
Resumen ejecutivo
En esta investigación, analizamos el uso de modelos de lenguaje de gran tamaño para identificar la causa raíz de las vulnerabilidades parcheadas.
Hemos desarrollado un sistema multiagente llamado PatchDiff-AI que analiza de forma autónoma la causa raíz de las vulnerabilidades de Patch Tuesday y genera un informe detallado.
Este tipo de análisis puede ayudar a los equipos de seguridad a analizar vulnerabilidades casi al instante, con fines defensivos u ofensivos.
Mediante el uso de varias estrategias, pudimos afinar nuestro sistema para lograr una tasa de éxito de más del 80 % en la generación de informes totalmente automatizada, incluido el análisis de vectores de ataque y el flujo de activación.
Patch Tuesday → Exploit Wednesday
El ciclo de actualizaciones periódicas de Microsoft se centra en los Patch Tuesdays, el segundo martes de cada mes, cuando la empresa publica una lista completa de CVE y sus correspondientes parches. Estas correcciones se envían como archivos de actualización independiente de Microsoft (MSU), un formato de empaquetado que aplica actualizaciones mediante la ejecución de parches o la sustitución de los archivos principales del sistema.
Patch Tuesday suele ir seguido de lo que se conoce como “Exploit Wednesday”, ya que los atacantes se apresuran a descubrir las vulnerabilidades para las que Microsoft ha creado un parche. Al realizar la comparación de binarios (diffing de binarios) en los archivos binarios actualizados, los atacantes pueden detectar rápidamente los problemas de seguridad subyacentes e intentar explotarlos antes de que las organizaciones hayan implementado los parches de manera amplia.
De manera similar, los expertos en protección se suelen apresurar a analizar estos parches para comprender las causas raíz de las vulnerabilidades con el fin de crear detecciones y mitigaciones.
El estado actual de la comparación de parches
En la actualidad, la comparación de parches es un proceso tedioso. Para identificar correctamente el elemento de código vulnerable, un investigador tendría que:
Identificar el archivo que se sospecha que contiene la vulnerabilidad
Realizar una comparación de binarios para identificar los cambios
Aislar los cambios relacionados con la seguridad de otras actualizaciones de código de rutina
Analizar las partes sospechosas y comprender la causa raíz
Examinar dinámicamente los flujos de llamadas para encontrar posibles vías de activación
Evaluar la finalización de la corrección del parche
A veces, estos pasos pueden tardar semanas en realizarse, un problema que se amplifica aún más por el enorme volumen de vulnerabilidades que se publican simultáneamente cada mes.
Nos propusimos encontrar una forma mejor, una que permitiera a los investigadores analizar rápidamente las vulnerabilidades parcheadas y comprender su causa raíz.
Uso de los LLM para el análisis de comparación de parches
Los modelos de lenguaje de gran tamaño (LLM) pueden generar estadísticamente información razonable y precisa basada en los datos entrenados, junto con las entradas de los usuarios. Pero existen algunas limitaciones, como una ventana de contexto limitada (que afecta a la cantidad de datos que puede procesar y a sus costes operativos) y las tristemente famosas alucinaciones de los modelos.
A lo largo de los años se han publicado numerosos documentos sobre la contribución de los LLM a la evaluación de vulnerabilidades en el sector de la seguridad. Hoy en día, los LLM parecen tener dificultades para analizar software de código cerrado y tienen un rendimiento mucho mejor cuando se trata de código abierto y de vulnerabilidades web, donde el terreno común es la presencia de código entendible.
Aardvark de OpenAI y el revisor de seguridad Claude Code siguen vinculados al código fuente entendible. Por otro lado, está el proyecto Big Sleep de Google Project Zero, que tiene como objetivo descubrir los días cero. Ninguno de los dos enfoques analiza el binario como fuente cerrada.
Presentación de PatchDiff-AI
Nuestra investigación adopta un enfoque diferente al utilizar LLM para el análisis de la causa raíz (RCA) de los parches de seguridad. Nuestra teoría, que parece haber sido validada, era que el contexto adicional proporcionado por la “diff” de binarios mejoraría significativamente la capacidad del LLM para comprender códigos complejos y de bajo nivel.
Para esta tarea, hemos desarrollado un sistema multiagente que automatiza el análisis de las actualizaciones de la Microsoft Knowledge Base (KB) para una plataforma específica (Figura 1). Lo llamamos PatchDiff-AI.
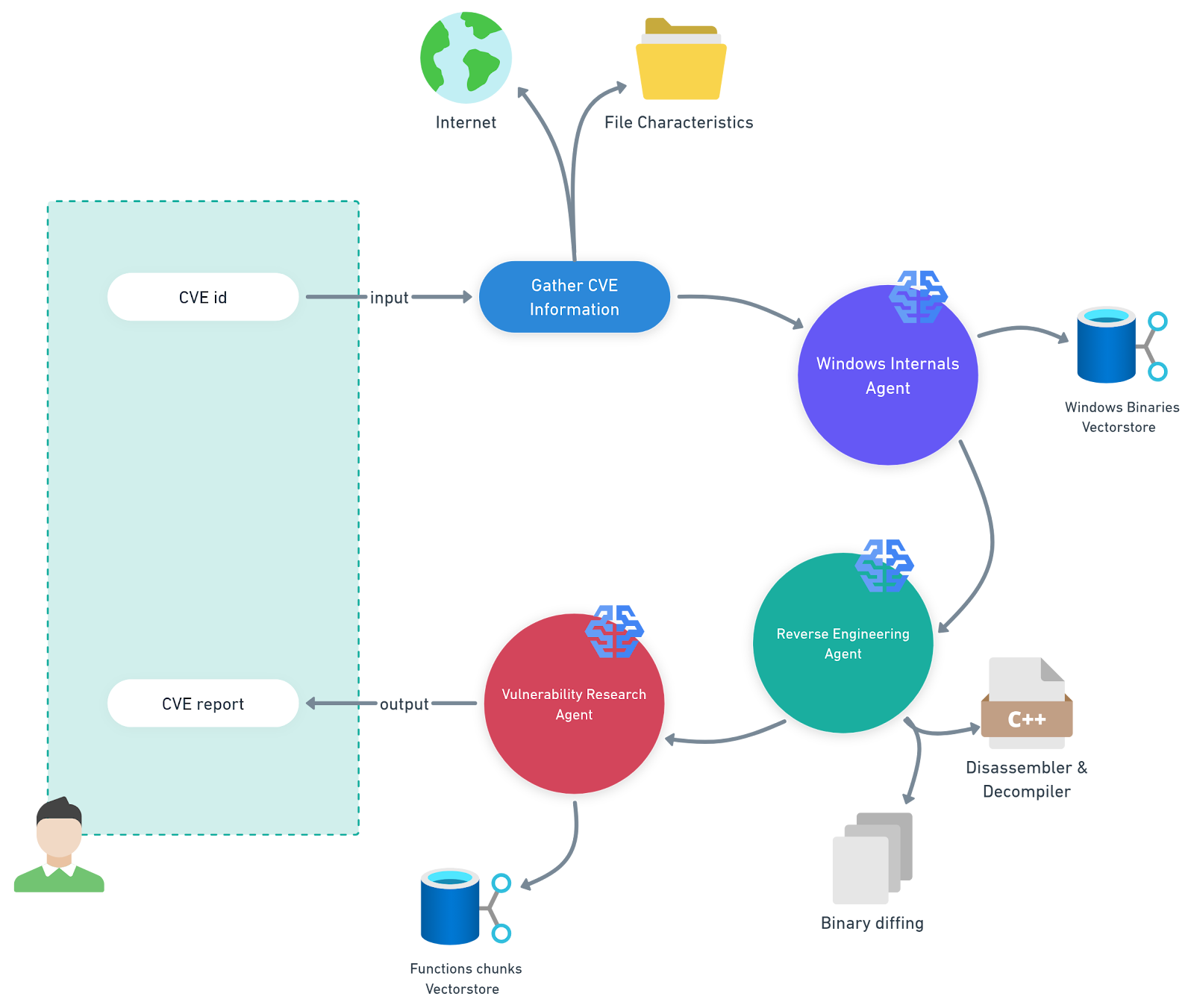 Fig. 1: Ilustración de nuestro sistema multiagente, PatchDiff-AI
Fig. 1: Ilustración de nuestro sistema multiagente, PatchDiff-AI
Definiciones de PatchDiff-AI
Agente interno de Windows: este agente utiliza un canal de generación de recuperación aumentada (RAG) respaldado por un almacén vectorial que contiene binarios de Windows y sus metadatos de funcionalidad. Esto permite al agente reducir significativamente el alcance del análisis y centrarse en los componentes más relevantes.
Agente de ingeniería inversa: este agente utiliza herramientas avanzadas de ingeniería inversa para el análisis y la comparación de los archivos relevantes. Agregará los artefactos que encuentre al contexto general para que los utilicen otros agentes.
Agente de investigación de vulnerabilidades: este agente coordina el análisis recopilando todos los artefactos y otra información que existe en el contexto y generando un informe coherente.
Metodología
Debido a las limitaciones de la ventana contextual y a las alucinaciones, es crucial dar un contexto pertinente y conciso para utilizar los LLM de la forma más eficaz posible, manteniendo una alta precisión en la tarea de aislar los componentes vulnerables del código y reducir a la vez los costes operativos.
Divide y vencerás
Uno de los detalles cruciales de nuestra implementación fue dividir el análisis en varias tareas más pequeñas y centradas, que finalmente operan como agentes:
Recuperar información sobre la CVE para crear un perfil
Descargar las actualizaciones correspondientes y aplicar los parches a los archivos de la versión base
Crear un agente de IA interno de Windows para aislar los archivos relevantes mediante los metadatos de la vulnerabilidad
Crear un agente de IA de ingeniería inversa que pueda:
Desmontar y aplicar símbolos y luego exportarlo para la comparación de binarios
Correlacionar los binarios e identificar los cambios y los flujos de llamadas
Localizar el bloque de código vulnerable
Crear un agente de IA de investigación de vulnerabilidades que itera a través de posibles rutas de vulnerabilidad para hacer una correlación cruzada y encontrar el mejor resultado posible
Una de las principales ventajas de esta división fue que nos permitió utilizar modelos específicos para cada tipo de tarea; OpenAI o4-mini destacó en el enriquecimiento de metadatos de archivos, mientras que OpenAI o3 se utilizó para el análisis en profundidad definitivo del código vulnerable sospechoso.
Seleccionar el modelo adecuado para la tarea supuso una ventaja por partida doble: primero por la precisión y segundo por los costes.
Enriquecimiento del contexto
Los LLM son máquinas que “recuerdan” una gran cantidad de información. Al invocar al LLM con una petición de datos, se ajustará para proporcionar la información más relevante dentro del contexto de la petición de datos.
Cada trocito de información que podamos proporcionar al LLM sobre la vulnerabilidad parcheada ayudará a generar una respuesta más precisa y a aumentar las posibilidades de localizar el código vulnerable. Sin embargo, la información ambigua sobre la vulnerabilidad dará lugar a resultados deficientes, si los hubiera.
Enriquecer el contexto con los metadatos de la vulnerabilidad durante el análisis resultó crucial. Para lograr ese enriquecimiento, proporcionamos al LLM descripciones de KB, descripciones de archivos de sistema y datos de comparaciones de binarios. Este enfoque nos permitió reducir el número de cambios que necesitamos analizar y, por lo tanto, la longitud del contexto y el número de iteraciones con el LLM.
Resultados
Para evaluar nuestro marco, inspeccionamos la capacidad del modelo para identificar correctamente lo siguiente:
El archivo ejecutable vulnerable correspondiente a la CVE
La función vulnerable dentro del ejecutable
La causa raíz de la vulnerabilidad y explicarla correctamente
Sobre la base de estos parámetros, analizamos las tres últimas versiones de Patch Tuesday para Windows 11 24H2. Después de ejecutar nuestra herramienta y generar un informe automatizado, inspeccionamos manualmente los resultados seleccionados y determinamos la precisión de la respuesta del modelo final.
Después de refinar el contexto y ajustar los distintos modelos para las diferentes tareas, finalmente logramos los siguientes resultados:
Se identificó el ejecutable correcto al que se aplicó el parche para la CVE en cuestión el 88,6 % de las veces
Se encontró la función vulnerable correcta el 83,9 % de las veces
Se averiguó la causa raíz correcta de la vulnerabilidad el 71,4 % de las veces
Si excluimos los fallos de generación de informes causados por un contexto insuficiente, como los bloqueos de la herramienta de análisis estático o la incapacidad de aplicar un parche delta, podemos estimar la tasa de éxito del modelo cuando se le asigna el bloque de código correcto. En tal caso, el índice de éxito del LLM es de aproximadamente el 96 % cuando se proporciona el bloque de código correcto en el contexto (Figura 2).
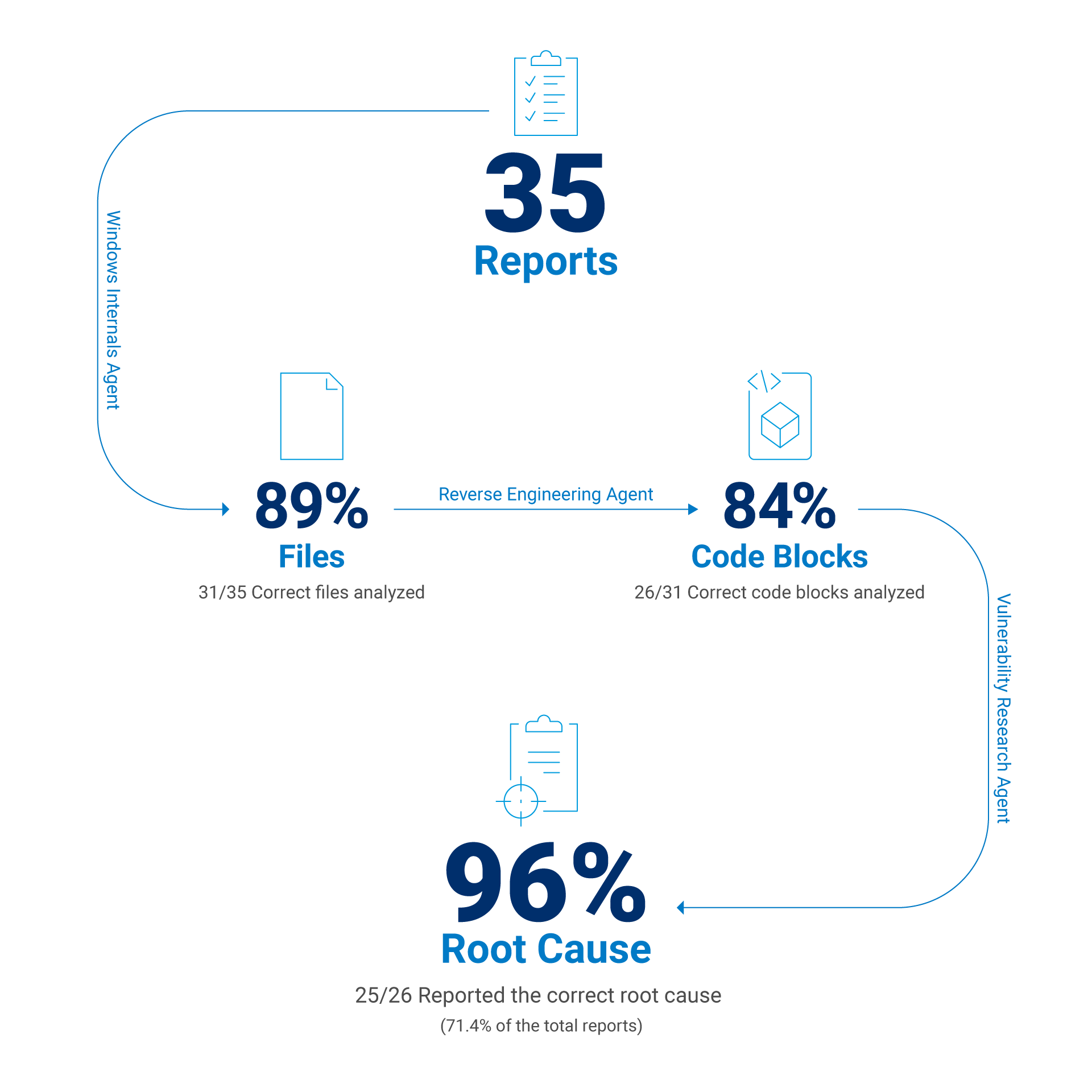 Fig. 2: Resultados de la evaluación de informes seleccionados sobre CVE
Fig. 2: Resultados de la evaluación de informes seleccionados sobre CVE
Un informe de CVE, por favor. Mezclado, no agitado.
Como resultado, hemos encontrado varios casos de uso interesantes que nos gustaría compartir e investigar a fondo. Todos los casos de uso tienen la misma estructura de informe:
Detalles de la CVE que crean el informe
El RCA: el núcleo del informe
Fragmento de código del parche, antes y después
La descripción general completa de cómo la vulnerabilidad puede activarse
Una descripción destacada del parche
Vector de ataque que podría explotar la vulnerabilidad
Un impacto claro y detallado de la vulnerabilidad
Además, en la última sección de cada informe se intenta cuestionar la efectividad del parche y revisar una posible alternativa.
Casos reales
En los siguientes cuatro casos reales, analizaremos algunos ejemplos interesantes que resaltan las fortalezas, debilidades y fallos de nuestro marco.
Caso n.º 1: Montaje y rotura
Una de las vulnerabilidades que analizamos fue la CVE-2025-24991, un error de “La lectura fuera de límites en NTFS de Windows permite a un atacante autorizado revelar información localmente”, según el centro de respuestas de seguridad de Microsoft (MSRC). Otra información que proviene de las preguntas frecuentes indica: “Un atacante puede engañar a un usuario local de un sistema vulnerable para que monte un VHD especialmente diseñado que activaría la vulnerabilidad”.
Ahora, la vulnerabilidad está claramente relacionada con el componente NTFS, que puede implicar definitivamente la participación del ntfs.sys.
Otra pista es el hecho de que la vulnerabilidad se activa por un archivo VHD de montaje. El análisis manual del parche probablemente nos llevaría horas, en el mejor de los casos, pero el uso de la herramienta PatchDiff-AI lo reduce a unos minutos. Esto se amplifica aún más por el hecho de que nuestra herramienta funciona igual de bien cuando no hay un camino obvio para identificar la causa raíz, como fue aquí el caso.
En este caso, el sistema afirma haber encontrado la causa raíz en los 17 cambios más relevantes realizados en el archivo en la actualización KB5053598. El informe completo se puede encontrar en nuestro repositorio de GitHub. Continuamos con nuestro proceso de evaluación.
En primer lugar, nuestra herramienta genera el componente relevante, que es de hecho ntfs.sys, y la función relevante ReadRestartTable(). También genera una breve explicación sobre aquello para lo que se ha diseñado la lógica (Figura 3).
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().Después, tenemos la clase de vulnerabilidad correlacionada con el índice CWE, que en este caso es la CWE-125: lectura fuera de límites. Nos ayudará a entender qué vulnerabilidad buscaba el LLM cuando creó este informe.
La Figura 4 es el resultado real del RCA de nuestra herramienta. Describe claramente lo que salió mal y señala el problema con precisión.
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.La inspección de estos hallazgos utilizando IDA y BinDiff revela que es el lugar correcto. Y sabemos que, dado que Microsoft utiliza indicadores de función para rechazar la corrección de la vulnerabilidad, se puede revertir en caso de comportamiento inesperado (Figura 5).
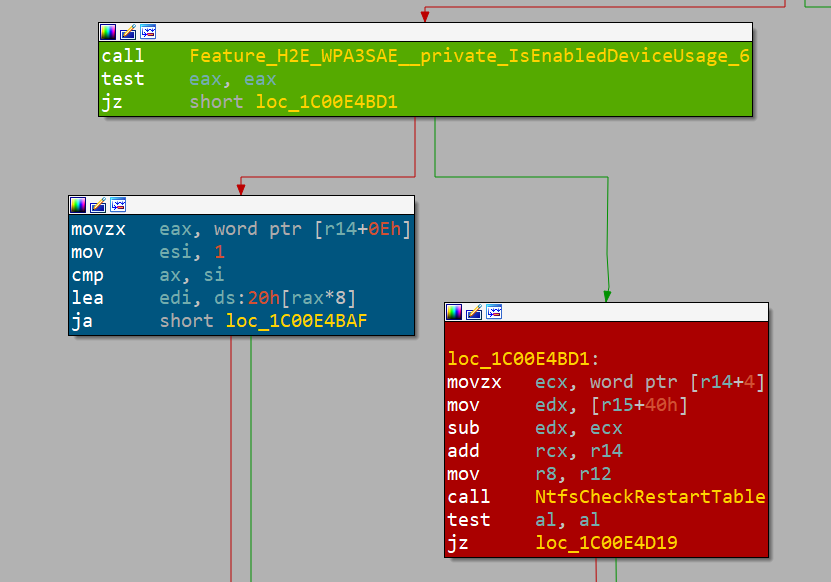 Fig. 5: Feature flag de Microsoft (bloque verde), ruta corregida (bloque azul) y ruta vulnerable (bloque rojo)
Fig. 5: Feature flag de Microsoft (bloque verde), ruta corregida (bloque azul) y ruta vulnerable (bloque rojo)
En el informe, podemos encontrar los fragmentos de código de la parte vulnerable descompilada de la función y revisar el código vulnerable (Figura 6).
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```Uno de los aspectos más destacados del informe es la sección de activación completa. En esta sección, el LLM sugiere posibles medidas que se deben tomar para activar la vulnerabilidad, cuando sea aplicable, hasta presentar detalles prácticos de explotación (Figura 7).
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.Cuando se combina con las indicaciones de seguimiento, nuestra herramienta analiza más el código descompilado y revela significativamente más información e incluso puede sugerir una prueba de concepto (PoC) mínima.
Otra información útil se puede encontrar en las secciones de vectores de ataque, que proporcionan una visión de alto nivel de la explotación de vulnerabilidades. Proporciona una idea del alcance de la vulnerabilidad y de lo que un atacante necesita para explotarla (Figura 8).
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.Las secciones restantes proporcionan una descripción más general del parche en sí y su impacto en la seguridad del sistema. Sin embargo, en la última sección, pedimos al LLM que intentara poner a prueba el parche y ver si había una posible ventaja rápida al identificar otra vulnerabilidad dentro de la corrección. En este caso, evaluó que el parche es muy completo: “Todas las rutas de error se presentan ahora antes de cualquier posible acceso fuera de rango.”
Caso n.º 2: Cuando las estrellas se alinean
Es valioso, y a menudo suficiente para los equipos centrados en la detección o mitigación, evaluar el informe con respecto a la base de datos IDA generada automáticamente y a la salida BinDiff. Sin embargo, nuestro enfoque va más allá y puede resultar útil también con fines ofensivos, ya que, en algunos casos, el sistema puede ir más allá del análisis y producir realmente una explotación que funcione.
Por ejemplo, la CVE-2025-32713, una vulnerabilidad que se corrigió en la actualización de junio de 2025 (KB5060842), se describió como: “El desbordamiento de búfer basado en heap en el controlador del sistema de archivos de registro común de Windows permite a un atacante autorizado elevar privilegios localmente.” En aproximadamente dos minutos, nuestra herramienta generó un informe que rastreó el problema hasta CClfsLogFcbPhysical::ReadLogBlock().
En este punto, hay dos maneras de abordar el desafío que presenta el ataque.
Revertir manualmente la función y sus elementos de llamada hasta la llamada de modo de usuario
Dejar que el LLM lo haga por nosotros y elabore un PoC de forma autónoma
Sin embargo, como suele ocurrir, existe una tercera opción: el enfoque híbrido. Pedir al LLM que realice el trabajo pesado de ingeniería inversa mientras determina los flujos de código indirectos y resuelve las conexiones complejas entre las partes lógicas del binario. Esto permitirá que el LLM obtenga mejores resultados.
Con esta práctica, logramos un ataque de pantalla azul de la muerte (BSOD) en tan solo unas horas (Figura 9).
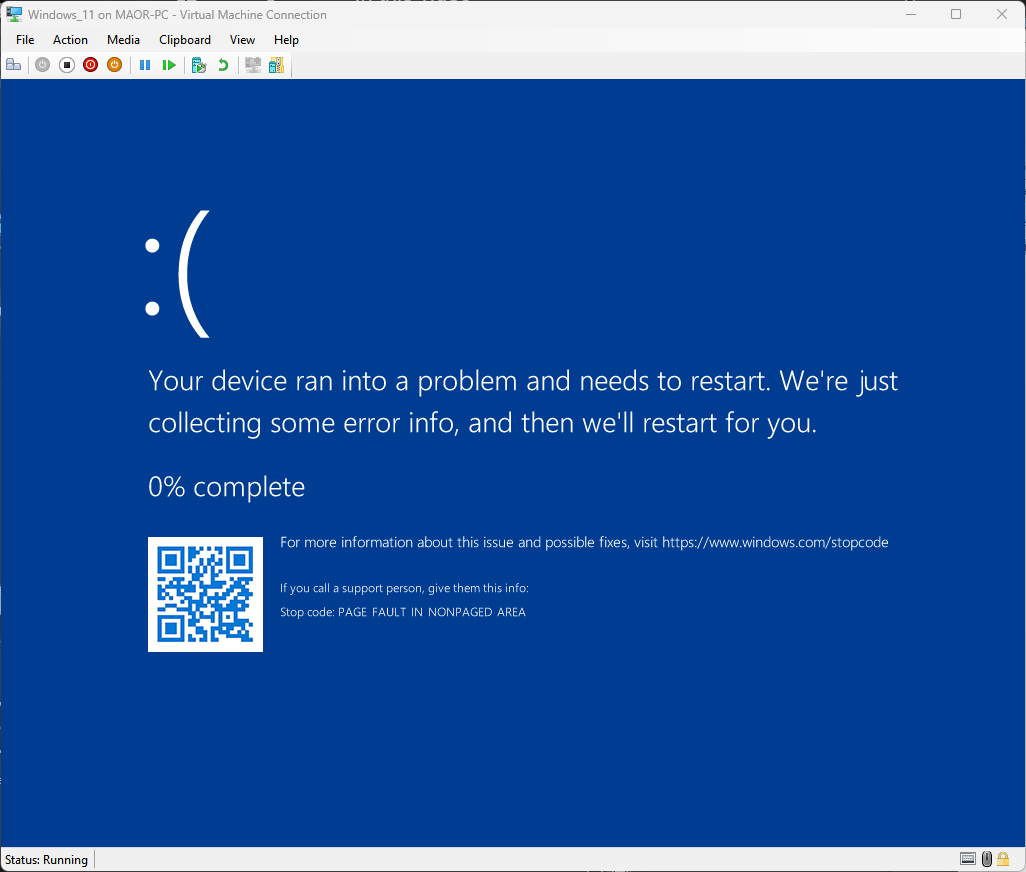 Fig. 9: Pantalla azul de la muerte (BSOD) durante la ejecución de la prueba de concepto (PoC) de CVE-2025-32713
Fig. 9: Pantalla azul de la muerte (BSOD) durante la ejecución de la prueba de concepto (PoC) de CVE-2025-32713
El proceso de comprensión del flujo de activadores de la vulnerabilidad comenzó con la evaluación del código vulnerable sugerido tal y como se describe en la sección del RCA. Una vez que nos dimos cuenta de que el parche intenta corregir un defecto de seguridad, analizamos el flujo de llamadas hasta el control de entrada/salida (IOCTL) 0x80076832.
Al buscar los homólogos del modo de usuario, encontramos dos candidatos, ya que clfsw32.dll exporta la función ReadLogRecord con una ruta de acceso directa para llamar a este IOCTL (Figura 10).
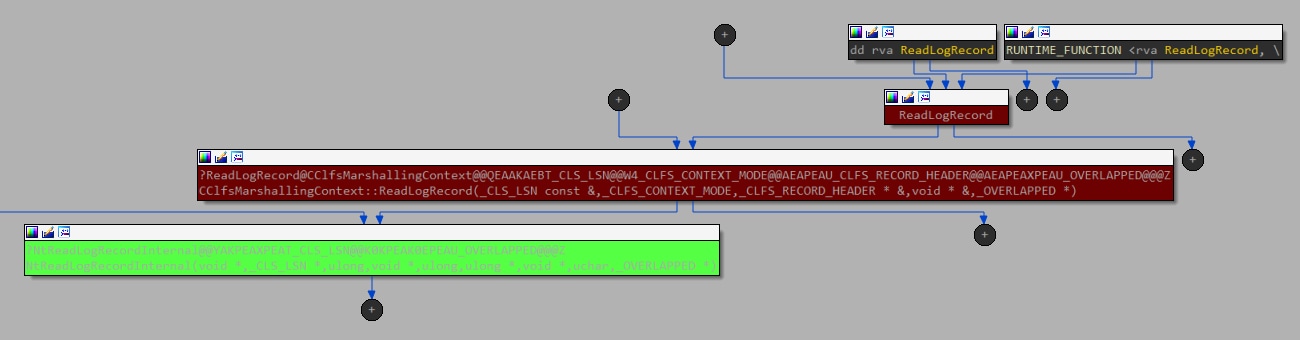 Fig. 10: Gráfico del flujo de llamadas, comenzando con un método exportado desde el modo de usuario hasta llegar al controlador del kernel (utilizando la llamada IOCTL)
Fig. 10: Gráfico del flujo de llamadas, comenzando con un método exportado desde el modo de usuario hasta llegar al controlador del kernel (utilizando la llamada IOCTL)
En cada paso, evaluamos cómo el LLM puede ayudar a revertir y analizar la lógica, teniendo en cuenta que ha sido entrenado en partes de este conocimiento. La Figura 11 muestra cómo podría resolver el requisito de condición para v4, que es el tamaño del búfer que proporcionamos.
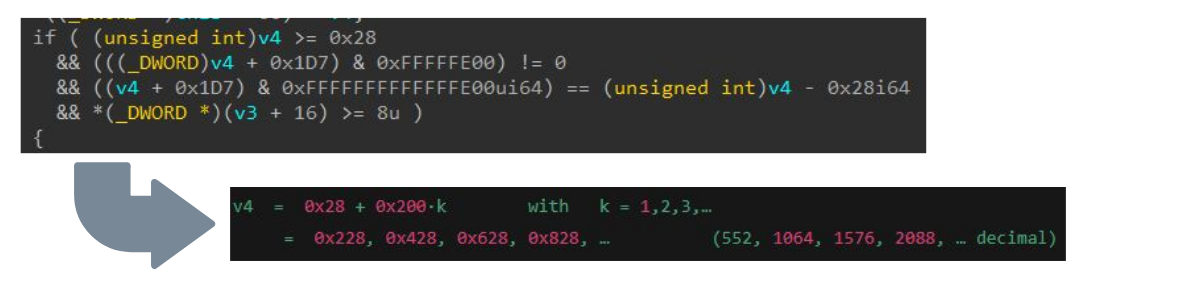 Fig. 11: Uso de un LLM para analizar una comprobación de validación
Fig. 11: Uso de un LLM para analizar una comprobación de validación
Aunque hemos sido testigos de algunas observaciones excelentes que el LLM pudo encontrar, hubo algunos casos en los que los resultados fueron engañosos. Volviendo a la CVE-2025-32713, en una de sus respuestas, nuestro informe contenía la cita que se muestra en la Figura 12.
“crafts the log header so that the page size (v48) exceeds the supplied buffer”Esta respuesta fue bastante confusa y, en última instancia, nos alejó de entender cómo activar el código vulnerable. De hecho, nos llevó a una ruta de investigación completamente irrelevante (intentamos manipular la estructura del archivo .blf que ya tenía mitigaciones). Posteriormente creamos discos virtuales con bytes físicos y lógicos variables por sector y analizamos su comportamiento mediante depuración.
Es justo decir que el LLM gestionó la mayor parte del trabajo, pero requirió la estrecha supervisión de un investigador experimentado. Los LLM son una herramienta para ayudar a los seres humanos, siempre y cuando la asistencia se proporcione correctamente.
En ocasiones, el modelo puede desviarse hacia direcciones improductivas, y la orientación humana era esencial para mantenerlo en el buen camino. Dicho esto, los resultados hablan por sí solos: el LLM identificó correctamente el código vulnerable, rastreó con precisión el flujo de llamadas y explicó cómo la asignación defectuosa de v27 condujo al desbordamiento en CcCopyRead().
Caso n.º 3: Una aguja en un pajar
Hay casos en los que es necesario tomar la salida del LLM con precaución. Las alucinaciones no son el único riesgo de los LLM; esto se reitera repetidamente en las diversas interfaces de LLM (por ejemplo, “ChatGPT puede cometer errores. Compruebe la información importante”.)
Aquí se aplica la misma precaución, aunque el sistema intenta validar su entrada y salida, y examinar varias rutas para identificar la causa raíz. Hay momentos en los que es casi imposible, ya que las condiciones son demasiado amplias y ambiguas.
Tomemos la CVE-2025-29974 de la actualización de mayo de KB5058411. La página de información de MSRC acerca de la vulnerabilidad indica “El subdesbordamiento de enteros (wrap o wraparound) en el kernel de Windows permite que un atacante no autorizado revele información a través de una red adyacente”, lo cual puede resultar algo opaco.
A continuación, vemos que la página MSRC menciona que el atacante debe estar cerca; es decir, el atacante debe estar dentro del alcance para recibir transmisiones de radio. Se trata claramente de la exfiltración de información a través del aire. Sin embargo, lo que no queda claro es cómo ni a través de qué hardware. Esta falta de contexto reduce las posibilidades de obtener un informe válido, o ni siquiera eso.
Con respecto a la CVE-2025-29974, ejecutamos nuestra herramienta y recibimos un informe sobre dos funciones sin nombre: sub_1408E6D3C y sub_1408FAD58. Nos referiremos a ellas como primaria() y secundaria(), por comodidad. La Figura 13 es una vista BinDiff de esas funciones, y es fácil ver que son bastante diferentes… demasiado diferentes, si me preguntan.
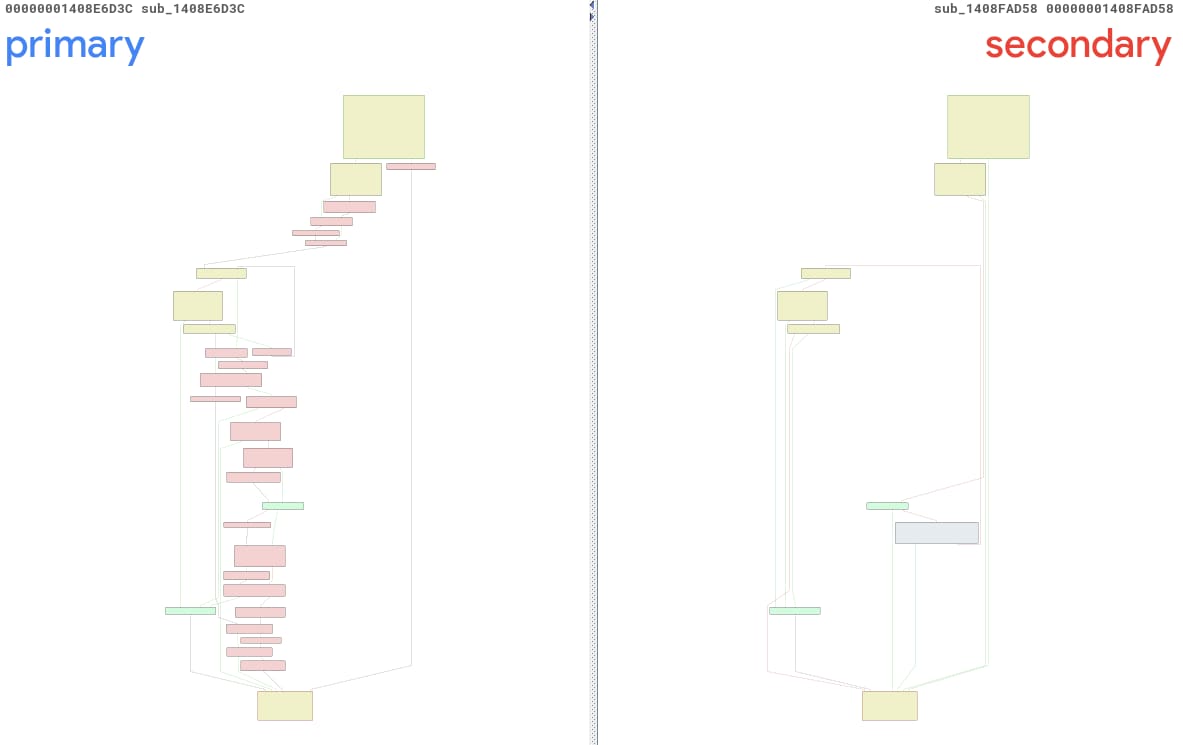 Fig. 13: Vista de BinDiff de los cambios creada automáticamente mediante PatchDiff-AI
Fig. 13: Vista de BinDiff de los cambios creada automáticamente mediante PatchDiff-AI
Tras un examen más detallado, podemos identificar la función primaria correcta como sub_1408E7738, un método completamente diferente, ubicado en una dirección distinta. El motivo principal de esta confusión es el hecho de que el ntoskrnl.exe se ha modificado en gran medida mediante esta actualización. Se modificaron 3791 funciones, lo que provocó que la probabilidad de encontrar los pares anteriores y posteriores correctos disminuyera drásticamente.
El nivel de confianza proporcionado junto con el informe para este caso, fue de 0,2, lo que indica una confianza del 20 % de que el informe encuentre la vulnerabilidad correcta. Este nivel de confianza, junto con el elevado número de modificaciones de bloques de código, se corresponde con los resultados deficientes.
Caso n.º 4: Demasiado vulnerable
Hay casos en los que el componente tiene varias vulnerabilidades que se solucionan con la actualización. Esto no es raro, ya que un único defecto lógico puede contener una cadena de vulnerabilidades con diferentes clases.
Si echamos un vistazo a la actualización KB5055523 (abril de 2025), podemos encontrar un conjunto de vulnerabilidades denominadas CVE-2025-24058, CVE-2025-24060, CVE-2025-24062, CVE-2025-24073 y CVE-2025-24074 (Figura 14). Todas ellas están relacionadas con el Desktop Window Manager (DWM) y todas son el resultado de “CWE-20: validación de entrada incorrecta, lo que las hace indistinguibles y ambiguas para el modelo.
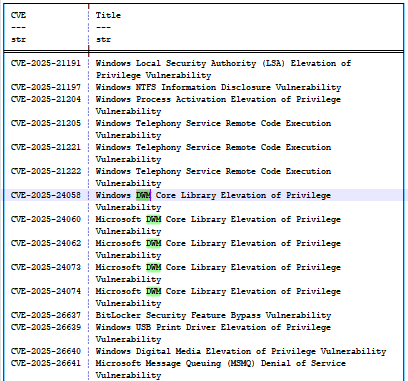 Fig. 14: Lista parcial de los errores de la actualización de abril de 2025
Fig. 14: Lista parcial de los errores de la actualización de abril de 2025
El uso de LLM trae compensaciones. El factor común a todas ellas es el del coste. El LLM intentará completar la tarea en una iteración, incluso si el contexto requerido no está en consonancia. Para obtener resultados más precisos, debemos evaluar los resultados mediante la heurística y refinar el contexto para que pueda generar una mejor mutación del mismo.
Utilizamos los informes de los errores de actualización de abril de 2025 para evaluar el resultado de dicho caso de uso. Al comparar la causa raíz y la información adicional, pudimos entender cómo las múltiples vulnerabilidades pueden afectar al LLM a través de su análisis (Tabla).
CVE | Funciones defectuosas principales | Clase de error | Causa raíz |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | Daños en la memoria basados en heap causados por una validación de entrada incorrecta / desbordamiento de enteros durante el crecimiento de la matriz dinámica (CWE-20, lleva a CWE-787). | El mismo wrap de enteros PreSubgraph activa el desbordamiento de búfer de información de oclusión |
CVE-2025-24073 | COcclusionContext::PreSubgraph | Desbordamiento de búfer basado en heap/desbordamiento de enteros debido a un incorrecta validación de entrada (CWE-20, provoca daños en la memoria) | El mismo wrap de enteros PreSubgraph activa el desbordamiento de búfer de información de oclusión |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | Validación de entrada incorrecta o límites que provoca una escritura de heap fuera de los límites | El mismo wrap de enteros PreSubgraph activa el desbordamiento de búfer de información de oclusión y otro desbordamiento |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | Use-after-free o confusión de tipo resultante de pasar un puntero de objeto liberado como puntero this implícito (CWE-416, CWE-843) | Se liberó el puntero CD3DDevice y se reutilizó como CDeviceManager this |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | Búfer basado en heap procedente de una validación de entrada incorrecta de longitudes de listas proporcionadas por funciones de llamada (CWE-20, lleva a CWE-122) | Desbordamiento de heap al usar CollectOverlayCandidates |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | Truncamiento del puntero o validación de entrada que lleva a la use-after- free o elevación de privilegio (CWE-20, relacionado con CWE-704) | Argumentos ampliados a __int64; IsOverlayCandidateCollectionEnabled() añadido |
Varias vulnerabilidades y su RCA determinados a través del LLM
La tabla es simplemente un reflejo del contenido de los informes. La evaluación de los errores de actualización de abril de 2025 revela la duplicación de CVE-2025-24074, CVE-2025-24073 y CVE-2025-24060. Las tres hacen referencia a las mismas funciones con pequeños cambios o añadidos.
La CVE-2025-24058 (dwmcore.dll) parece solaparse con la consideración de la CVE-2025-24060 de ComputeOverlayConfiguration. CVE-2025-24058 (dwmcorei.dll) y CVE-2025-24062, sin embargo, parecen abordar causas raíz completamente diferentes.
Puesto que el LLM no es un sistema determinista, la salida puede variar incluso con una entrada idéntica. Podemos observar cómo los cambios en el contexto de entrada, no importa lo leves que sean, pueden afectar al resultado del LLM y dar lugar a dos informes diferentes.
La etiqueta de precio
PatchDiff-AI se basa en una arquitectura multiagente supervisada, con diferentes modelos de LLM, para reducir los costes y mantener una alta precisión. El desglose de costes de generar un informe usando modelos OpenAI tiene como resultado un coste máximo de 1,43 USD.
En la práctica, hemos generado 131 informes a partir de las actualizaciones de marzo, abril y mayo, filtrados únicamente para Windows 11 24H2 x64. El coste promedio fue de aproximadamente 0,14 USD por informe. Si se tiene en cuenta cuántas vulnerabilidades se están atajando por día (si no por horas), estos costes pueden ser significativos si se escalan.
Cuando se habilitan funciones totalmente autónomas, como el perfeccionamiento ampliado de los componentes internos de Windows y los agentes de investigación de vulnerabilidades, se puede limitar el cálculo del precio; sin embargo, no puede tener un valor medio debido a la naturaleza no determinista del sistema.
Conclusión
El futuro del uso de la IA, y específicamente de los LLM, en el ámbito de la ciberseguridad es brillante. Los LLM pueden transformar fácilmente un proceso muy complicado, pero metodológico, en un flujo de trabajo sencillo y pueden integrarse en los flujos de producción de varios equipos de seguridad.
Nuestra investigación demuestra que un RCA de vulnerabilidades totalmente automatizado no solo es posible, sino también práctico, con una precisión significativa y un coste razonable.
Al fragmentar el problema en microtareas y ajustarlo a una arquitectura multiagente especializada que combina el razonamiento interno de Windows, los flujos de trabajo de ingeniería inversa y el análisis específico de vulnerabilidades, permitimos a los LLM superar sus limitaciones tradicionales. Esta práctica (y la herramienta complementaria PatchDiff-AI) también se puede generalizar para otros productos y plataformas.
Con nuestro sistema, los equipos de seguridad pueden crear detecciones completas, mitigar eficazmente las vulnerabilidades y crear pruebas de penetración y regresión para sus sistemas. Además, nuestro sistema puede ayudar a acortar el proceso de activación de vulnerabilidades conocidas, lo que permite una mayor investigación y detección de variantes en la base de código compartido vulnerable.

Etiquetas


