
内容提要
在此研究中,我们研究了如何使用大语言模型来寻找产生已修补漏洞的根本原因。
我们开发了一个名为 PatchDiff-AI 的多智能体系统,该系统可自主分析产生 Patch Tuesday 漏洞的根本原因,并生成详细的报告。
此类分析可以帮助安全团队以近乎实时的方式分析漏洞,能够满足攻防两端的不同需求。
通过使用多种策略,我们能够对系统进行微调,使其在全自动报告生成(包括攻击媒介分析和触发流程)方面实现了超过 80% 的成功率。
Patch Tuesday → Exploit Wednesday
Microsoft 的定期更新周期集中在 Patch Tuesday(即,每月的第二个星期二),届时该公司会发布一个包含 CVE 及其相应修复程序的完整列表。这些修复程序以 Microsoft 独立更新 (MSU) 文件的形式发布,这是一种通过修补或替换核心系统文件来应用更新的封装格式。
在 Patch Tuesday 之后,所谓的“Exploit Wednesday”往往紧随其后,因为攻击者会争相发掘 Microsoft 为其创建补丁的漏洞。通过对更新后的二进制文件进行二进制比对,攻击者能够迅速地准确发现底层的安全问题,并试图在企业广泛部署补丁之前利用这些漏洞。
同样,防御者通常也会争先恐后地分析这些补丁,以了解产生漏洞的根本原因,从而创建检测和抵御措施。
补丁比对的现状
现在,补丁比对是一个繁琐的过程。要成功识别有漏洞的一段代码,研究人员需要:
识别疑似包含漏洞的文件
进行二进制比对以识别更改
从其他的常规代码更新中分离出与安全相关的更改
分析可疑部分并了解根本原因
动态检查调用流,以找到潜在的触发路径
评估补丁修复是否完整
这些步骤有时可能需要数周才能完成,而每个月同时发布的海量漏洞进一步加剧了这一问题。
为此,我们决心寻找一种更好的方法,让研究人员能够快速分析已修补的漏洞并了解其根本原因。
使用 LLM 进行补丁对比分析
大语言模型 (LLM) 能够基于训练数据以及用户输入,从统计学角度生成合理且准确的信息。但也存在一些局限性,包括有限的上下文窗口(这会影响它可以处理的数据量及其运营成本)以及饱受诟病的模型幻觉问题。
多年来,已有大量论文探讨了 LLM 对安全行业漏洞评估领域作出的贡献。如今,LLM 在分析闭源软件时似乎颇为吃力,而在处理开源软件和 Web 漏洞时表现却好得多;这两者的共同点在于都拥有人类可读的代码。
OpenAI 的 Aardvark 和 Claude Code 安全审查工具仍然局限于可读的源代码。另一方面,Google Project Zero 的 Big Sleep 旨在发现零日漏洞。这两种方法都无法对闭源二进制文件进行分析。
PatchDiff-AI 简介
我们的研究另辟蹊径,利用 LLM 对安全补丁进行根本原因分析 (RCA)。我们的理论是,二进制“比对”提供的额外上下文能够显著增强 LLM 理解复杂底层代码的能力,而这一理论似乎已得到验证。
针对这一任务,我们开发了一个多智能体系统,用于自动分析特定平台的 Microsoft 知识库 (KB) 更新(图 1)。我们称之为 PatchDiff-AI。
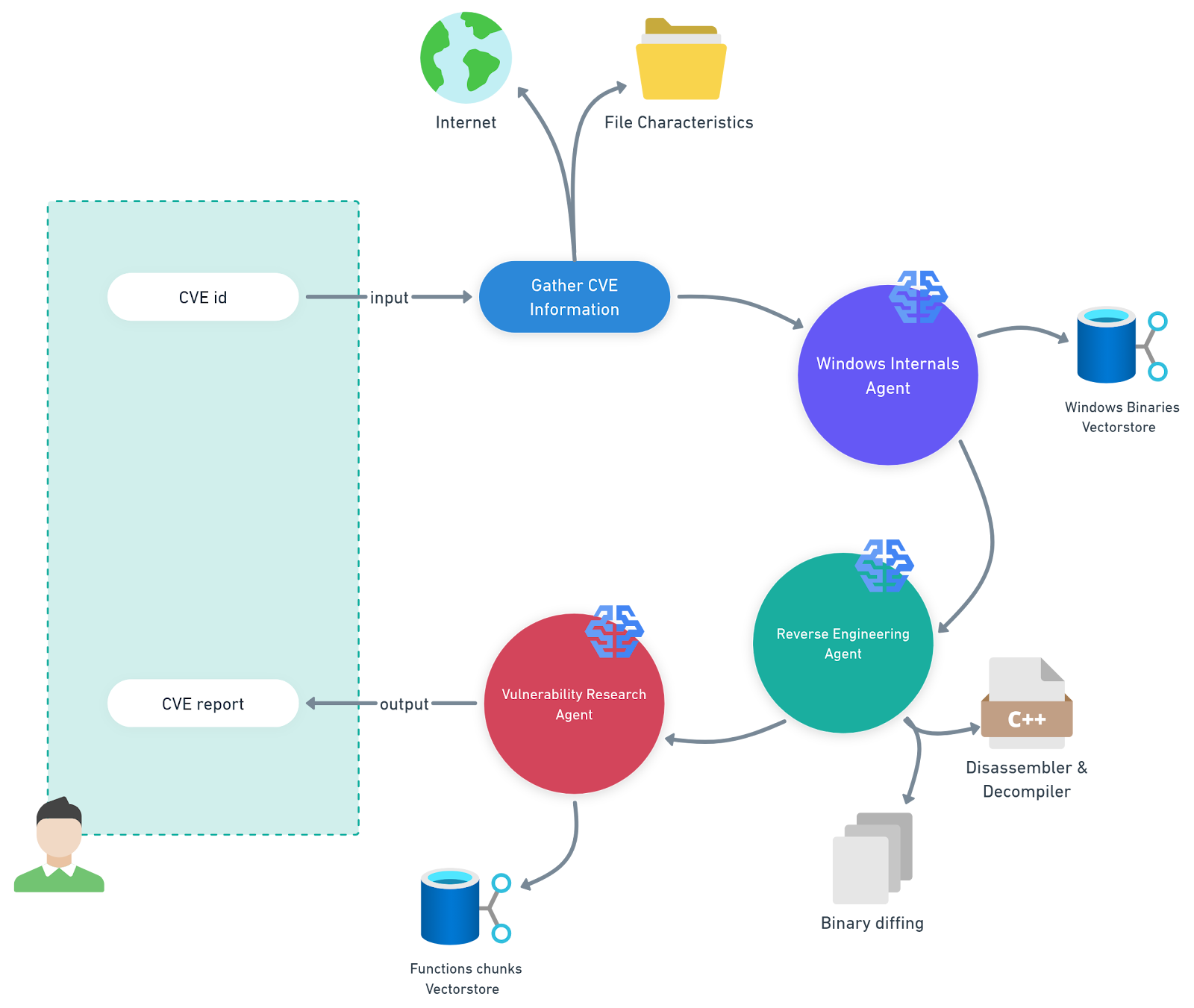 图 1:我们的多智能体系统 PatchDiff-AI 示意图
图 1:我们的多智能体系统 PatchDiff-AI 示意图
PatchDiff-AI 定义
Windows 内部机制智能体:此智能体使用检索增强生成 (RAG) 管道,由包含 Windows 二进制文件及其功能元数据的向量存储库提供支持。这使智能体能够显著缩小分析范围,并专注于最相关的组件。
逆向工程智能体:此智能体使用先进的逆向工程工具来分析和比对相关文件。它会将分析产物追加到整体上下文中,供其他智能体使用。
漏洞研究智能体:此智能体负责统筹安排分析工作,它会收集上下文中存在的所有分析产物和其他信息并生成一份一致的报告。
方法
由于上下文窗口限制和幻觉问题,为确保尽可能有效地利用 LLM,必须提供相关且精简的上下文。这有助于在降低运营成本的同时,确保隔离有漏洞的代码组件的高准确性。
化整为零,各个击破
在我们的实施过程中,一项至关重要的细节是将分析工作拆分为若干个更小且专注的任务,这些任务最终都以智能体的形式运作:
检索有关 CVE 的信息以生成漏洞档案
下载相关更新,并针对基本版本文件应用增量更新
创建一个 Windows 内部机制 AI 智能体,使用漏洞元数据来隔离相关文件
创建一个逆向工程 AI 智能体,使其能够:
执行反汇编并应用符号,然后导出结果进行二进制比对
关联二进制文件并识别更改和调用流
准确找出有漏洞的代码块
创建一个漏洞研究 AI 智能体,通过遍历可能的漏洞路径进行交叉关联分析并找到最佳结果
这种分工的主要优势之一在于,我们可以针对每种任务类型使用特定模型;OpenAI o4-mini 擅长丰富文件元数据,而 OpenAI o3 用于对疑似有漏洞的代码进行最终的深度分析。
为任务选择合适的模型带来了双重收益:首先是准确率,其次是成本。
丰富上下文
LLM 是能够“记住”大量信息的机器。通过提示词调用 LLM 将对其进行调整,使其在提示词的语境下提供最相关的信息。
我们向 LLM 提供的关于已修复漏洞的每一条信息都有助于生成更精准的回复,并提升找到有漏洞代码的成功率。但是,如果关于漏洞信息含糊不清,则会导致分析结果不佳,甚至可能毫无结果。
在分析过程中,使用漏洞元数据来丰富上下文被证明至关重要。为了丰富上下文,我们为 LLM 提供了 KB 描述、系统文件描述和二进制比对数据。这种方法使我们能够减少需要分析的更改数量,从而缩小上下文长度和与 LLM 的迭代次数。
结果
为了评估我们的框架,我们考察了模型准确定位以下内容的能力:
与 CVE 对应的有漏洞的可执行文件
可执行文件中有漏洞的函数
产生漏洞的根本原因,并正确给出解释
根据这些参数,我们分析了 Windows 11 24H2 最新的三个 Patch Tuesday 版本。在运行我们的工具并生成自动化报告后,我们手动检查了选定的结果,并确定了最终模型回复的准确性。
在优化上下文并针对不同任务调整各种模型后,我们最终实现了以下结果:
识别出已针对目标 CVE 进行修补的可执行文件的准确率为 88.6%
找到有漏洞函数的准确率为 83.9%
找出产生漏洞的根本原因的准确率为 71.4%
如果我们排除因上下文不足而导致的报告生成失败(例如,静态分析工具崩溃或无法应用增量补丁),则可以估算出模型在获得正确代码块时的成功率。在这种情况下,如果在上下文中提供了正确的代码块,则 LLM 的成功率约为 96%(图 2)。
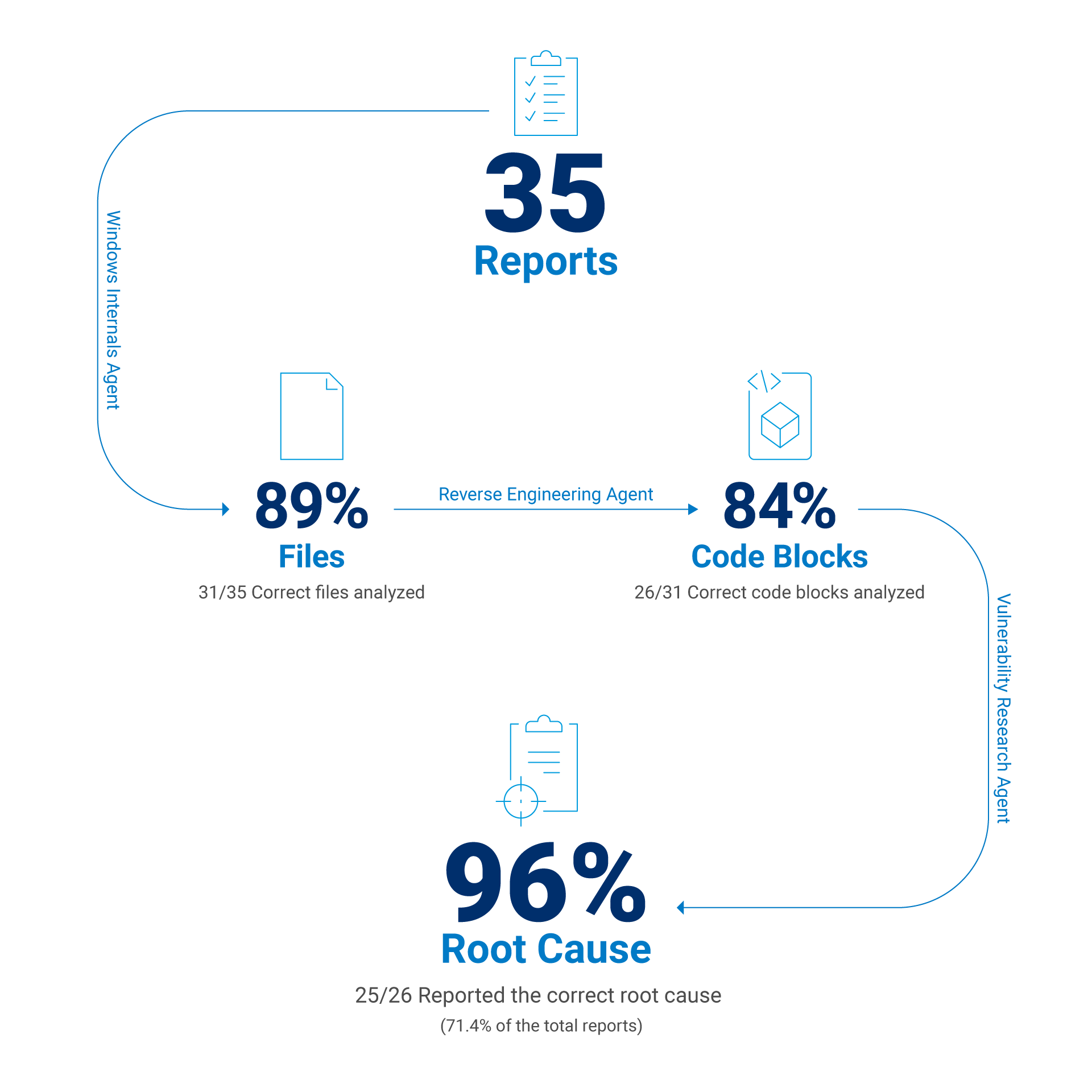 图 2:所选 CVE 报告的评估结果
图 2:所选 CVE 报告的评估结果
CVE 报告及其组成部分
因此,我们遇到了一些有趣的应用场景,希望分享给大家并进行深入研究。每个应用场景都具有相同的报告结构:
构成报告的 CVE 详细信息
RCA——报告的核心
应用补丁前后的代码片段
关于漏洞触发方式的自上而下概述
对补丁的重点说明
可能利用该漏洞的攻击媒介
清晰且详细的漏洞影响
此外,每份报告的最后一节都会尝试质疑该补丁的有效性,并探讨可能的绕过方案。
案例分析
在以下四个案例研究中,我们将探讨几个有意思的案例。这些案例突出了我们的框架在哪些方面表现卓越、在哪些方面存在不足以及在哪些方面会彻底失效。
案例 1:挂载和突破
我们分析的漏洞之一是 CVE-2025-24991。根据 Microsoft 安全响应中心 (MSRC) 的调查,这是一个“Windows NTFS 中的越界读取漏洞,允许获得授权的攻击者在本地泄露信息”。常见问题中提供的另一条信息指出:“攻击者可诱骗有漏洞系统上的本地用户挂载特制的 VHD,从而触发该漏洞”。
目前,可以确定该漏洞与 NTFS 组件相关,这肯定意味着与 ntfs.sys 有关。
另一个线索是,该漏洞是由挂载 VHD 文件触发的。人工分析补丁在最理想的情况下也需要好几个小时,但使用 PatchDiff-AI 工具,只需几分钟即可完成。更值得一提的是,在难以直接找到根本原因时(如本案例所示),我们的工具同样表现出色。
在本案例中,系统声称已在 KB5053598 更新中对该文件所做的 17 项最相关的更改内找到了根本原因。完整报告可在我们的 GitHub 代码库中找到,我们的评估流程如下。
首先,我们的工具输出了相关组件(确实为 ntfs.sys)及其相关函数 ReadRestartTable()。它还输出了一段简短的解释,说明该逻辑的设计意图(图 3)。
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().接下来,我们有与 CWE 编号相关的漏洞类别,在本例中为 CWE-125:越界读取。这有助于我们了解 LLM 在撰写此报告时寻找的漏洞。
图 4 是我们工具进行 RCA 分析后的实际输出结果。它清晰地概述了错误所在,并精准地指出了问题。
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.通过使用 IDA 和 BinDiff 对这些发现进行检查,确认这确实是正确的位置。我们之所以知道这一点,是因为 Microsoft 使用功能标志来选择性停用漏洞修复程序;这样一来,如果出现了意外行为,则可以对修复进行还原(图 5)。
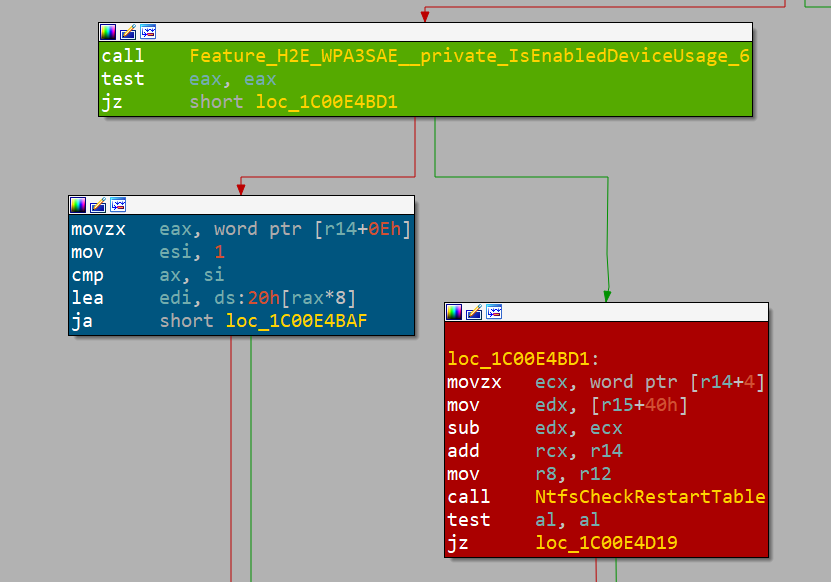 图 5:Microsoft 功能标记(绿色块)、修复路径(蓝色块)及易受攻击路径(红色块)
图 5:Microsoft 功能标记(绿色块)、修复路径(蓝色块)及易受攻击路径(红色块)
在报告中,我们可以找到该函数中被反编译的有漏洞部分的代码片段,并查看有漏洞的代码(图 6)。
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```该报告的亮点之一是自上而下的触发部分。在此部分中,LLM 就触发漏洞所必须采取的可能步骤给出了建议(如适用),甚至提供了实用的漏洞利用细节(图 7)。
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.在与后续提示词相结合时,我们的工具能够进一步分析反编译的代码并发现更多信息,甚至可以就最小概念验证 (PoC) 给出相关建议。
另一条有用的见解位于攻击媒介部分中,这些部分提供了漏洞利用的宏观概览。它让我们可以了解漏洞的范围以及攻击者利用该漏洞需满足的条件(图 8)。
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.其余部分更全面地描述了补丁本身及其对系统的安全影响。但是,在最后一部分中,我们要求 LLM 尝试质疑该补丁,看看能否在修复程序中快速识别出另一个漏洞。在本案例中,它的评估结论认为补丁是完整的:“所有错误路径现在会在任何潜在的越界访问出现之前引发异常。”
案例 2:时机成熟之时
对于负责进行检测或缓解工作的团队来说,将报告与自动生成的 IDA 数据库及 BinDiff 输出进行对照评估,不仅是有价值的,而且往往足以满足需求。但是,我们的方法更进一步——并且事实证明,它同样可用于进攻性目的。因为在某些情况下,该系统不仅能够进行分析,甚至能直接生成可运行的漏洞利用代码。
例如,CVE-2025-32713 是一个已在 2025 年 6 月的更新 (KB5060842) 中得到修补的漏洞,其相关描述如下:“Windows 公用日志文件系统驱动程序中基于堆的缓冲区溢出漏洞,允许经已获得授权的攻击者在本地提升权限。”在大约两分钟内,我们的工具生成了一份报告,将问题追溯到 CClfsLogFcbPhysical::ReadLogBlock()。
此时,有两种方法可以应对漏洞利用挑战。
手动逆向分析该函数及其调用者,直至追溯到用户模式调用
交由 LLM 处理,由其自主构建概念验证
但是,通常还有第三种选择:混合方法。将逆向工程的繁重工作交由 LLM 处理,您则专注于确定间接代码流,并理清二进制文件逻辑部分之间错综复杂的关联。这将有助于 LLM 得出更出色的结果。
利用这种做法,我们在短短几小时内便构建出了能触发蓝屏死机 (BSOD) 的漏洞利用(图 9)。
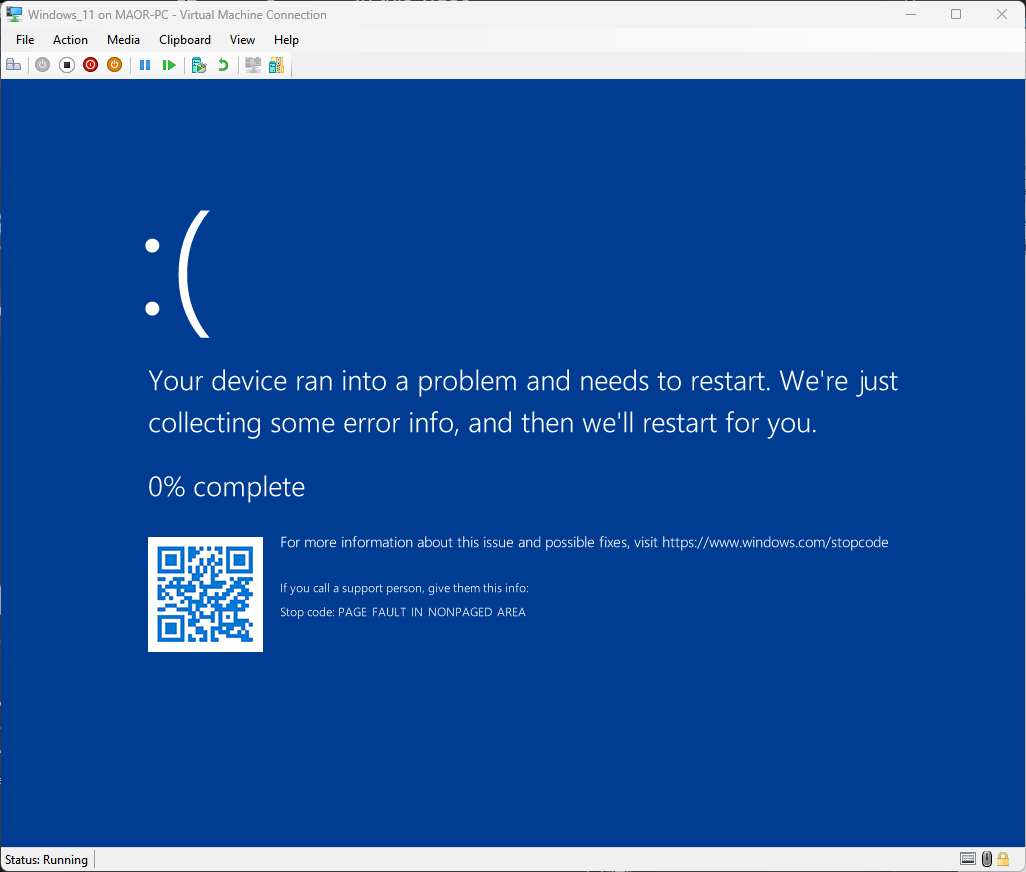 图 9:在执行 CVE-2025-32713 PoC 时出现蓝屏死机(BSOD)
图 9:在执行 CVE-2025-32713 PoC 时出现蓝屏死机(BSOD)
了解漏洞触发流程的过程从根据 RCA 部分中的描述,对所建议的有漏洞代码进行评估开始。在意识到该补丁试图修复一个安全漏洞后,我们分析了调用流,最终定位到输入/输出控制 (IOCTL) 0x80076832。
在查找用户模式对应项时,我们发现了两个候选项,因为 clfsw32.dll 会导出函数 ReadLogRecord,该函数包含一条用于调用此 IOCTL 的直接路径(图 10)。
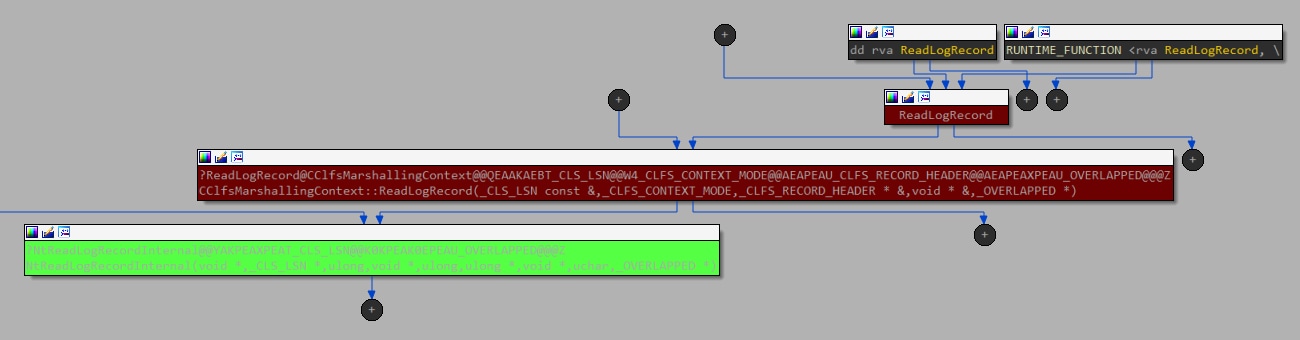 图 10:调用流程图,从用户模式导出的一个方法开始,直至内核驱动程序(通过 IOCTL 调用)
图 10:调用流程图,从用户模式导出的一个方法开始,直至内核驱动程序(通过 IOCTL 调用)
我们在每个步骤都评估了 LLM 如何在逆向工程和逻辑分析方面提供协助,同时考虑到它曾利用部分相关知识进行训练。图 11 显示了它如何满足 v4 的条件要求,即我们提供的缓冲区的大小。
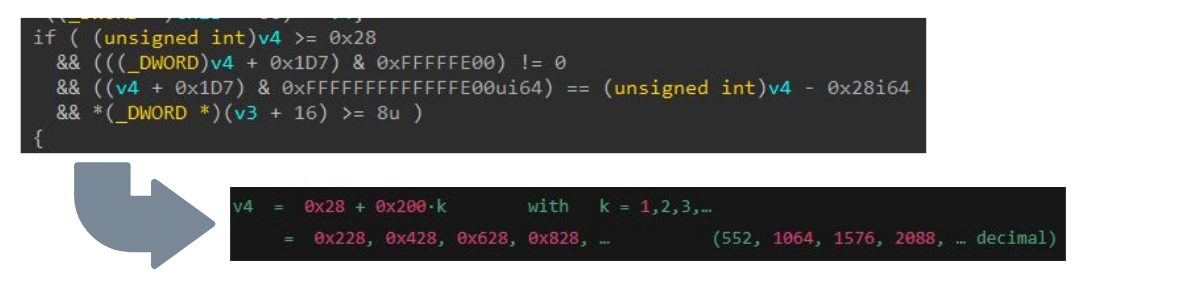 图 11:使用 LLM 分析验证检查
图 11:使用 LLM 分析验证检查
虽然我们目睹了 LLM 能够提供一些出色的见解,但在少数案例中,其结果仍具有误导性。回到 CVE-2025-32713 这个案例,在其中一个回复中,我们的报告包含了一段如图 12 所示的引文。
“crafts the log header so that the page size (v48) exceeds the supplied buffer”此回复非常令人困惑,并最终误导我们偏离了了解有漏洞代码触发方式的正确方向。事实上,它将我们引向了一条完全无关的研究方向(我们曾试图操纵已部署缓解措施的 .blf 文件结构)。随后,我们创建了具有不同物理和逻辑扇区字节数的虚拟磁盘,并通过调试分析了它们的行为。
可以说,LLM 承担了大部分工作,但仍需经验丰富的研究人员进行密切监督。 LLM 是辅助人类的工具,前提是这种辅助必须准确得当。
模型偶尔会偏离正轨,走向无效的方向,因此人工引导对于维持正确的方向至关重要。尽管如此,结果不言自明:LLM 正确识别了有漏洞的代码,精准追踪了调用流,并阐明了 v27 的错误赋值如何在 CcCopyRead() 中导致溢出。
案例 3:大海捞针
在某些情况下,您需要谨慎地对待 LLM 的输出内容。幻觉并不是 LLM 存在的唯一风险;各类 LLM 界面中反复重申了这一点(例如,“ChatGPT 也可能会犯错。请核查重要信息。”)
尽管系统会尝试验证其输入输出,并检查多条路径以确定根本原因,但这里同样需要保持谨慎。有时,这几乎是不可能的,因为条件过于宽泛且模棱两可。
我们以 5 月 KB5058411 更新中的 CVE-2025-29974 为例。MSRC 关于该漏洞的信息页面指出:“Windows 内核中的整数下溢(回绕或环绕)允许未经授权的攻击者通过相邻网络泄露信息”,这种表述可能略显晦涩。
接下来,我们注意到 MSRC 页面提到攻击者必须在附近;也就是说,攻击者必须在能够接收无线电传输的范围内。这显然是指突破物理隔离的信息外泄。但是,目前尚不清楚如何触发,或者需要通过何种硬件来触发。这种相关背景的缺失会降低生成有效报告的几率,甚至完全无法生成报告。
针对 CVE-2025-29974,我们运行了自己的工具,并得到了一份关于两个未命名函数 sub_1408E6D3C 和 sub_1408FAD58 的报告。为了方便起见,我们将它们称为 primary() 和 secondary()。图 13 是这些函数的 BinDiff 视图,很容易看出它们差异显著……要我说的话,这种差异未免太大了。
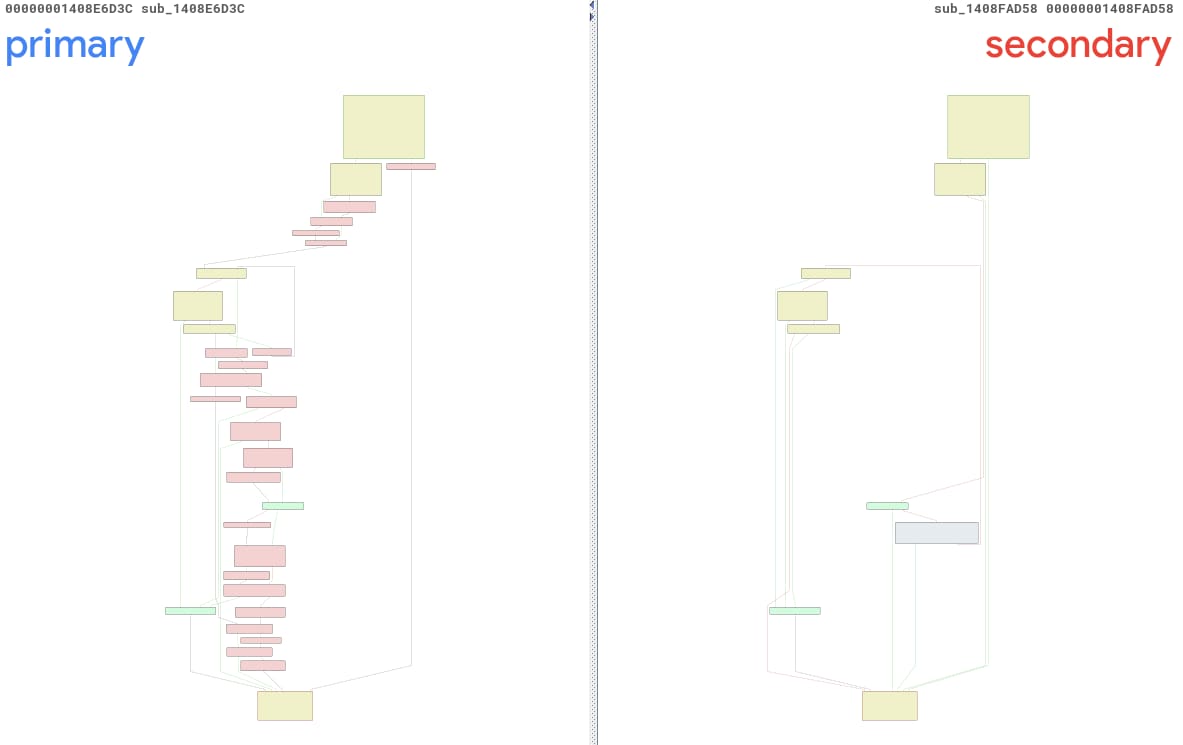 图 13:使用 PatchDiff-AI 自动创建的 BinDiff 变更视图
图 13:使用 PatchDiff-AI 自动创建的 BinDiff 变更视图
经过仔细研究,我们可以确认正确的主函数为 sub_1408E7738,这是一个位于不同地址的截然不同的方法。造成这种混淆的主要原因在于,ntoskrnl.exe 已通过此更新进行了大幅修改。有 3,791 个函数进行了修改,这导致找到正确前后匹配对的可能性大幅降低。
随本案例报告提供的置信度为 0.2,这表明该报告找到正确漏洞的置信度为 20%。这种置信度,加上大量的代码块修改,正好说明了为何结果不尽如人意。
案例 4:存在多个漏洞
在某些情况下,组件包含多个由此次更新一并修复的漏洞。这种情况并不少见,因为单个逻辑缺陷可能包含一连串不同类别的漏洞。
查看 KB5055523(2025 年 4 月)更新,我们便可以发现一组名为 CVE-2025-24058、CVE-2025-24060、CVE-2025-24062、CVE-2025-24073 和 CVE-2025-24074 的漏洞(图 14)。它们都与桌面窗口管理器 (DWM) 相关,并且都源于“CWE-20:输入验证不当”,这导致模型无法清晰分辨它们而产生混淆。
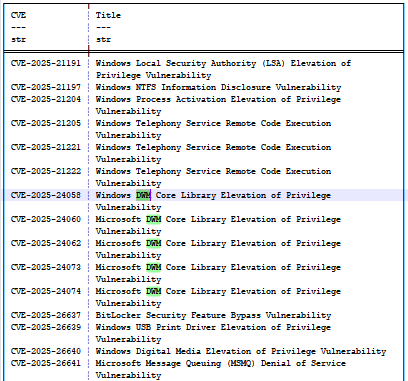 图 14:2025 年 4 月更新漏洞的部分列表
图 14:2025 年 4 月更新漏洞的部分列表
使用 LLM 需要权衡利弊。它们的共同点在于成本因素。即使所需的上下文不一致,LLM 也会尝试在一次迭代中完成任务。为了获得更准确的结果,我们必须利用启发式方法对结果进行评估并优化上下文,从而生成更高质量的变异版本。
我们使用了涉及 2025 年 4 月更新漏洞的报告来评估此类应用场景的结果。通过对比根本原因与额外信息,我们得以了解在 LLM 进行分析的过程中多个漏洞是如何对其产生影响的(见表)。
CVE | 主要故障函数 | 漏洞类别 | 根本原因 |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | 输入验证不当导致的基于堆的内存损坏/ 动态数组增长期间的整数溢出(CWE-20 导致 CWE-787)。 | 同样的 PreSubgraph 整数回绕触发了遮挡信息缓冲区溢出 |
CVE-2025-24073 | COcclusionContext::PreSubgraph | 输入验证不当导致的基于堆的缓冲区溢出/ 整数溢出(CWE-20,导致内存损坏) | 同样的 PreSubgraph 整数回绕触发了遮挡信息缓冲区溢出 |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | 输入/边界验证不当导致越界堆写入 | 同样的 PreSubgraph 整数回绕触发了遮挡信息缓冲区溢出以及另一个溢出 |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | 由于将已释放的对象指针作为隐式 this 指针传递 而导致的释放后使用/类型混淆(CWE-416、CWE-843) | 已释放的 CD3DDevice 指针被重用为 CDeviceManager 的 this 指针 |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | 由于未对调用者提供的列表长度进行适当的输入验证 而引发的基于堆的缓冲区溢出(CWE-20,导致 CWE-122) | 使用 CollectOverlayCandidates 的堆溢出 |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | 指针截断/输入验证不当导致释放后 使用/权限提升(CWE-20,与 CWE-704 相关) | 参数扩展至 __int64;新增 IsOverlayCandidateCollectionEnabled() |
通过 LLM 确定了多个漏洞及其 RCA
该表仅反映了报告的内容。对 2025 年 4 月更新漏洞的评估揭示了 CVE-2025-24074、CVE-2025-24073 和 CVE-2025-24060 的重复情况。这三个函数都涉及同一函数,但有细微的更改或增补。
CVE-2025-24058 (dwmcore.dll) 似乎与 CVE-2025-24060 对 ComputeOverlayConfiguration 的考量存在重叠。然而,CVE-2025-24058 (dwmcorei.dll) 与 CVE-2025-24062 似乎解决的是截然不同的根本原因。
由于 LLM 并非确定性系统,因此即使输入完全相同,输出也可能存在差异。由此可见,输入上下文中哪怕最细微的变化也会影响 LLM 的输出,从而产生两份不同的报告。
成本
PatchDiff-AI 基于监督式多智能体架构,采用不同的 LLM 模型,能够在保持高准确性的同时降低成本。成本明细显示,使用 OpenAI 模型生成一份报告的费用上限为 1.43 美元。
在实际操作中,我们利用 3 月、4 月和 5 月的更新生成了 131 份报告,并且仅针对 Windows 11 24H2 x64 版本进行了筛选。每份报告的平均成本约为 0.14 美元。考虑到每天(甚至每小时)都需要应对大量漏洞,一旦规模扩大,这些成本将变得相当可观。
在启用全自动功能(例如 Windows 内部机制智能体和漏洞研究智能体中的深度优化)的情况下,虽然可以设定价格上限,但由于系统的非确定性本质,因此无法计算出平均值。
结论
在网络安全领域中,AI(特别是 LLM)的应用前景一片光明。LLM 能够轻松将极度复杂但有章可循的过程转化为简单的工作流,并能融入各类安全团队的工作流程中。
我们的研究表明,漏洞的全自动 RCA 不仅可行,而且具有实用价值——兼具可观的准确率与合理的成本。
通过将问题分解为微型任务,并将其适配至一种结合了 Windows 内部机制推理、逆向工程工作流及特定漏洞分析的专用多智能体架构,我们使 LLM 成功突破了其传统限制。此实践(以及 PatchDiff-AI 配套工具)也可以推广到其他产品和平台。
通过使用我们的系统,安全团队能够制定全面的检测方案,有效抵御漏洞,并为其系统设计渗透与回归测试。此外,我们的系统还有助于缩短触发已知漏洞的流程,从而推动对有漏洞的共享代码库的深入研究和变体发现。

标签


