上げられるようになりました」
ケース 2:星が並ぶとき
自動生成された IDA データベースと BinDiff 出力に照らしてレポートを評価することは、検知や緩和に重点を置いているチームにとって有益であり、多くの場合十分な情報となります。しかし、私たちのアプローチはさらに先を行き、攻撃的な目的にも役立つことが証明されています。なぜなら、場合によっては、システムが分析の範囲を超え、実際に有効な悪用方法を編み出すことができるからです。
たとえば、2025 年 6 月の更新プログラム(KB5060842)でパッチが適用された脆弱性 CVE-2025-32713 の説明は、次のとおりでした。「Windows Common Log File System Driver のヒープベースのバッファオーバーフローにより、認証を受けた攻撃者がローカルで権限を昇格させることができます。」私たちのツールは、約 2 分で、この問題を CClfsLogFcbPhysical::ReadLogBlock() にトレースバックするレポートを生成しました。
この時点で、悪用の課題に対処する方法は 2 つあります。
関数とその呼び出し元を手動でユーザーモード呼び出しに戻す
LLM に任せて、自律的に PoC を作成してもらう
しかし、多くの場合、3 つ目の選択肢があります。それが、ハイブリッドのアプローチです。間接的なコードフローを決定し、バイナリの論理部分間の複雑な接続を解決しながら、リバースエンジニアリングの負荷の高い作業を LLM に依頼します。これにより、LLM はより良い結果を出すことができます。
この手法を使用することで、わずか数時間でブルースクリーン(BSOD)攻撃を実現できました(図 9)。
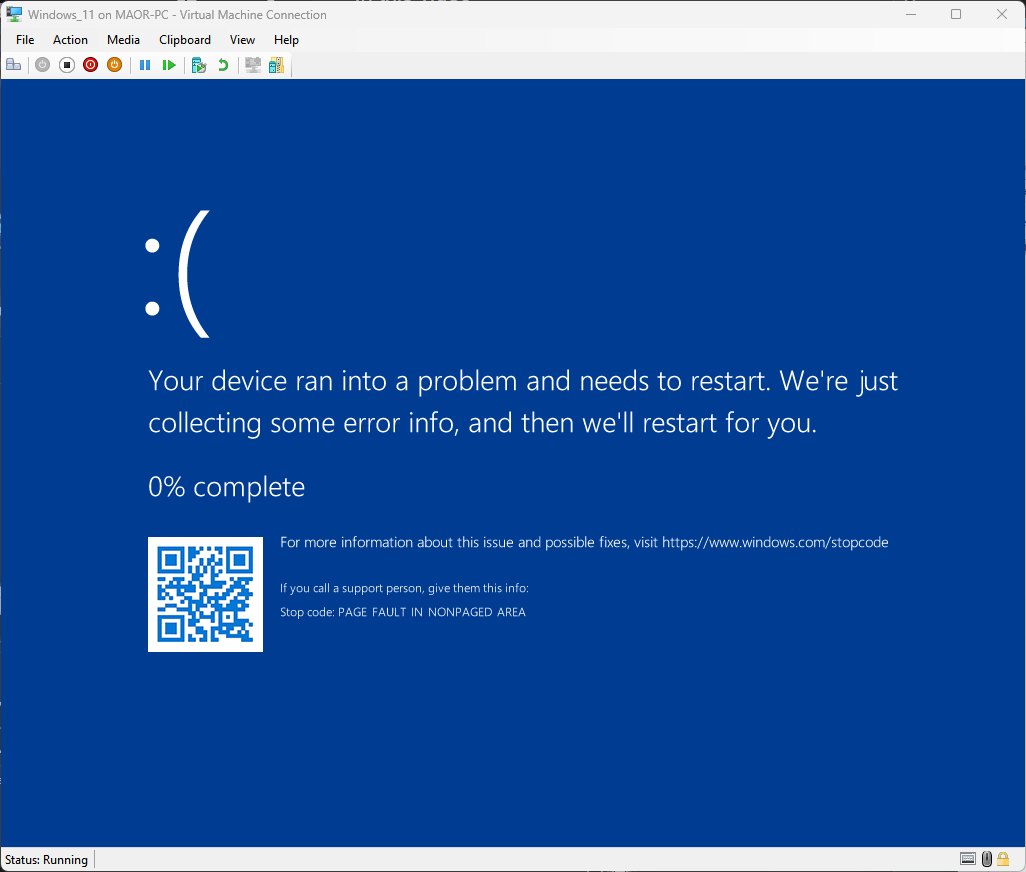 図 9:CVE-2025-32713のPoC実行中に発生したBSOD
図 9:CVE-2025-32713のPoC実行中に発生したBSOD
脆弱性トリガーのフローを理解する過程は、「RCA」セクションで説明されているように、提案された脆弱性コードを評価することから始まりました。私たちは、パッチがセキュリティの欠陥を修正しようとしていることに気付いた後、入出力制御(IOCTL)0x80076832 までのコールフローを分析しました。
ユーザーモードの受け手を探す中で、clfsw32.dll がこの IOCTL を呼び出すための直接パスを持つ関数 ReadLogRecord をエクスポートする、2 つの候補があることを発見しました(図 10)。
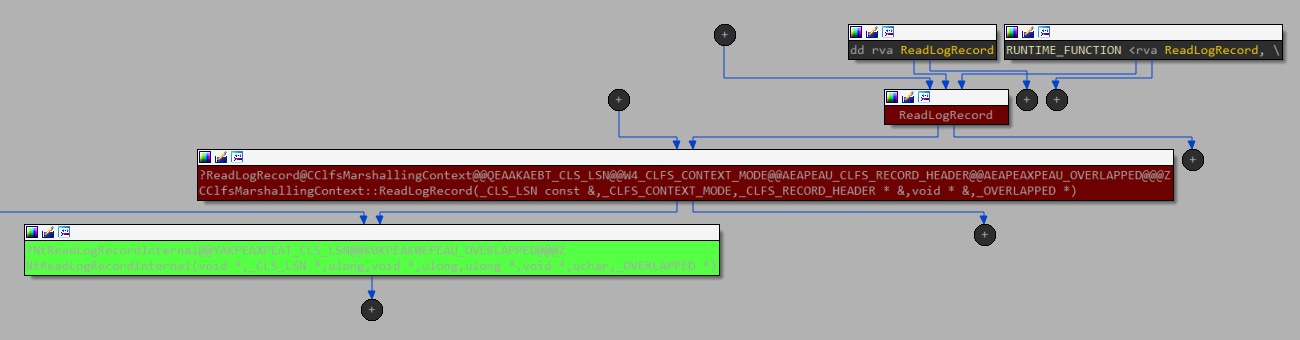 図 10:ユーザーモードからエクスポートされたメソッドから始まり、(IOCTL呼び出しを使用して)カーネルドライバに至るまでのコールフローグラフ
図 10:ユーザーモードからエクスポートされたメソッドから始まり、(IOCTL呼び出しを使用して)カーネルドライバに至るまでのコールフローグラフ
すべてのステップで、LLM がこの知識の一部でトレーニングされていることを考慮して、ロジックの反転と分析をどのように支援できるかを評価しました。図 11 は、提供するバッファのサイズである v4 の条件要件をどのように解決できるかを示しています。
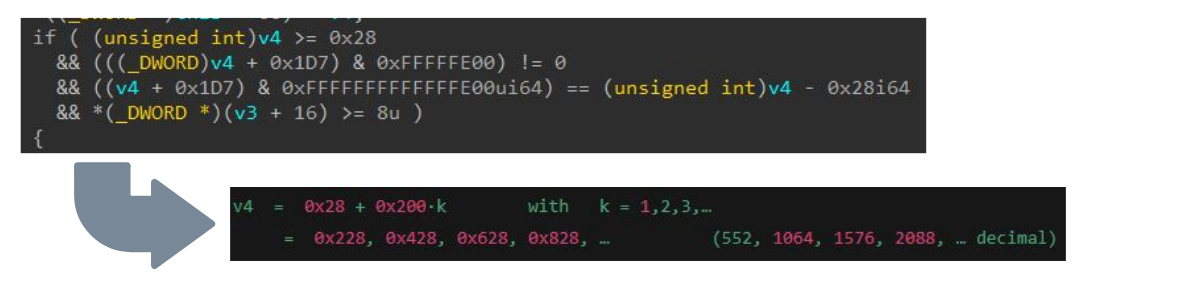 図 11:LLMを使用したバリデーションチェックの分析
図 11:LLMを使用したバリデーションチェックの分析
LLM が発見できる優れた観察結果をいくつか見てきましたが、結果が誤解を招くようなケースもいくつかありました。CVE-2025-32713 に戻りますが、その応答の 1 つに、図 12 に示す引用が含まれていました。
“crafts the log header so that the page size (v48) exceeds the supplied buffer”この応答には非常に惑わされ、最終的に脆弱なコードをトリガーする方法を把握することから遠ざかってしまいました。実際、私たちはまったく無関係な研究パスにたどり着きました(私たちが操作しようとしたのは、すでに緩和策が導入されている .blf ファイル構造だったのです)。その後、セクターごとに異なる物理バイトと論理バイトを持つ仮想ディスクを作成し、デバッグを通じてそのふるまいを分析しました。
LLM が作業の大部分を処理したと言っても過言ではありませんが、経験豊富な研究者による綿密な監督が必要でした。LLM は、支援が正しく提供されている限り、人間を支援するツールになります。
モデルは時々非生産的な方向に向かって進むことがあるため、あるべき方向に進み続けるためには人間のガイダンスが不可欠でした。とはいえ、結果がそれを物語っています。LLM は脆弱なコードを正しく特定し、コールフローを正確に追跡し、v27 の誤った割り当てが CcCopyRead() でどのようにオーバーフローを引き起こしたかを説明しました。
ケース 3:発見は極めて難しい
LLM 出力を慎重に取得しなければならない場合があります。LLM のリスクはハルシネーションだけではありません。このことは、さまざまな LLM インターフェースで繰り返し言及されています(例:「ChatGPT は誤った回答をする可能性があります。重要な情報は確認してください。」)
ここでも同じことに注意する必要がありますが、システムは入出力を検証し、複数のパスを調べて根本原因を特定しようとします。条件が広すぎてあいまいなため、ほとんど不可能な場合があります。
5 月の KB5058411 アップデートから CVE-2025-29974 を取り上げます。脆弱性に関する MSRC 情報ページには、「Windows カーネルの整数アンダーフロー(ラップまたはラップアラウンド)により、攻撃者が認証なしで隣接するネットワークを介して情報を開示することができてしまいます」と記載されていますが、これはややあいまいかもしれません。
次に、MSRC ページで、攻撃者が近くにいる必要があることが示されています。つまり、攻撃者は無線送信を受信できる範囲内に潜んでいる必要があるということです。これは明らかに、情報のエアギャップ流出について説明しています。しかし、どのようにして流出するのか、またどのようなハードウェアを使用するかが明確ではありません。このようにコンテキストが欠落していると、有効なレポートを取得できる可能性が低くなります。
CVE-2025-29974 に関して、ツールを実行し、SUB_1408E6D3C と SUB_1408FAD58 という 2 つの名前のない関数に関するレポートを作成しました。便宜上、以降はこれらを「primary()」と「secondary()」と呼ぶことにします。図 13 は、これらの関数の BinDiff ビューです。これらの関数がかなり異なることがよくわかります。私に言わせれば、あまりにも違いすぎるといったところでしょうか。
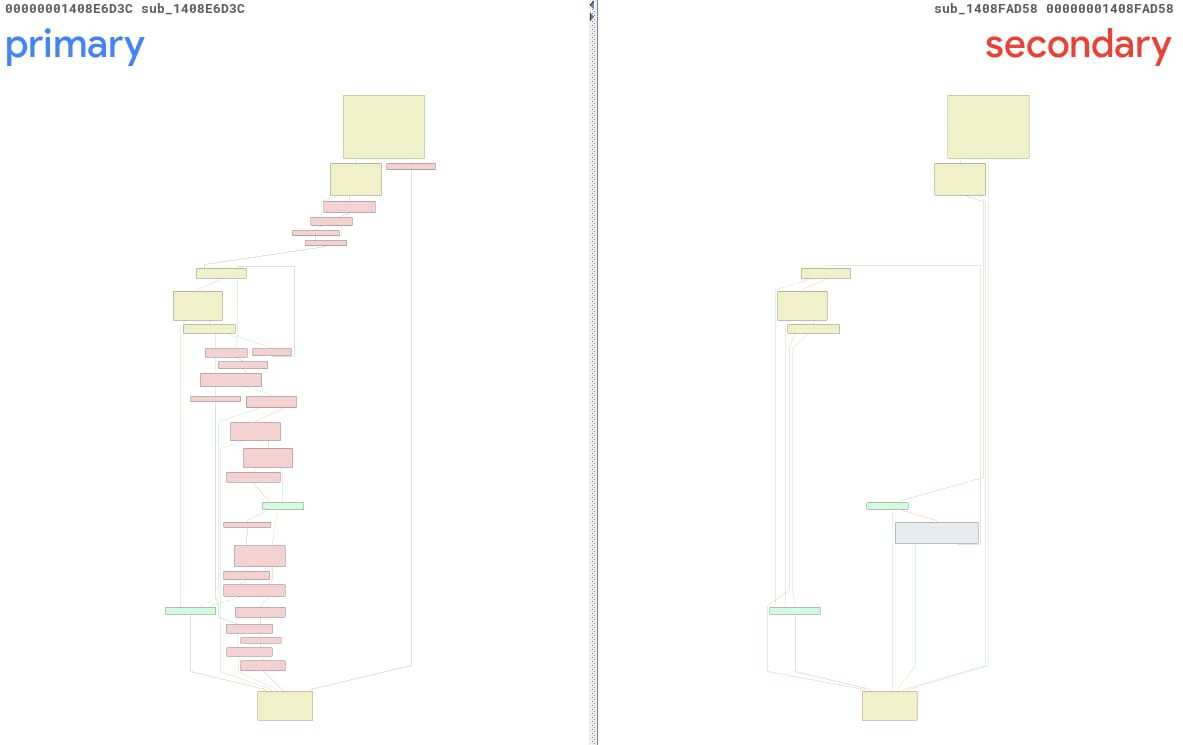 図 13:PatchDiff-AI を使用して自動生成された変更箇所の BinDiff ビュー
図 13:PatchDiff-AI を使用して自動生成された変更箇所の BinDiff ビュー
詳しく調べてみると、sub_1408E7738 というまったく異なる方法で、別の住所にある正しい primary 機能を特定できました。このような混乱が起こった主な理由は、ntoskrnl.exe がこのアップデートによって大幅に修正されたという事実です。このアップデートにより 3,791 個の関数が修正され、直前と直後のペアを発見できる確率がいちじるしく低下しました。
このケースのレポートとともに提示された信頼レベルは 0.2 でした。これは、レポートが正しい脆弱性を見つけたという信頼度が 20% であることを示しています。この信頼レベルは、コードブロックの変更数が多いと、それに応じて悪い結果が提示されます。
ケース 4:あまりにも脆弱
コンポーネントに複数の脆弱性があり、アップデートによって解決される場合があります。単一のロジックの欠陥には異なるクラスの脆弱性の連鎖が含まれている可能性があるため、これは珍しいことではありません。
KB5055523(2025 年 4 月)のアップデートを見ると、CVE-2025-24058、CVE-2025-24060、CVE-2025-24062、CVE-2025-24073、CVE-2025-24074 と呼ばれる一連のバグが確認できます(図 14)。これらはすべてデスクトップ・ウィンドウ・マネージャー(DWM)に関連しており、すべて「CWE-20:Improper Input Validation(不適切な入力検証)」というメッセージが表示されます。これにより、モデルが不明瞭かつあいまいになります。
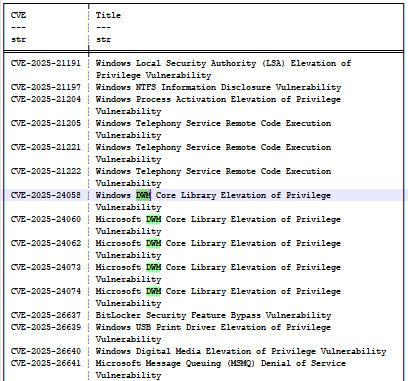 図 14:2025年4月の更新プログラムにおけるバグの部分的なリスト
図 14:2025年4月の更新プログラムにおけるバグの部分的なリスト
LLM の使用にはトレードオフが伴います。それらすべてに共通する基盤は、コスト要因です。LLM は、必要なコンテキストが一致していない場合でも、1 回の反復でタスクを完了しようとします。より正確な結果を得るには、ヒューリスティックによって結果を評価し、コンテキストを改良して、より良い変異を生み出す必要があります。
私たちは、このようなユースケースの結果を評価するために、2025 年 4 月のアップデートバグのレポートを使用しました。根本原因と追加情報を比較することで、複数の脆弱性が LLM にどのような影響を与えるかを分析することができました(表)。
CVE | 欠陥のある主な機能 | バグの分類 | 根本原因 |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | 不適切な入力検証によるヒープベースのメモリ破損/ 動的アレイの増加中に整数オーバーフローが発生(CWE-20。CWE-787 につながる)。 | 同一の PreSubgraph 整数ラップが occlusion-info バッファオーバーフローをトリガーする |
CVE-2025-24073 | COcclusionContext::PreSubgraph | 不適切な入力検証によるヒープベースのバッファオーバーフロー/整数オーバーフロー (CWE-20、メモリ破損につながる) | 同一の PreSubgraph 整数ラップが occlusion-info バッファオーバーフローをトリガーする |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | 不適切な入力/境界の検証により、境界外ヒープの書き込みにつながる | 同一の PreSubgraph 整数ラップが occlusion-info バッファオーバーフローと別のオーバーフローをトリガーする |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | 解放されたオブジェクトポインターを 暗黙的な this-pointer として渡すことによる Use-after-free/Type-confusion という結果(CWE-416、CWE-843) | 解放された CD3DDDevice ポインターが CDeviceManager として再利用される |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | 発信者が提供するリストの長さの不適切な入力検証に起因する、ヒープベースのバッファオーバーフロー (CWE-20、CWE-122 につながる) | CollectOverlayCandidates を使用したヒープオーバーフロー |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | ポインターの切り捨て/不適切な入力検証により、Use-After- Free/権限の昇格につながる(CWE-20、CWE-704 に関連) | 引数が __int64 に拡張され、IsOverlayCandidateCollectionEnabled() が追加された |
LLM によって特定された複数の脆弱性とその RCA
この表は、レポートの内容を反映したものにすぎません。2025 年 4 月のアップデートのバグを評価すると、CVE-2025-24074、CVE-2025-24073、CVE-2025-24060 の重複が明らかになります。3 つの機能はすべて同じで、若干の変更や追加が行われています。
CVE-2025-24058(dwmcore.dll)は、ComputeOverlayConfiguration に関する CVE-2025-24060 の考慮事項と重複しているようです。ただし、CVE-2025-24058(dwmcorei.dll)と CVE-2025-24062 は、まったく異なる根本原因が示されています。
LLM は決定論的システムではないため、同じ入力でも出力が変化する可能性があります。入力コンテキストの変更がどれほどわずかであっても、LLM の出力にどのように影響し、2 つの異なるレポートが生成されるかを観察できます。
価格の表示
PatchDiff-AI は、さまざまな LLM モデルを備えた監視付きマルチエージェントアーキテクチャを基盤としているため、高い精度を維持しながらコストを削減します。OpenAI モデルを使用して 1 つのレポートを生成するコスト内訳では、最大コストは 1.43 米ドルです。
実際には、3 月、4 月、5 月のアップデートから 131 件のレポートを生成し、Windows 11 24H2 x64 のみをフィルタリングしました。レポート 1 件あたりの平均コストは約 0.14 米ドルでした。毎日(1 時間ごとではなくても)何件の脆弱性が対処されているかを考慮すると、これらのコストは規模を拡大すると高額になる可能性があります。
Windows 内部や脆弱性研究エージェントの拡張された改良など、完全に自律的な機能が有効になっている場合、価格の計算に上限を設けることができますが、このシステムは不確定な性質を持っているため、平均値を設定することができません。
結論
サイバーセキュリティ分野で AI、特に LLM を使用する未来は明るいです。LLM を使用すれば、非常に複雑ながら方法論的なプロセスをシンプルなワークフローに簡単に変換でき、さまざまなセキュリティチームのパイプラインに統合できます。
Akamai の調査では、脆弱性の完全に自動化された RCA が可能であるだけでなく、実用可能であること、しかも、それが有意義な精度と妥当なコストで実現することが示されています。
問題をマイクロタスクに分割し、Windows 内部の推論、リバース・エンジニアリング・ワークフロー、脆弱性固有の分析を組み合わせた専用のマルチエージェントアーキテクチャに調整することで、LLM が従来の制限を克服できるようにしました。この手法(および PatchDiff-AI コンパニオンツール)は、一般化して、他の製品やプラットフォームにも適応できます。
Akamai のシステムを使用することで、セキュリティチームは包括的な検知方法を作成し、脆弱性を効果的に緩和し、システムのペネトレーションテストとリグレッションテストを作成できます。さらに、当社のシステムは既知の脆弱性をトリガーするプロセスを短縮し、脆弱な共有コードベースでさらなる調査と亜種の発見を可能にします。

タグ

