
Synthèse
Dans le cadre de cette étude, nous avons examiné l'utilisation de grands modèles de langage (LLM) pour identifier la cause première des vulnérabilités résolues par des correctifs.
Nous avons développé un système multi-agent, appelé PatchDiff-AI, qui analyse de manière autonome la cause première des vulnérabilités Patch Tuesday et génère un rapport détaillé.
Il aide ainsi les équipes de sécurité à analyser les vulnérabilités presque instantanément, que ce soit à des fins défensives ou offensives.
En utilisant plusieurs stratégies, nous avons pu affiner notre système pour atteindre un taux de réussite de plus de 80 % dans la génération de rapports entièrement automatisée, y compris l'analyse des vecteurs d'attaque et le flux de déclenchement.
Patch Tuesday → Exploit Wednesday
Le cycle de mise à jour régulier de Microsoft tourne autour des Patch Tuesdays : la publication d'une liste complète des CVE et leurs correctifs correspondants le deuxième mardi de chaque mois. Ces correctifs sont fournis sous forme de fichiers Microsoft Standalone Update (MSU), un format de package qui applique les mises à jour en corrigeant ou en remplaçant des fichiers système de base.
Après la publication du Patch Tuesday, les attaquants se précipitent pour découvrir les vulnérabilités pour lesquelles Microsoft a créé un correctif, un phénomène que l'on appelle l'« Exploit Wednesday ». En effectuant un différentiel binaire (binary diffing) sur les fichiers binaires mis à jour, les attaquants peuvent rapidement identifier les problèmes de sécurité sous-jacents et tenter de les exploiter avant que les entreprises n'aient eu le temps de déployer les correctifs à grande échelle.
En parallèle, les équipes de protection se hâtent également d'analyser ces correctifs afin de comprendre les causes premières des vulnérabilités et de créer des détections ainsi que des mesures d'atténuation.
État actuel du différentiel de correctifs
Aujourd'hui, le différentiel de correctifs (patch diffing) est un processus fastidieux. Pour identifier correctement le code vulnérable, un chercheur doit :
repérer le fichier susceptible de contenir la vulnérabilité ;
effectuer un différentiel binaire pour identifier les changements ;
isoler les modifications liées à la sécurité des autres mises à jour de code de routine ;
analyser les parties suspectes et comprendre la cause première ;
examiner de manière dynamique les flux d'appels pour trouver des voies de déclenchement potentielles ;
évaluer la complétude du correctif.
Ces étapes peuvent parfois prendre plusieurs semaines, un problème qui ne fait que s'aggraver en raison du volume massif de vulnérabilités publiées au même moment chaque mois.
Nous souhaitions trouver une meilleure méthode, qui permettrait aux chercheurs d'analyser rapidement les vulnérabilités corrigées et de comprendre leurs causes premières.
Utilisation de grands modèles de langage (LLM) pour l'analyse différentielle de correctifs
Les grands modèles de langage (LLM) peuvent générer des informations statistiques raisonnables et précises à partir de leurs données d'entraînement, ainsi que des entrées des utilisateurs. Cependant, ils présentent certaines limites, notamment une fenêtre de contexte limitée (qui affecte la quantité de données traitables et les coûts opérationnels), et le problème bien connu des hallucinations.
Au fil des années, beaucoup de publications ont exploré la contribution des LLM à l'évaluation des vulnérabilités dans le secteur de la sécurité. Aujourd'hui, les LLM semblent encore éprouver des difficultés à analyser des logiciels propriétaires (closed source), et s'en sortent beaucoup mieux sur des vulnérabilités open source ou web, où du code lisible par l'humain est présent.
Aardvark d'OpenAI et l'outil d'analyse de sécurité Claude Code restent dépendants de code source lisible. À l'inverse, Big Sleep de Google Project Zero vise à détecter les vulnérabilités Zero Day. Aucune de ces approches n'analyse le binaire en environnement closed source.
Présentation de PatchDiff-AI
Notre recherche adopte une approche différente fondée sur l'utilisation de LLM pour l'analyse des causes premières (RCA) des correctifs de sécurité. Notre théorie, qui semble avoir été validée, était que le contexte supplémentaire fourni par le « diff » binaire améliorerait considérablement la capacité du LLM à comprendre du code complexe de bas niveau.
Pour cette tâche, nous avons développé un système multi-agent qui automatise l'analyse des mises à jour Microsoft Knowledge Base (KB) pour une plateforme spécifique (Figure 1). Nous l'avons nommé PatchDiff-AI.
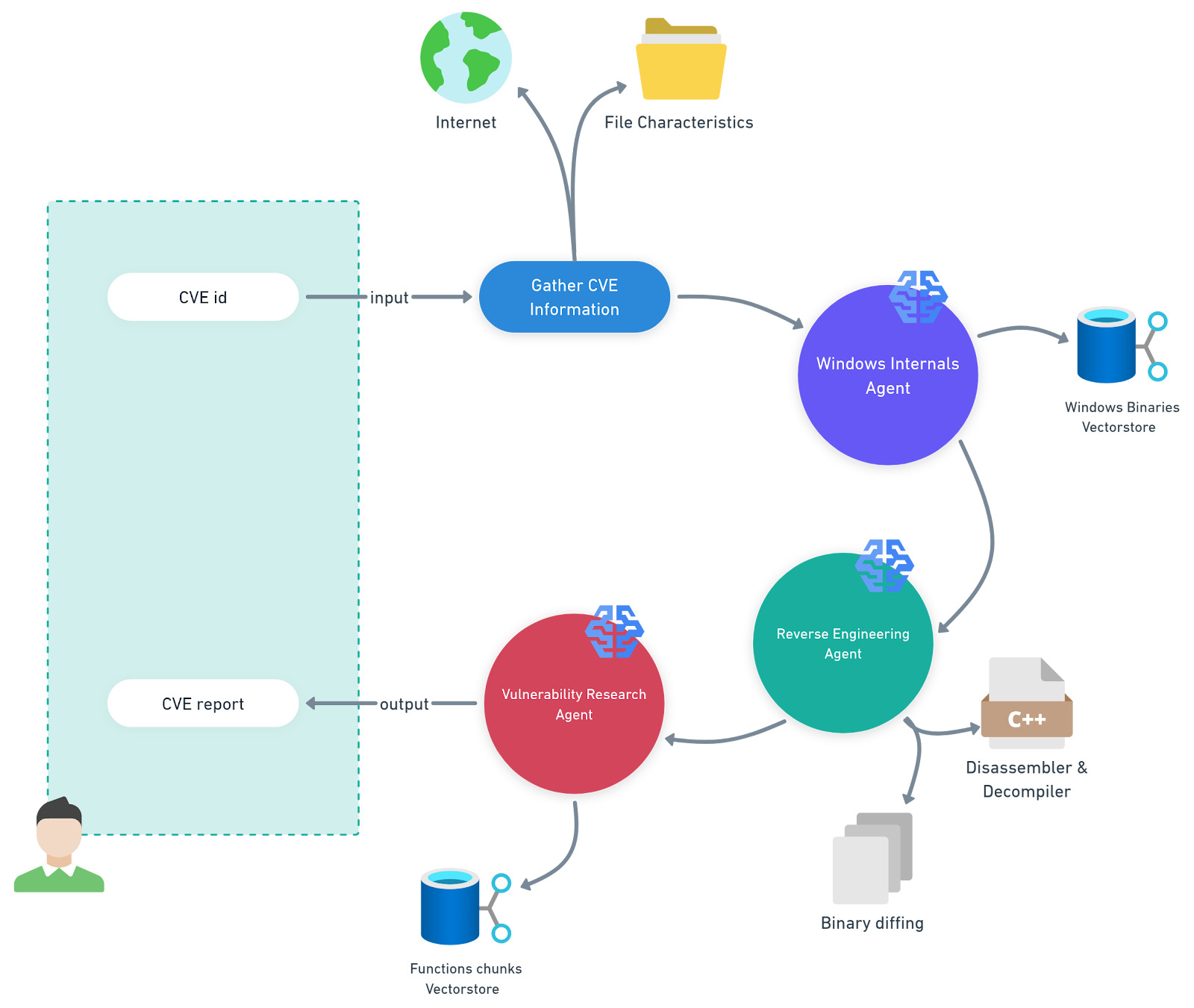 Fig. 1 : Illustration de notre système multi-agent, PatchDiff-AI
Fig. 1 : Illustration de notre système multi-agent, PatchDiff-AI
Définitions de PatchDiff-AI
Agent Windows Internals : cet agent utilise un pipeline de génération augmentée par récupération (RAG) soutenu par un magasin de vecteurs contenant les binaires Windows et leurs métadonnées fonctionnelles. Cela permet à l'agent de réduire considérablement le périmètre d'analyse et de cibler les composants les plus pertinents.
Agent de rétro-ingénierie : cet agent utilise des outils avancés de rétro-ingénierie pour l'analyse et la comparaison des fichiers pertinents. Il ajoute les artefacts trouvés au contexte global à la disposition d'autres agents.
Agent de recherche de vulnérabilité : cet agent orchestre l'analyse en rassemblant tous les artefacts et autres informations du contexte, puis en générant un rapport cohérent.
Méthodologie
En raison des limitations de la fenêtre de contexte et des hallucinations, il est crucial de fournir un contexte pertinent et concis pour utiliser les LLM efficacement, tout en maintenant une haute précision dans l'isolation des composants vulnérables et en réduisant les coûts opérationnels.
Diviser pour mieux régner
Un élément clé de notre implémentation consistait à diviser l'analyse en plusieurs tâches plus petites et ciblées, qui opèrent finalement comme des agents :
Récupérer des informations sur la CVE pour créer un profil
Télécharger les mises à jour pertinentes et appliquer les deltas aux fichiers de la version de base
Créer un agent Windows Internals piloté par l'IA pour isoler les fichiers pertinents à l'aide des métadonnées de vulnérabilité
Créer un agent de rétro-ingénierie piloté par l'IA capable de :
désassembler et appliquer les symboles, puis les exporter pour effectuer un différentiel binaire ;
mettre en corrélation les binaires et identifier les changements ainsi que les flux d'appels ;
repérer le bloc de code vulnérable.
Créer un agent de recherche de vulnérabilité piloté par l'IA pour itérer sur les chemins possibles et trouver le meilleur résultat
Un avantage majeur de cette division est la possibilité d'utiliser des modèles spécifiques pour chaque tâche : OpenAI o4-mini pour l'enrichissement des métadonnées et OpenAI o3 pour l'analyse approfondie du code susceptible d'être vulnérable.
Choisir le bon modèle pour chaque tâche améliore à la fois la précision et les coûts.
Enrichissement du contexte
Les LLM sont des machines qui « retiennent » une grande quantité d'informations. Utiliser un prompt pour invoquer un LLM permet de l'ajuster afin qu'il fournisse les informations les plus pertinentes selon le prompt.
Chaque élément contextuel fourni au LLM concernant la vulnérabilité corrigée améliore la précision de la réponse et augmente les chances de localiser le code vulnérable. À l'inverse, des informations ambiguës sur la vulnérabilité entraîneront de mauvais résultats.
L'enrichissement du contexte avec les métadonnées de vulnérabilité lors de l'analyse s'est avéré essentiel. Pour ce faire, nous avons fourni au LLM les descriptions KB, les descriptions des fichiers système et les données de différentiel binaire. Cette approche nous a permis de réduire le nombre de modifications à analyser, et donc la longueur du contexte et le nombre d'itérations avec le LLM.
Résultats
Nous avons évalué notre cadre selon sa capacité à identifier correctement :
le fichier exécutable vulnérable correspondant à la CVE ;
la fonction vulnérable dans cet exécutable ;
la cause première de la vulnérabilité (ainsi que sa capacité à l'expliquer de manière précise et détaillée).
Sur la base de ces paramètres, nous avons analysé les trois dernières versions Patch Tuesday pour Windows 11 24H2. Nous avons déployé notre outil et généré un rapport automatisé, puis nous avons inspecté manuellement les résultats sélectionnés et déterminé la précision de la réponse finale du modèle.
Après ajustement du contexte et des différents modèles spécifiques à chaque tâche, nous avons obtenu les résultats suivants :
Identification correcte de l'exécutable corrigé pour la CVE dans 88,6 % des cas
Identification correcte de la fonction vulnérable dans 83,9 % des cas
Identification correcte de la cause première de la vulnérabilité dans 71,4 % des cas
En excluant les échecs liés à un contexte insuffisant (pannes d'analyse statique, impossibilité d'appliquer le delta…), nous pouvons estimer le taux de réussite du LLM lorsque le bloc de code correct est fourni. Dans ce cas, le taux de réussite du LLM atteint environ 96 % lorsque le bloc de code correct est fourni dans le contexte (Figure 2).
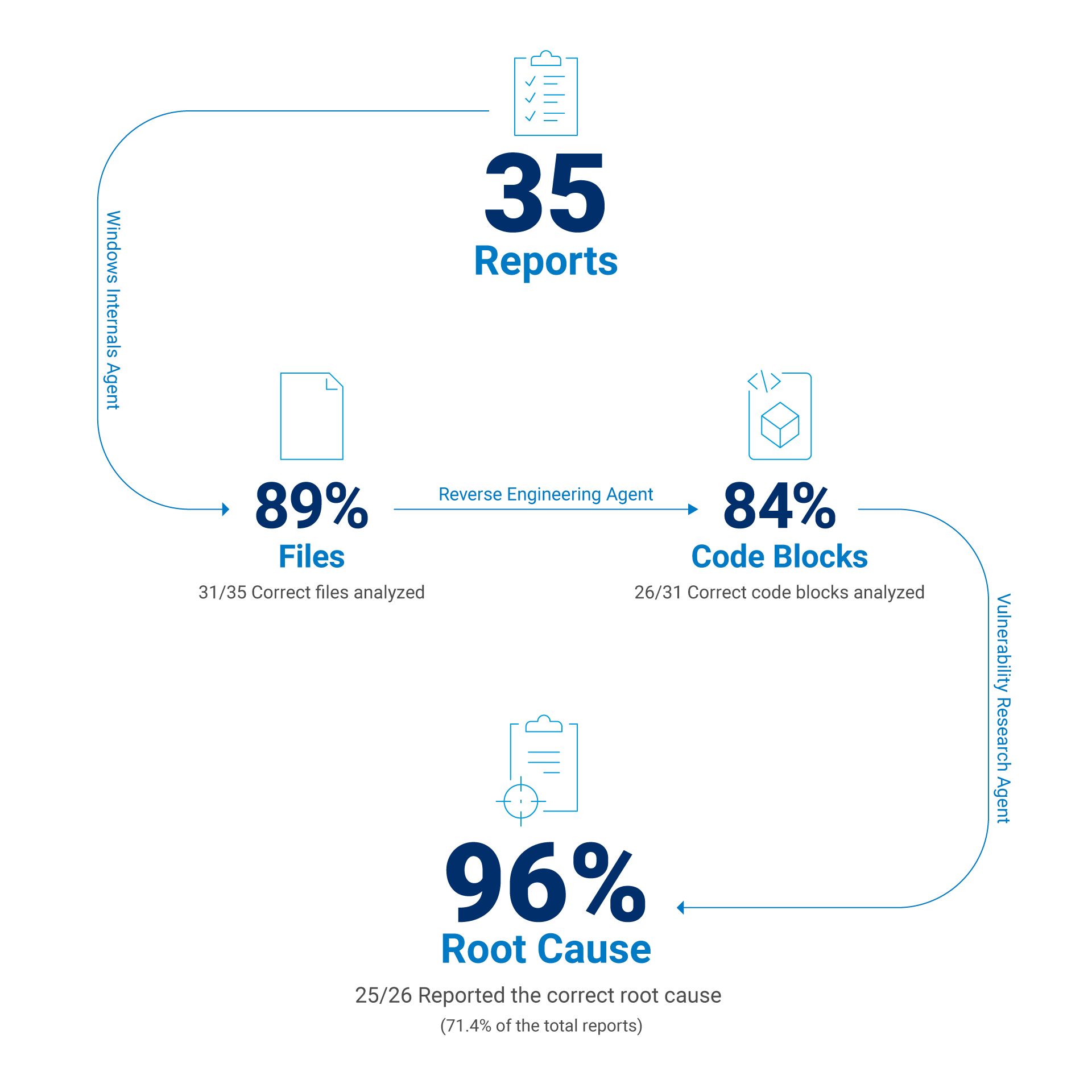 Fig. 2 : Résultats de l'évaluation de rapports sélectionnés sur les CVE
Fig. 2 : Résultats de l'évaluation de rapports sélectionnés sur les CVE
Le rapport CVE et ses composants
Nous avons rencontré plusieurs cas intéressants que nous aimerions vous présenter et étudier en détail. Chaque rapport suit la même structure :
Détails de la CVE qui composent le rapport
Analyse RCA (le cœur du rapport)
Extrait de code avant et après le correctif
Vue descendante de la manière dont la vulnérabilité peut être déclenchée
Description mise en évidence du correctif
Vecteur d'attaque qui pourrait exploiter la vulnérabilité
Impact clair et détaillé de la vulnérabilité
En outre, la dernière section de chaque rapport tente de remettre en question l'efficacité du correctif et de trouver un potentiel contournement.
Études de cas
Dans les quatre études de cas suivantes, nous allons explorer plusieurs situations intéressantes qui mettent en évidence les points forts de notre cadre, ses difficultés, ainsi que ses échecs complets.
Étude de cas n° 1 : monter et exploiter
L'une des vulnérabilités que nous avons analysées est CVE-2025-24991, un bug décrit par le Microsoft Security Response Center (MSRC) comme « une lecture hors limites dans Windows NTFS permettant à un attaquant autorisé de divulguer localement des informations ». Une autre information, issue de la FAQ, indique qu'« une personne malveillante peut piéger un utilisateur local sur un système vulnérable en l'incitant à monter un disque dur virtuel spécialement conçu pour déclencher la vulnérabilité ».
La vulnérabilité est donc clairement liée au composant NTFS, ce qui induit très probablement l'implication de ntfs.sys.
Autre indice allant dans ce sens : la vulnérabilité s'active lorsqu'un fichier VHD est monté. Analyser manuellement le correctif nous prendrait habituellement des heures, mais grâce à l'outil PatchDiff-AI, cela ne nous prend plus que quelques minutes. Ce constat est d'autant plus significatif que notre outil fonctionne tout aussi bien même lorsqu'il n'existe pas de chemin évident pour identifier la cause première, comme c'était le cas ici.
Dans cette situation, le système indique avoir trouvé la cause première parmi les 17 modifications les plus pertinentes apportées au fichier dans la mise à jour KB5053598. Le rapport complet est disponible dans notre référentiel GitHub, et notre processus d'évaluation est le suivant.
Tout d'abord, notre outil identifie le composant pertinent, qui est ntfs.sys, comme nous le pensions, et la fonction concernée, ReadRestartTable(). Il fournit également une brève explication du rôle logique de cette fonction (Figure 3).
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().Ensuite, la classe de vulnérabilité est corrélée à l'index CWE, qui dans ce cas est CWE-125: Out-of-bounds Read. Cela nous aide à comprendre sur quel type de vulnérabilité le LLM se concentre lors de la génération du rapport.
La Figure 4 illustre la sortie réelle de l'analyse RCA de notre outil. Elle décrit clairement le problème et en identifie la source avec précision.
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.En inspectant ces résultats à l'aide d'IDA et de BinDiff, nous constatons qu'il s'agit bien du bon endroit. Nous le savons notamment parce que Microsoft utilise des « feature flags » (bascules de fonctionnalité) pour désactiver le correctif si nécessaire, permettant de revenir en arrière en cas de comportement inattendu (Figure 5).
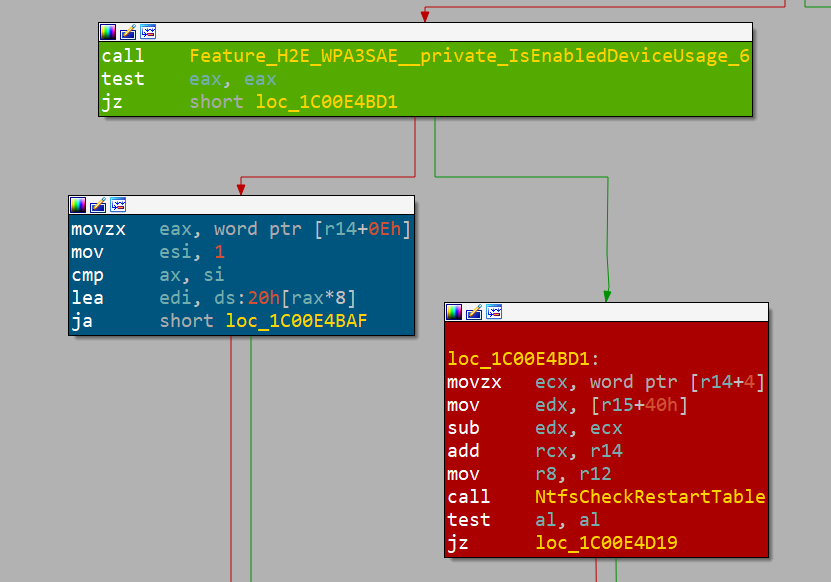 Fig. 5 : Indicateur de fonctionnalité (feature flag) Microsoft (bloc vert), chemin corrigé (bloc bleu) et chemin vulnérable (bloc rouge)
Fig. 5 : Indicateur de fonctionnalité (feature flag) Microsoft (bloc vert), chemin corrigé (bloc bleu) et chemin vulnérable (bloc rouge)
Dans le rapport, nous pouvons trouver les extraits de code de la partie vulnérable décompressée de la fonction, et ainsi examiner le code vulnérable (Figure 6).
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```L'un des points forts du rapport est la section de déclenchement descendant. Dans cette section, le LLM suggère les étapes nécessaires au déclenchement de la vulnérabilité, allant parfois jusqu'à fournir des détails pratiques d'exploitation (Figure 7).
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.Lorsque l'on combine cela avec des prompts complémentaires, notre outil peut analyser plus en profondeur le code décompilé, découvrir davantage d'informations et même suggérer une preuve de concept minimale (PoC).
Une autre section utile est celle des vecteurs d'attaque, qui fournit une vue d'ensemble sur la manière dont la vulnérabilité peut être exploitée. Celle-ci donne une idée du périmètre de la vulnérabilité et de ce dont un attaquant a besoin pour l'exploiter (Figure 8).
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.Les sections restantes fournissent une description plus générale du correctif et de son impact sur la sécurité du système. Toutefois, dans la dernière section, nous avons demandé au LLM de remettre en question le correctif et de vérifier s'il était possible d'identifier rapidement une vulnérabilité résiduelle. Ici, il a conclu que le correctif était complet : « All error paths now raise before any potential out-of-range access. » (Tous les champs d'erreur déclenchent désormais une exception avant qu'un accès hors limites ne puisse se produire)
Étude de cas n° 2 : lorsque les astres s'alignent
Pour les équipes axées sur la détection ou la mitigation, il est utile (et souvent même suffisant) de confronter le rapport à la base IDA générée automatiquement ainsi qu'aux sorties de BinDiff. Cependant, notre approche va plus loin et peut également s'avérer utile à des fins offensives, car dans certains cas, le système peut aller au-delà de l'analyse et produire une exploitation efficace.
Par exemple, la vulnérabilité CVE-2025-32713 corrigée dans la mise à jour de juin 2025 (KB5060842) était décrite comme suit : « un dépassement de tampon dans le tas dans le pilote Windows Common Log File System permettant à un attaquant autorisé d'élever des privilèges localement ». En environ deux minutes, notre outil a généré un rapport retraçant le problème jusqu'à CClfsLogFcbPhysical::ReadLogBlock().
À ce stade, deux façons sont possibles pour aborder le défi de l'exploitation :
Inverser manuellement la fonction et ses appelants jusqu'à l'appel en mode utilisateur
Laisser le LLM faire le travail et créer une PoC de manière autonome
Cependant, comme souvent, il existe une troisième option : l'approche hybride. Elle consiste à confier au LLM la rétro‑ingénierie, tandis que l'humain détermine les flux de code indirects et résout les connexions complexes entre les différentes parties logiques du binaire. Cela permet au LLM de produire de meilleurs résultats.
En utilisant cette méthodologie, nous avons obtenu une exploitation provoquant un écran bleu (BSOD) en seulement quelques heures (Figure 9).
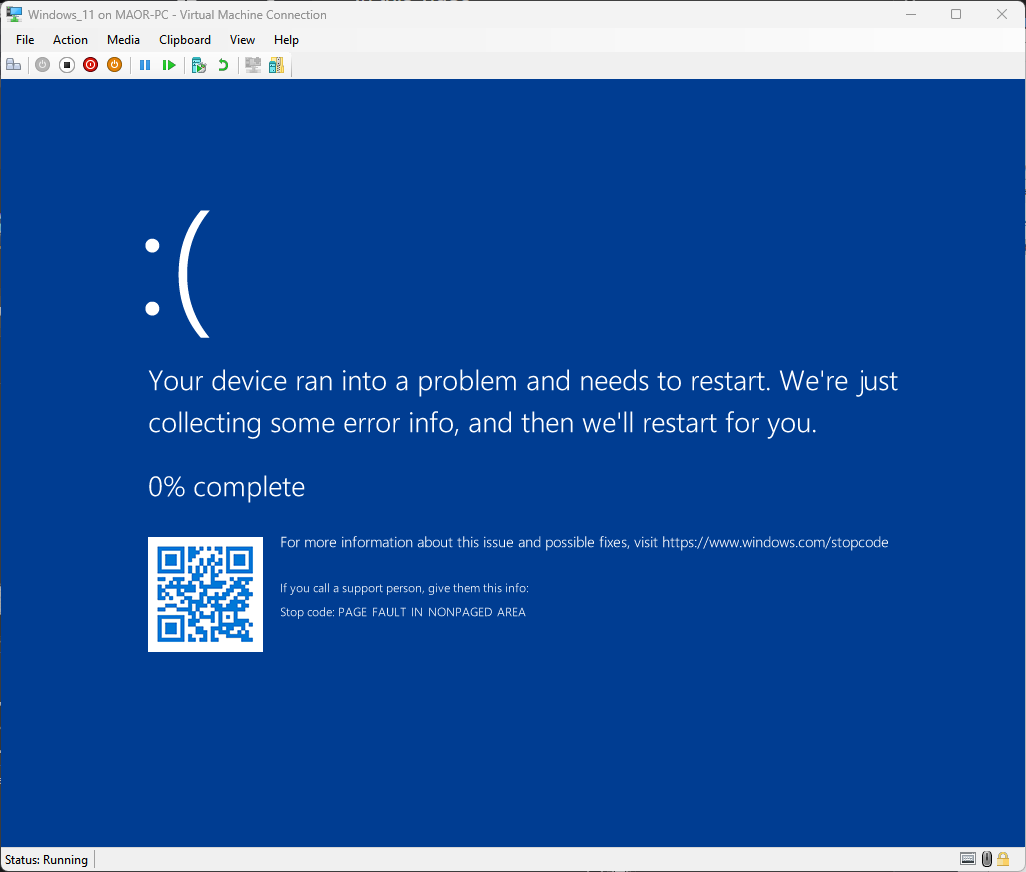 Fig. 9 : BSOD lors de l'exécution du PoC pour la CVE-2025-32713
Fig. 9 : BSOD lors de l'exécution du PoC pour la CVE-2025-32713
Le travail visant à comprendre le flux de déclenchement de la vulnérabilité a commencé par l'évaluation du code vulnérable suggéré, tel que décrit dans la section RCA. Après avoir compris que le correctif visait à corriger une faille de sécurité, nous avons analysé le flux d'appels jusqu'au contrôle d'entrée/sortie (IOCTL) 0x80076832.
En cherchant les équivalents côté mode utilisateur, nous avons trouvé deux candidats, car clfsw32.dll exporte la fonction ReadLogRecord, avec un chemin direct permettant d'invoquer cet IOCTL (Figure 10).
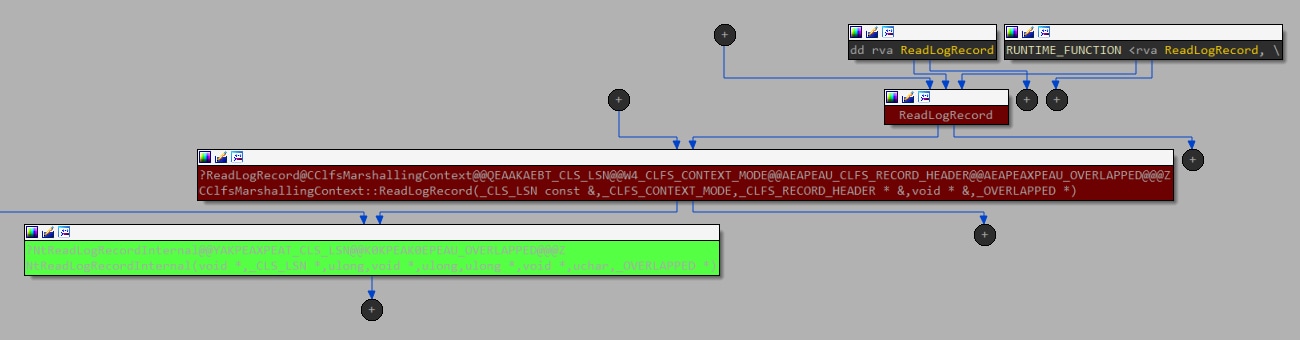 Fig. 10 : Graphe de flux d'appels, commençant par une méthode exportée du mode utilisateur jusqu'au pilote noyau (en utilisant l'appel IOCTL)
Fig. 10 : Graphe de flux d'appels, commençant par une méthode exportée du mode utilisateur jusqu'au pilote noyau (en utilisant l'appel IOCTL)
À chaque étape, nous avons évalué comment le LLM pouvait aider à la rétro‑ingénierie et à l'analyse de la logique, en tenant compte du fait qu'il avait été entraîné sur une partie de ces connaissances. La Figure 11 montre comment il a pu résoudre la condition requise pour v4, qui correspond à la taille du tampon fourni.
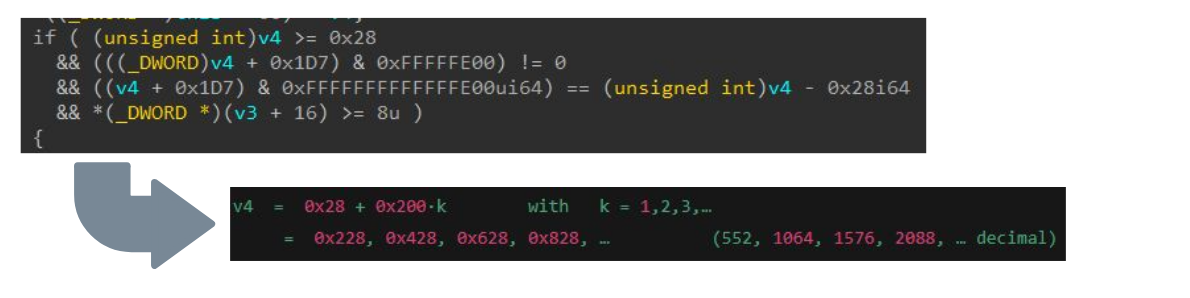 Fig. 11 : Utilisation d'un LLM pour analyser un contrôle de validation
Fig. 11 : Utilisation d'un LLM pour analyser un contrôle de validation
Bien que le LLM ait produit d'excellentes observations, certains résultats se sont avérés trompeurs. Concernant CVE‑2025‑32713, l'une des réponses contenait la phrase présentée à la Figure 12.
“crafts the log header so that the page size (v48) exceeds the supplied buffer”Cette réponse était assez déroutante et nous a éloignés de la compréhension du mécanisme réel de déclenchement. En pratique, cela nous a conduits sur une piste totalement incorrecte (nous avons tenté de manipuler la structure du fichier .blf déjà protégée par des mesures d'atténuation). Nous avons ensuite créé des disques virtuels avec différentes tailles de secteurs physiques et logiques, et analysé leur comportement en phase de débogage.
Nous pouvons dire que le LLM a réalisé l'essentiel du travail, mais qu'il a nécessité une étroite supervision de la part d'un chercheur expérimenté. Les LLM sont un outil qui assiste les humains, à condition que l'assistance soit correctement encadrée.
Le modèle peut occasionnellement aller dans des directions improductives, et l'intervention humaine était primordiale pour le maintenir sur la bonne voie. Cela dit, les résultats parlent d'eux-mêmes : le LLM a correctement identifié le code vulnérable, retracé avec précision le flux d'appels et expliqué comment l'assignation incorrecte de v27 a entraîné le dépassement dans CcCopyRead().
Étude de cas n° 3 : une aiguille dans une botte de foin
Dans certains cas, vous devez prendre en compte les sorties du LLM avec précaution. Les hallucinations ne sont pas le seul risque, comme le rappellent inlassablement les différentes interfaces LLM (« ChatGPT peut faire des erreurs. Envisagez de vérifier les informations importantes. »)
La même prudence s'impose ici, même si le système tente de valider ses entrées et sorties et d'examiner plusieurs chemins pour identifier la cause première. Il arrive parfois que cela soit presque impossible, car les conditions sont trop vastes et ambiguës.
Prenons la vulnérabilité CVE-2025-29974, issue de la mise à jour KB5058411 de mai. Selon la page d'informations MSRC, il s'agit d'« un débordement inférieur (integer underflow), dû à un retour à zéro ou un réenroulement de valeur dans le noyau Windows, permettant à un attaquant non autorisé de divulguer des informations via un réseau adjacent », ce qui reste assez vague.
Le MSRC mentionne également que l'attaquant doit être à proximité, c'est‑à‑dire dans la zone de réception de transmissions radio. Cela suggère clairement une exfiltration d'informations via un canal latéral radio (air gap). Ce qui reste flou, c'est comment cela se produit, ou via quel matériel. Cette absence de contexte réduit fortement les chances d'obtenir un rapport valide.
Pour CVE‑2025‑29974, notre outil a généré un rapport impliquant deux fonctions anonymes : sub_1408E6D3C et sub_1408FAD58, que nous appellerons primary() et secondary() pour simplifier la compréhension. La Figure 13 présente une comparaison BinDiff de ces fonctions, et l'on voit clairement qu'elles sont très différentes… peut‑être trop différentes.
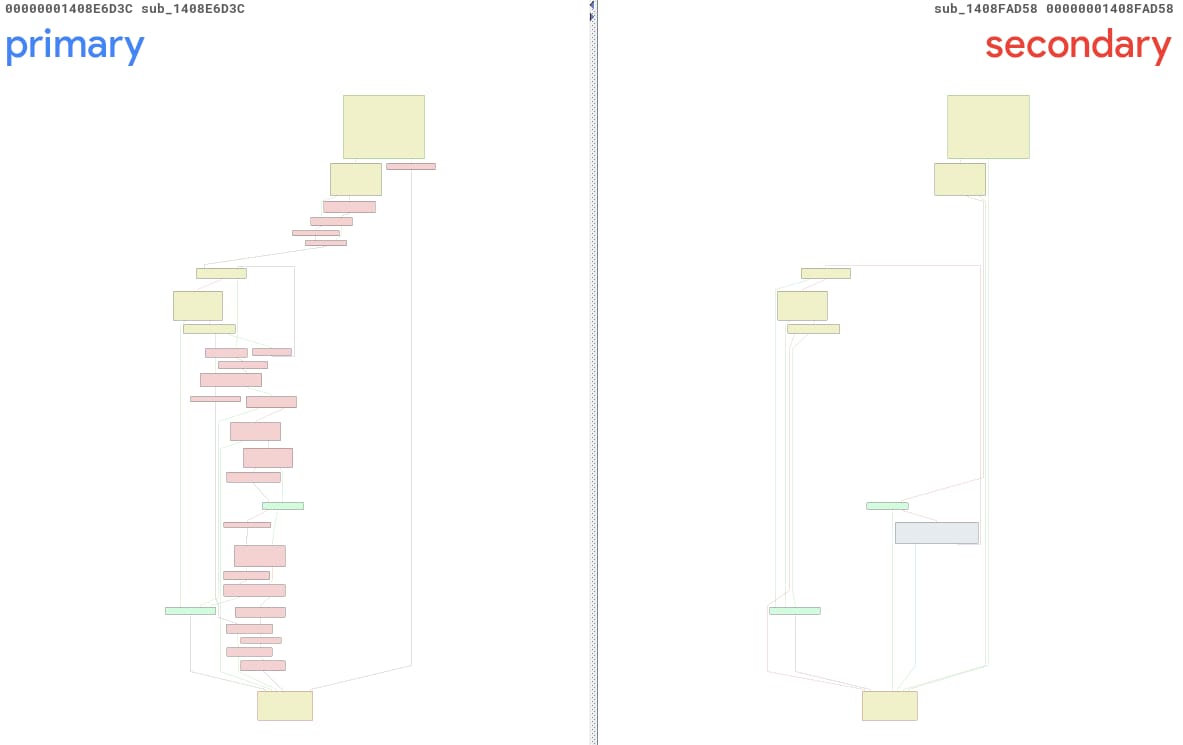 Fig. 13 : Vue BinDiff des modifications créée automatiquement à l'aide de PatchDiff-AI
Fig. 13 : Vue BinDiff des modifications créée automatiquement à l'aide de PatchDiff-AI
Après un examen plus approfondi, nous avons identifié la bonne fonction primaire comme étant sub_1408E7738, une méthode entièrement différente située à une autre adresse. La principale raison de cette confusion réside dans le fait que ntoskrnl.exe a subi de très nombreuses modifications dans cette mise à jour. 3 791 fonctions ont été modifiées, ce qui réduit drastiquement la probabilité d'apparier correctement les versions avant/après.
Le niveau de confiance associé au rapport était de 0,2, indiquant 20 % de certitude dans le fait que le rapport avait correctement localisé la vulnérabilité. Ce faible score, associé au nombre massif de blocs de code modifiés, explique les mauvais résultats.
Étude de cas n° 4 : trop vulnérable
Il arrive que le composant comporte plusieurs vulnérabilités corrigées dans une même mise à jour. Ce n'est pas rare, car une seule erreur logique peut générer une chaîne de vulnérabilités de classes différentes.
Si nous prenons la mise à jour KB5055523 (avril 2025), nous pouvons trouver un ensemble de bugs, nommés CVE-2025-24058, CVE-2025-24060, CVE-2025-24062, CVE-2025-24073 et CVE-2025-24074 (Figure 14). Ils concernent tous le Gestionnaire de fenêtres du Bureau (DWM) et relèvent tous de « CWE‑20: Improper Input Validation », ce qui les rend indistincts et ambigus pour le modèle.
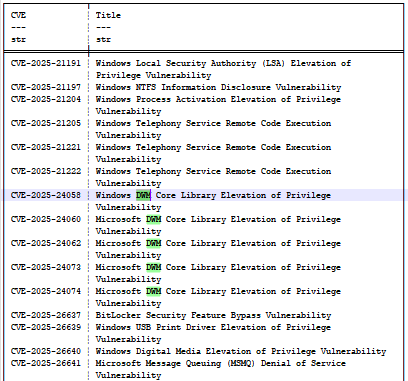 Fig. 14 : Liste partielle des bogues de la mise à jour d'avril 2025
Fig. 14 : Liste partielle des bogues de la mise à jour d'avril 2025
L'utilisation de LLM implique des compromis. Le facteur commun est le coût. Un LLM tentera de réaliser la tâche en une seule itération, même si le contexte fourni n'est pas parfaitement aligné. Pour obtenir des résultats plus précis, il faut évaluer les sorties via des heuristiques et affiner le contexte afin qu'il puisse en produire une meilleure version.
Nous avons utilisé les rapports des bugs de la mise à jour d'avril 2025 pour évaluer ce type de cas. En comparant les causes premières et les informations additionnelles, nous avons pu comprendre comment ces vulnérabilités multiples influençaient l'analyse du LLM (Tableau).
CVE | Fonction(s) principale(s) défaillante(s) | Classe de bug | Cause première |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | Corruption de mémoire dans le tas causée par une validation incorrecte des saisies / dépassement d'entier lors de l'agrandissement dynamique d'un tableau (CWE‑20, mène à CWE‑787) | Le même wrap d'entier dans PreSubgraph déclenche le dépassement du tampon occlusion‑info |
CVE-2025-24073 | COcclusionContext::PreSubgraph | Dépassement de tampon dans le tas / dépassement d'entier dû à une validation incorrecte des saisies (CWE‑20, mène à une corruption de la mémoire) | Le même wrap d'entier dans PreSubgraph déclenche le dépassement du tampon occlusion‑info |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | Validation incorrecte des saisies/des bornes conduisant à une écriture hors limites dans le tas | Le même wrap d'entier dans PreSubgraph déclenche le dépassement du tampon occlusion‑info, ainsi qu'un autre dépassement |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | Use‑after‑free / confusion de type résultant du passage d'un objet libéré comme pointeur implicite « this » (CWE‑416, CWE‑843) | Pointeur CD3DDevice libéré réutilisé comme CDeviceManager this |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | Dépassement de tampon dans le tas résultant d'une validation incorrecte des longueurs de listes fournies par l'appelant (CWE‑20, mène à CWE‑122) | Dépassement de tas via CollectOverlayCandidates |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | Troncature de pointeur / validation incorrecte des saisies conduisant à un use‑after‑ free / élévation de privilèges (CWE‑20, lié à CWE‑704) | Les arguments sont étendus en __int64 ; ajout de IsOverlayCandidateCollectionEnabled() |
Plusieurs vulnérabilités et leur RCA identifiées par le LLM
Le tableau n'est qu'un reflet du contenu des rapports. L'évaluation des bugs de la mise à jour d'avril 2025 révèle la duplication des vulnérabilités CVE‑2025‑24074, CVE‑2025‑24073 et CVE‑2025‑24060. Les trois font référence aux mêmes fonctions, avec des modifications ou des ajouts mineurs.
CVE‑2025‑24058 (dwmcore.dll) semble recouper l'analyse de ComputeOverlayConfiguration présente dans CVE‑2025‑24060. En revanche, CVE‑2025‑24058 (dwmcorei.dll) et CVE‑2025‑24062 semblent traiter des causes premières entièrement différentes.
Un LLM n'étant pas un système déterministe, la sortie peut varier même avec une entrée identique. Nous pouvons observer que des changements dans le contexte fourni, même minimes, peuvent influencer la sortie et produire deux rapports différents.
Le coût
PatchDiff-AI repose sur une architecture multi-agent supervisée, utilisant différents modèles LLM, afin de réduire les coûts tout en maintenant une grande précision. Le coût maximal pour générer un rapport avec les modèles OpenAI s'élève à 1,43 USD.
En pratique, nous avons généré 131 rapports à partir des mises à jour de mars, avril et mai, filtrés uniquement pour Windows 11 24H2 x64. Le coût moyen par rapport s'élevait à environ 0,14 USD. Lorsque l'on considère le nombre de vulnérabilités combattues tous les jours (voire toutes les heures), ces coûts peuvent devenir significatifs à grande échelle.
Lorsque des fonctionnalités entièrement autonomes sont activées, telles que l'affinement étendu dans les agents Windows Internals et les agents de recherche de vulnérabilité, le calcul du prix peut être plafonné. Toutefois, il n'est pas possible d'établir une valeur moyenne en raison de la nature indéterministe du système.
Conclusion
L'avenir de l'utilisation de l'IA, et en particulier des LLM, dans le domaine de la cybersécurité est prometteur. Les LLM peuvent facilement transformer un processus très complexe mais méthodologique en flux de travail simple, et peuvent être intégrés dans les pipelines de diverses équipes de sécurité.
Nos recherches démontrent qu'une RCA entièrement automatisée des vulnérabilités est non seulement possible, mais également pratique, avec une haute précision et un coût raisonnable.
En fragmentant le problème en micro-tâches et en l'adaptant à une architecture multi-agent spécialisée qui combine raisonnement Windows Internals, flux de travail de rétro-ingénierie et analyse spécifique à chaque vulnérabilité, nous avons permis aux LLM de surmonter leurs limitations traditionnelles. Cette pratique (ainsi que l'outil complémentaire PatchDiff-AI) peut également être étendue à d'autres produits et plateformes.
Grâce à notre système, les équipes de sécurité peuvent créer des détections complètes, atténuer efficacement les vulnérabilités et réaliser des tests de pénétration et de régression pour leurs systèmes. En outre, notre système peut contribuer à raccourcir le processus de déclenchement des vulnérabilités connues, ce qui favorise la recherche et la découverte de variantes au sein du code partagé vulnérable.

Balises


