
Zusammenfassung
In dieser Studie haben wir untersucht, wie große Sprachmodelle zur Ermittlung der Ursache gepatchter Schwachstellen verwendet werden.
Wir haben ein Multi-Agent-System namens PatchDiff-AI entwickelt, das autonom die Ursache von Patch Tuesday-Schwachstellen analysiert und einen detaillierten Bericht erstellt.
Diese Art von Analyse kann Sicherheitsteams dabei unterstützen, Schwachstellen nahezu sofort zu analysieren, sei es zu defensiven oder angriffsorientierten Zwecken.
Durch den Einsatz mehrerer Strategien konnten wir unser System optimieren und eine Erfolgsrate von mehr als 80 % bei der vollautomatischen Berichterstellung erreichen, einschließlich Angriffsvektoranalyse und Prozess-Auslösung.
Patch Tuesday → Exploit Wednesday
Der regelmäßige Update-Zyklus von Microsoft konzentriert sich auf Patch Tuesday, den zweiten Dienstag jedes Monats, wenn das Unternehmen eine umfassende Liste von CVEs und deren entsprechenden Korrekturen veröffentlicht. Diese Fehlerbehebungen werden als MSU-Dateien (Microsoft Standalone Update) geliefert. Dies ist ein Paketformat, das Aktualisierungen durch Patching oder Ersetzen von Kernsystemdateien anwendet.
Auf Patch Tuesday folgt oft der sogenannte Exploit Wednesday, da Angreifer versuchen, möglichst schnell die Schwachstellen zu identifizieren, für die Microsoft einen Patch erstellt hat. Durch einen Vergleich der aktualisierten Binärdateien (Binary Diffing) können Angreifer die zugrunde liegenden Sicherheitsprobleme schnell erkennen und versuchen, sie auszunutzen, bevor Unternehmen die Patches flächendeckend bereitgestellt haben.
Die Verteidiger wollen ihrerseits diese Patches schnell analysieren, um die Ursachen der Schwachstellen zu verstehen und entsprechende Erkennungs- und Abwehrmaßnahmen zu entwickeln.
Der aktuelle Situation beim Patch-Diffing
Heutzutage ist Patch-Diffing ein zeitaufwändiger Prozess. Um den anfälligen Code erfolgreich zu identifizieren, müsste ein Forscher:
Die Datei identifizieren, die die Schwachstelle enthalten soll
Ein binäres Diff durchführen, um die Änderungen zu identifizieren.
Sicherheitsrelevante Änderungen von anderen routinemäßigen Code-Updates isolieren
Die verdächtigen Teile analysieren und die Ursache ermitteln
Die Anrufflüsse dynamisch untersuchen, um potenzielle Auslöserwege zu finden
Überprüfen, ob der Patch-Fix erfolgreich abgeschlossen wurde.
Diese Schritte können manchmal Wochen in Anspruch nehmen und dieses Problem wird durch die schiere Menge an Schwachstellen, die jeden Monat gleichzeitig veröffentlicht werden, noch verstärkt.
Wir wollten einen besseren Weg finden, der es Forschern ermöglicht, gepatchte Schwachstellen schnell zu analysieren und die ihnen zugrunde liegenden Ursachen zu verstehen.
Verwendung von LLMs für Patch-Diff-Analysen
Große Sprachmodelle (Large Language Models, LLMs) können auf der Grundlage ihrer trainierten Daten und der Nutzereingaben angemessene und genaue Informationen statistisch generieren. Es gibt jedoch einige Einschränkungen, darunter ein begrenztes Kontextfenster (das sich auf die Menge der verarbeitbaren Daten und die Betriebskosten auswirkt) und die berüchtigte Modell-Halluzination.
In den letzten Jahren wurden zahlreiche Veröffentlichungen zum Beitrag von LLMs zur Schwachstellenbewertung im Sicherheitssektor veröffentlicht. Derzeit haben LLMs noch Schwierigkeiten bei der Analyse von Closed-Source-Software. Sie liefern deutlich bessere Ergebnisse, wenn es Open-Source- und Web-Schwachstellen geht, die das Vorhandensein von menschenlesbarem Code gemeinsam haben.
Aardvark von OpenAI und Claude Code Security Reviewer sind weiterhin an den lesbaren Quellcode gebunden. Auf der anderen Seite gibt es Big Sleep von Google Project Zero, mit dem Zero-Day-Schwachstellen entdeckt werden sollen. Keiner der beiden Ansätze analysiert die Binärdatei als geschlossene Quelle.
Wir stellen vor: PatchDiff-AI
Wir verfolgen mit unserer Forschung einen anderen Ansatz, indem wir LLMs für die Ursachenanalyse (Root Cause Analysis, RCA) von Sicherheitspatches verwenden. Unsere inzwischen offenkundig validierte Idee war: Der zusätzliche, durch das binäre „Diffing“ bereitgestellte Kontext, kann die Fähigkeit des LLMs, komplexen Low-Level-Code zu verstehen, erheblich verbessern.
Für diese Aufgabe haben wir ein Multi-Agent-System entwickelt, das die Analyse von Microsoft Knowledge Base-Aktualisierungen (KB) für eine spezifische Plattform automatisiert (Abbildung 1). Wir nennen es PatchDiff-AI.
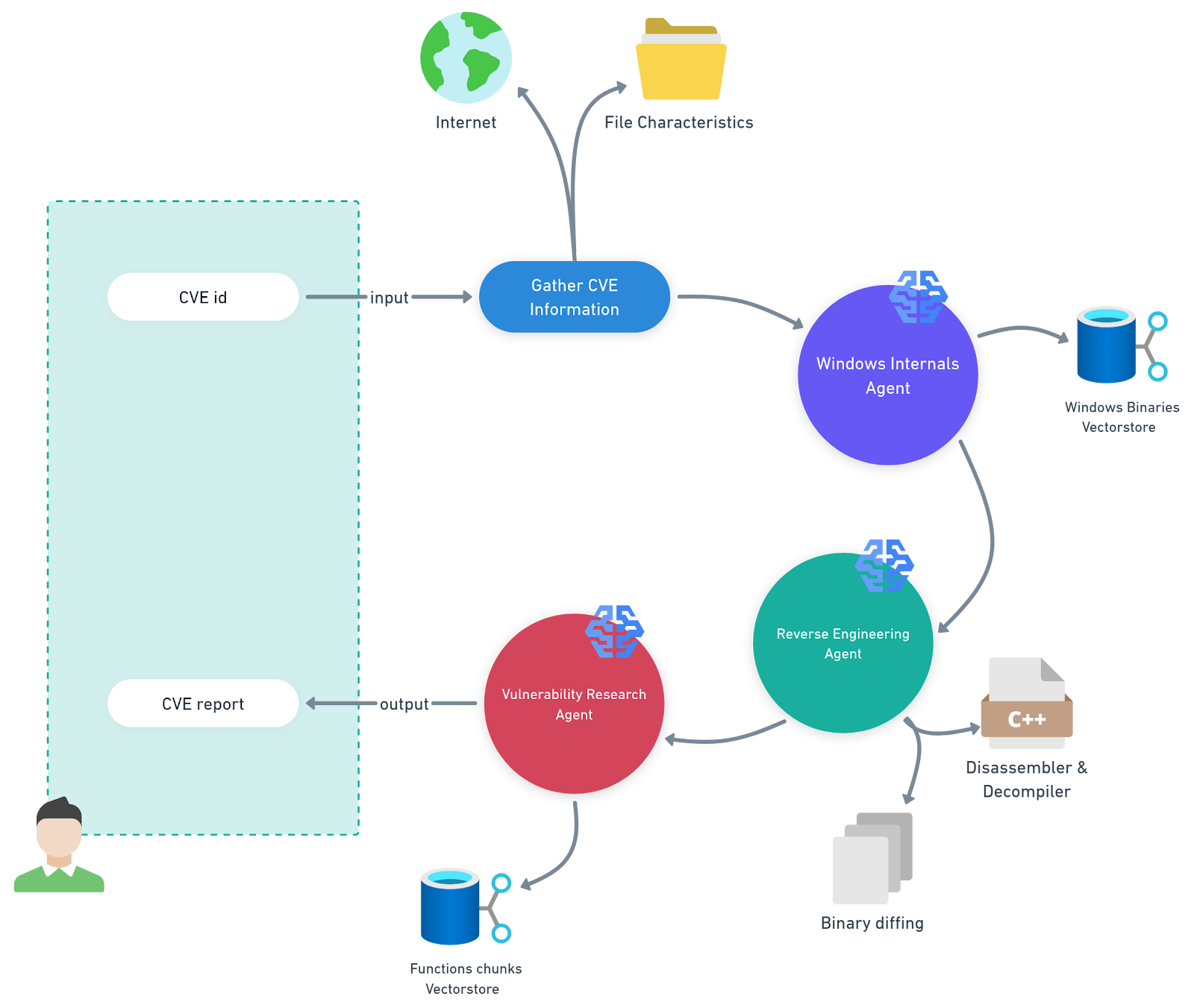 Abb. 1: Illustration unseres Multi-Agenten-Systems, PatchDiff-AI
Abb. 1: Illustration unseres Multi-Agenten-Systems, PatchDiff-AI
PatchDiff-AI-Definitionen
Agent für Windows-Interna – Dieser Agent verwendet eine RAG-Pipeline (Retrieval-Augmented Generation), die von einem Vektorspeicher mit Windows-Binärdateien und deren Funktions-Metadaten unterstützt wird. Dadurch kann der Agent den Umfang der Analyse erheblich einschränken und sich auf die wichtigsten Komponenten konzentrieren.
Reverse-Engineering-Agent – Dieser Agent verwendet erweiterte Reverse Engineering-Tools für die Analyse und das Diffing der relevanten Dateien. Er fügt die gefundenen Artefakte dem Gesamtkontext hinzu, damit andere Agenten diese nutzen können.
Agent für Schwachstellenforschung – Dieser Agent koordiniert die Analysen, indem er alle Artefakte und andere im Kontext vorhandene Informationen erfasst und einen konsistenten Bericht generiert.
Methodik
Aufgrund der Beschränkungen des Kontextfensters und der Halluzination ist es wichtig, relevanten und präzisen Kontext bereitzustellen, um LLMs so effektiv wie möglich zu verwenden und eine hohe Genauigkeit bei der Isolierung anfälliger Code-Komponenten bei gleichzeitiger Senkung der Betriebskosten zu gewährleisten.
Teile und herrsche
Eines der entscheidenden Details bei unserer Implementierung bestand darin, die Analyse in mehrere kleinere und fokussierte Aufgaben zu unterteilen, die schließlich als Agenten fungieren:
Informationen zur CVE abrufen, um ein Profil zu erstellen
Die relevanten Updates herunterladen und wenden die Deltas auf die Basisversionsdateien anwenden
Einen KI-Agenten für Windows-Interna erstellen, um die relevanten Dateien mithilfe der Schwachstellenmetadaten zu isolieren
Einen Reverse-Engineering-KI-Agenten, der Folgendes kann:
Symbole zerlegen, anwenden und dann für binäres Diffing exportieren
Die Binärdateien korrelieren und die Änderungen sowie Aufrufabläufe identifizieren
Den anfälligen Codeblock lokalisieren
Einen KI-Agenten für Schwachstellenforschung erstellen, der mögliche Schwachstellenpfade iterativ durchläuft, um diese zu korrelieren und das bestmögliche Ergebnis zu erzielen
Einer der Hauptvorteile dieser Gruppe war, dass wir damit spezifische Modelle für den jeweiligen Aufgabentyp verwenden konnten. OpenAI o4-mini erwies sich als hervorragend geeignet für die Anreicherung von Dateimetadaten, während OpenAI o3 für die letzte tiefgreifende Analyse des mutmaßlich anfälligen Codes verwendet wurde.
Die Auswahl des richtigen Modells für die Aufgabe war doppelt von Vorteil – erstens für die Genauigkeit und zweitens für die Kosten.
Kontextanreicherung
LLMs sind Maschinen, die sich eine große Menge an Informationen „merken“. Wenn Sie das LLM mit einem Prompt aufrufen, wird es so angepasst, dass es die relevantesten Informationen im Kontext des Prompts liefert.
Jede noch so kleine Information, die wir dem LLM über die gepatchte Schwachstelle zur Verfügung stellen können, trägt dazu bei, eine präzisere Reaktion zu generieren, und erhöht die Wahrscheinlichkeit, den anfälligen Code zu finden. Sind die Informationen über die Schwachstelle mehrdeutig, leidet die Qualität der Ergebnisse, sofern es überhaupt welche gibt.
Die Anreicherung des Kontexts mit den Metadaten der Schwachstelle während der Analyse erwies sich als überaus wichtig. Um diese Anreicherung zu erreichen, haben wir dem LLM KB-Beschreibungen, Systemdateibeschreibungen und Binary-Diffing-Daten bereitgestellt. Mit diesem Ansatz konnten wir die Anzahl der zu analysierenden Änderungen und damit die Kontextlänge und die Anzahl der Iterationen mit dem LLM begrenzen.
Ergebnisse
Zur Bewertung unseres Frameworks haben wir geprüft, inwieweit das Modell in der Lage ist, Folgendes korrekt zu bestimmen:
Die anfällige ausführbare Datei, die der CVE entspricht
Die anfällige Funktion innerhalb der ausführbaren Datei
Die Ursache der Schwachstelle und ihre korrekte Erklärung
Basierend auf diesen Parametern haben wir die letzten drei Patch-Tuesday-Releases für Windows 11 24H2 analysiert. Nachdem wir unser Tool ausgeführt und einen automatisierten Bericht erstellt haben, haben wir ausgewählte Ergebnisse manuell geprüft und die Genauigkeit der endgültigen Modellantwort ermittelt.
Nachdem wir den Kontext verfeinert und die verschiedenen Modelle für die verschiedenen Aufgaben angepasst haben, haben wir letztendlich folgende Ergebnisse erzielt:
In 88,6 % der Fälle wurde die korrekte ausführbare Datei identifiziert, die für das betreffende CVE gepatcht wurde
In 83,9 % der Fälle wurde die korrekte Funktion für Schwachstellen gefunden
In 71,4 % der Fälle gelang es, die korrekte Ursache der Schwachstelle zu ermitteln.
Wenn wir Fehler bei der Berichterstellung ausnehmen, die durch unzureichenden Kontext verursacht wurden – zum Beispiel der Absturz des statischen Analysetools oder die nicht mögliche Anwendung eines Delta-Patches –, können wir abschätzen, wie hoch die Erfolgsrate des Modells ist, wenn ihm der richtige Codeblock zugewiesen wird. In einem solchen Fall liegt die LLM-Erfolgsrate bei etwa 96 %, wenn der richtige Codeblock im Kontext angegeben wird (Abbildung 2).
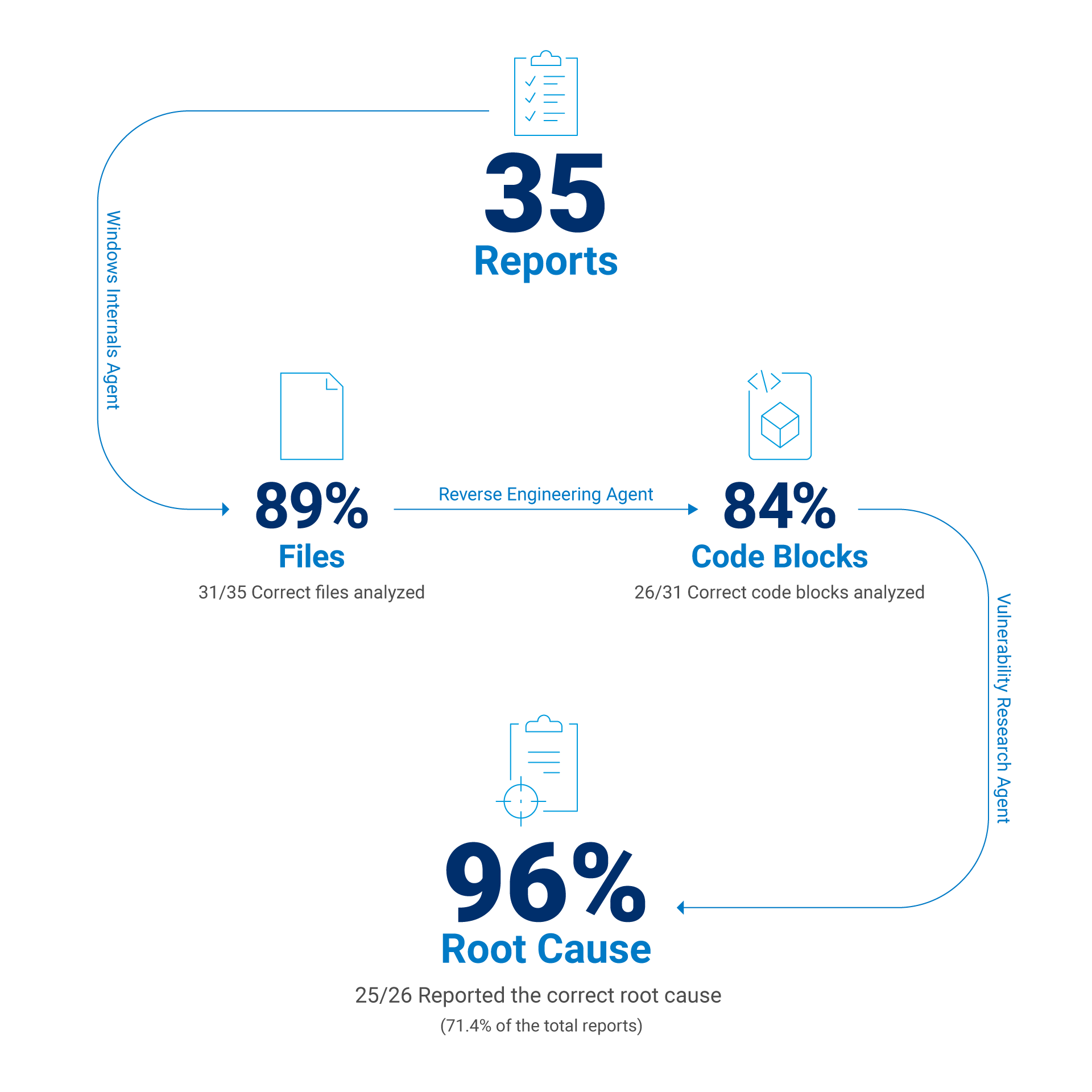 Abb. 2: Evaluationsergebnisse ausgewählter Berichte zu CVEs
Abb. 2: Evaluationsergebnisse ausgewählter Berichte zu CVEs
Der CVE-Bericht und seine Komponenten
Daher sind wir auf mehrere interessante Anwendungsfälle gestoßen, die wir gerne teilen und eingehend untersuchen würden. Jeder Anwendungsfall hat die gleiche Berichtsstruktur:
CVE-Details, die den Bericht konstruieren
Die RCA – das Herzstück des Berichts
Ein Code-Snippet des Patches, vorher und nachher
Die Top-down-Übersicht, wie die Schwachstelle ausgelöst werden kann
Eine hervorgehobene Beschreibung des Patches
Ein Angriffsvektor, der die Schwachstelle ausnutzen könnte
Ein klarer, detaillierter Einblick in die Auswirkungen der Schwachstelle
Darüber hinaus wird im letzten Abschnitt jedes Berichts versucht, die Effektivität des Patches zu testen und eine mögliche Umgehung zu prüfen.
Fallstudien
In den folgenden vier Fallstudien werden wir einige interessante Fälle untersuchen, die zeigen, wo unser Framework gut abschneidet, wo es Probleme hat und wo es komplett versagt.
Fall 1: Mounten und auslösen
Eine der von uns untersuchten Schwachstellen war CVE-2025-24991. Laut Microsoft Security Response Center (MSRC) gilt für diesen Fehler: „Out of Bounds-Lesevorgang in Windows NTFS ermöglicht einem autorisierten Angreifer, lokale Informationen offenzulegen“. Eine weitere Information stammt aus den FAQ, wo es heißt: „Ein Angreifer kann einen lokalen Nutzer auf einem verwundbaren System dazu verleiten, eine speziell präparierte VHD einzubinden, die dann die Schwachstelle auslöst.“
Allerdings steht die Schwachstelle eindeutig im Zusammenhang mit der NTFS-Komponente, was definitiv die Beteiligung von ntfs.sys implizieren kann.
Ein weiterer Hinweis ist die Tatsache, dass die Schwachstelle durch das Mounten einer VHD-Datei ausgelöst wird. Die manuelle Analyse des Patches hätte uns Stunden gekostet, aber mit dem Tool PatchDiff-AI reduzierte sich die Zeit auf wenige Minuten. Dies wird durch die Tatsache noch verstärkt, dass unser Tool genauso funktioniert, wenn es keinen offensichtlichen Weg zur Identifizierung der Ursache gibt, wie dies hier der Fall war.
In diesem Fall behauptet das System, die Ursache innerhalb der 17 wichtigsten Änderungen an der Datei im KB5053598-Update gefunden zu haben. Den vollständigen Bericht finden Sie in unserem GitHub-Repository. Unser Bewertungsprozess folgt.
Zunächst gibt unser Tool die entsprechende Komponente, nämlich ntfs.sys, sowie die relevante Funktion ReadRestartTable() aus. Es liefert auch eine kurze Erklärung darüber, wofür die Logik konzipiert ist (siehe Abbildung 3).
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().Als Nächstes erfolgt eine Korrelierung der Schwachstellenklasse mit dem CWE-Index, der in diesem Fall CWE-125 ist: Out of Bounds-Lesevorgang. So können wir besser verstehen, nach welcher Schwachstelle das LLM bei der Erstellung dieses Berichts sucht.
Abbildung 4 zeigt die tatsächliche Ausgabe des RCA-Verfahrens unseres Tools. Es wird klar dargestellt, was schief gelaufen ist, und das Problem wird präzise aufgezeigt.
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.Die Überprüfung dieser Ergebnisse mit IDA und BinDiff bestätigt, dass es sich tatsächlich um die richtige Stelle handelt. Wir wissen dies, weil Microsoft Feature-Flags verwendet, um die Behebung von Schwachstellen abzulehnen. Auf diese Weise kann sie bei unerwartetem Verhalten rückgängig gemacht werden (Abbildung 5).
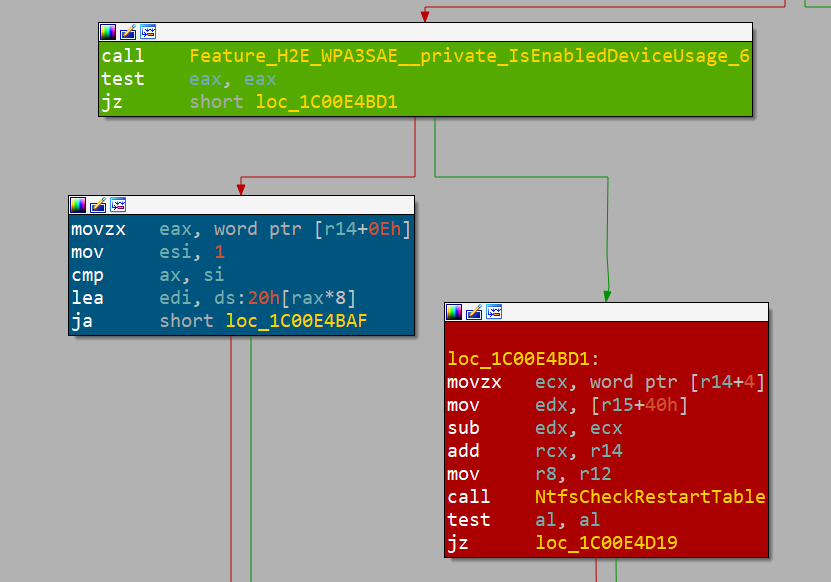 Abb. 5: Microsoft Feature-Flag (grüner Block), korrigierter Pfad (blauer Block) und anfälliger Pfad (roter Block)
Abb. 5: Microsoft Feature-Flag (grüner Block), korrigierter Pfad (blauer Block) und anfälliger Pfad (roter Block)
Im Bericht finden Sie die Code-Snippets des dekomprimierten anfälligen Teils der Funktion und prüfen den anfälligen Code (Abbildung 6).
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```Ein besonders interessanter Teil des Berichts ist der Abschnitt Top-down-Triggering (Auslösung von oben nach unten). In diesem Abschnitt schlägt das LLM mögliche Schritte vor, die gegebenenfalls unternommen werden müssen, um die Schwachstelle auszulösen. Das geht so weit, dass Details zur praktische Ausnutzung geliefert werden (Abbildung 7).
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.In Kombination mit Folge-Prompts analysiert unser Tool den dekompilierten Code weiter, deckt deutlich mehr Informationen auf und kann sogar einen minimalen PoC (Proof of Concept) vorschlagen.
Weitere hilfreiche Einblicke finden Sie in den Abschnitten zu den Angriffsvektoren, die einen umfassenden Überblick über die Ausnutzung von Schwachstellen bieten. Man bekommt dort eine Vorstellung vom Umfang der Schwachstelle und dafür, was ein Angreifer benötigt, um sie zu auszunutzen (Abbildung 8).
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.Die übrigen Abschnitte enthalten eine allgemeine Beschreibung des Patches selbst sowie seiner Sicherheitsauswirkungen auf das System. Im letzten Abschnitt haben wir das LLM jedoch angewiesen, den Patch zu testen und zu prüfen, ob sich ein Quick Win erzielen lässt, indem in der Lösung eine weitere Schwachstelle gefunden wird. In diesem Fall hat es ausgewertet, dass der Patch vollständig ist: „Alle Fehlerpfade lösen nun eine Fehlermeldung aus, bevor es zu einem möglichen Zugriff außerhalb des gültigen Bereichs kommen kann.“
Fall 2: Wenn die Sterne günstig stehen
Für Teams, die sich auf Erkennung oder Abwehr konzentrieren, ist es sinnvoll und oft ausreichend, den Bericht anhand der automatisch generierten IDA-Datenbank und BinDiff-Ausgabe zu bewerten. Unser Ansatz geht jedoch weiter – und kann sich auch für offensivere Zwecke als nützlich erweisen, da das System in manchen Fällen über die Analyse hinausgeht und tatsächlich einen funktionierenden Exploit erzeugt.
So wurde CVE-2025-32713, eine Schwachstelle, die im Update vom Juni 2025 (KB5060842) gepatcht wurde, wie folgt beschrieben: „Heap-basierter Pufferüberlauf im Windows Common Log File System-Treiber ermöglicht einem autorisierten Angreifer, Berechtigungen lokal zu erhöhen.“ In etwa zwei Minuten erstellte unser Tool einen Bericht, der das Problem auf CClfsLogFcbPhysical::ReadLogBlock() zurückverfolgte.
An dieser Stelle gibt es zwei Möglichkeiten, die Ausnutzung zu verhindern.
Die Funktion und deren Aufrufer wird manuell analysiert, bis hin zum Aufruf im Nutzermodus
Man überlässt diese Aufgabe dem LLM, das autonom einen PoC erstellt
Wie so oft gibt es jedoch eine dritte Option: den hybriden Ansatz. Lassen Sie das LLM das Reverse Engineering übernehmen, während Sie die indirekten Codeflüsse bestimmen und die komplexen Beziehungen zwischen den logischen Einheiten der Binärdatei klären. Auf diese Weise kann das LLM bessere Ergebnisse erzielen.
Mit dieser Methode haben wir in nur wenigen Stunden einen BSOD-Exploit (Blue Screen of Death) erreicht (Abbildung 9).
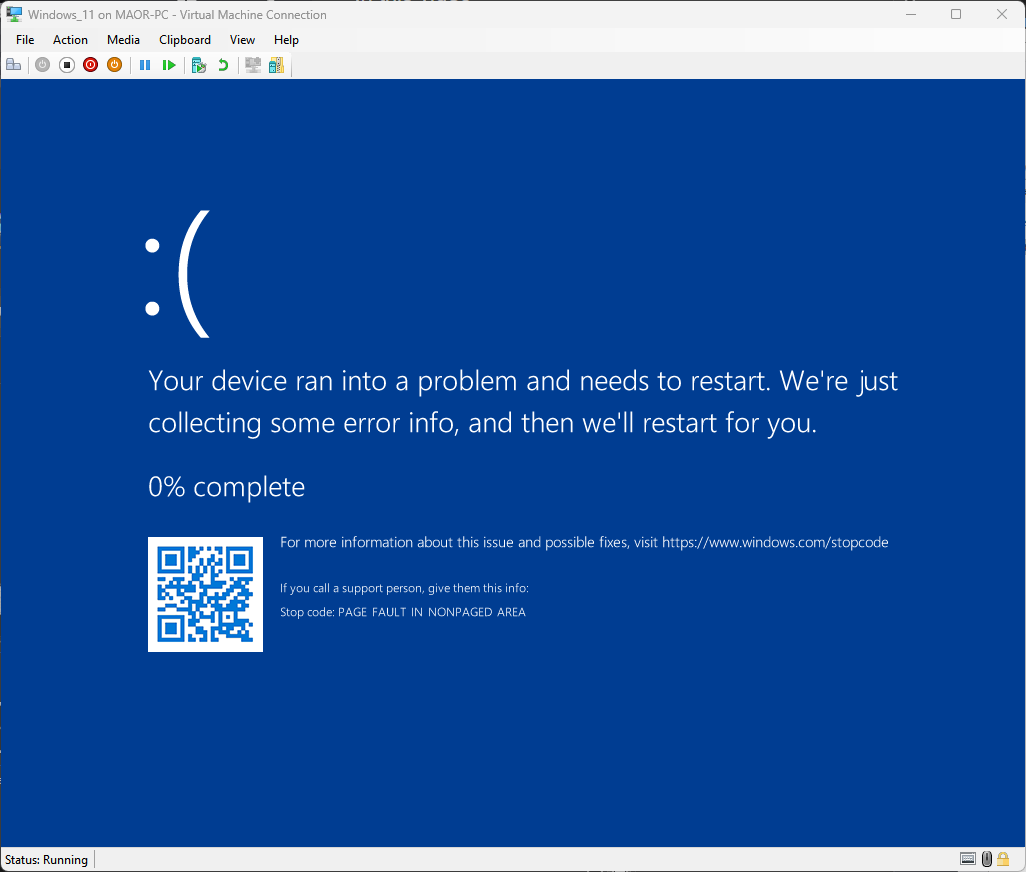 Abb. 9: BSOD während der Ausführung des CVE-2025-32713-PoC
Abb. 9: BSOD während der Ausführung des CVE-2025-32713-PoC
Der Weg zum Verständnis des Schwachstellen-Auslösers begann mit der Auswertung des vorgeschlagenen verwundbaren Codes, wie im RCA-Abschnitt beschrieben. Nachdem wir festgestellt hatten, dass der Patch versucht, einen Sicherheitsfehler zu beheben, haben wir den Aufrufablauf bis zur Eingabe/Ausgabe-Steuerung (IOCTL) 0x80076832 analysiert.
Bei der Suche nach den Gegenstücken im Nutzermodus fanden wir zwei Kandidaten, da clfsw32.dll die Funktion ReadLogRecord mit einem direkten Pfad zum Aufruf dieser IOCTL exportiert (Abbildung 10).
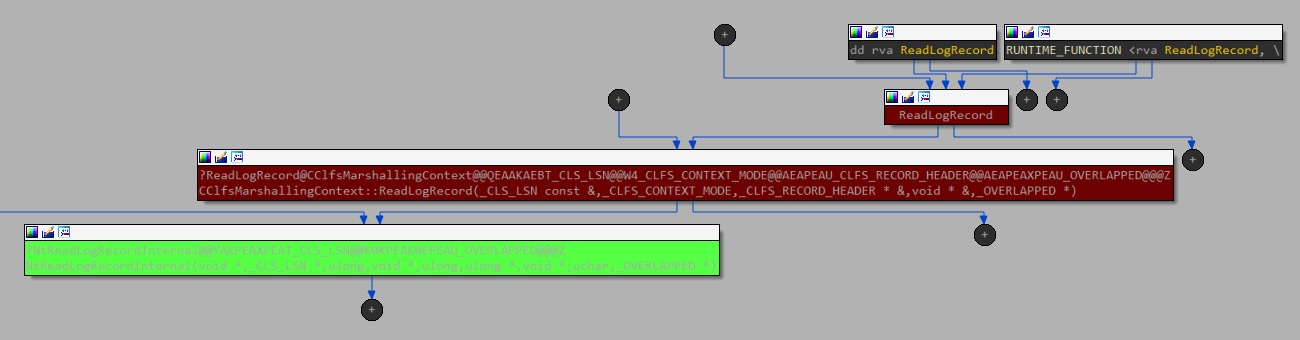 Abb. 10: Aufrufflussgraph (Call Flow Graph), beginnend mit einer exportierten Methode aus dem Benutzermodus bis hinunter zum Kerneltreiber (unter Verwendung des IOCTL-Aufrufs)
Abb. 10: Aufrufflussgraph (Call Flow Graph), beginnend mit einer exportierten Methode aus dem Benutzermodus bis hinunter zum Kerneltreiber (unter Verwendung des IOCTL-Aufrufs)
Bei jedem Schritt bewerteten wir, wie das LLM die Rekonstruktion und Analyse der Logik unterstützen kann, da es ja auf Teilen dieses Wissens trainiert wurde. Abbildung 11 zeigt, wie es die Bedingungsanforderung für v4 lösen konnte, also die Größe des von uns bereitgestellten Puffers.
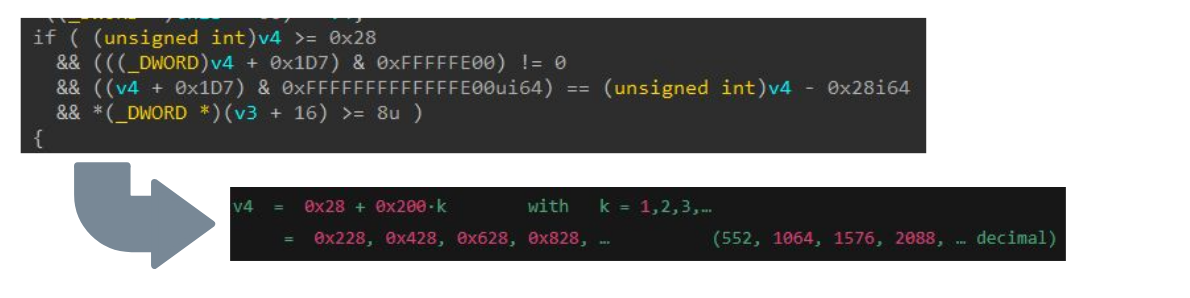 Abb. 11: Einsatz von LLMs zur Analyse einer Validierungsprüfung
Abb. 11: Einsatz von LLMs zur Analyse einer Validierungsprüfung
Obwohl das LLM einige hervorragende Beobachtungen gemacht hat, gab es einige Fälle, in denen die Ergebnisse irreführend waren. In Bezug auf CVE-2025-32713 enthielt unser Bericht in einer seiner Antworten den in Abbildung 12 angegebenen Text.
“crafts the log header so that the page size (v48) exceeds the supplied buffer”Diese Antwort war ziemlich verwirrend und hat uns letztendlich davon abgehalten, zu verstehen, wie der anfällige Code ausgelöst werden kann. Sie führte sie uns auf einen völlig irrelevanten Forschungspfad (wir versuchten, die .blf-Dateistruktur zu manipulieren, für die bereits Abwehrmaßnahmen ergriffen worden waren). Später haben wir virtuelle Laufwerke mit unterschiedlichen physischen und logischen Bytes pro Sektor erstellt und ihr Verhalten durch Debugging analysiert.
Das LLM konnte durchaus den Großteil der Arbeit erledigen, aber es erforderte eine engmaschige Überwachung durch einen erfahrenen Forscher. LLMs sind ein Werkzeug zur Unterstützung von Menschen, sofern diese Unterstützung in korrekter Form bereitgestellt wird.
Das Modell kann gelegentlich in unproduktive Richtungen abgleiten, und die menschliche Anleitung war unerlässlich, um es auf Kurs zu halten. Dennoch sprechen die Ergebnisse für sich: Das LLM hat den anfälligen Code korrekt identifiziert, den Aufrufablauf präzise verfolgt und erklärt, wie die fehlerhafte Zuordnung von v27 zu einem Überlauf in CcCopyRead() führte.
Fall 3: Eine Nadel in einem Heuhaufen
In manchen Fällen ist die LLM-Ausgabe mit Vorsicht zu genießen. Halluzinationen sind nicht das einzige Risiko bei LLMs; Darauf wird in den unterschiedlichen LLM-Schnittstellen immer wieder hingewiesen (z. B. „ChatGPT kann Fehler machen. Überprüfen Sie wichtige Informationen.“)
Hier gilt die gleiche Vorsicht, obwohl das System versucht, die Eingabe und Ausgabe zu validieren und mehrere Pfade zu untersuchen, um die Ursache zu ermitteln. Es gibt Situationen, in denen es fast unmöglich ist, da die Bedingungen zu weit gefasst und zu vage sind.
Nehmen wir CVE-2025-29974 vom Mai-Update KB5058411. Auf der MSRC-Informationsseite über die Sicherheitslücke heißt es: „Integer-Unterlauf (Wrap oder Wraparound) im Windows-Kernel ermöglicht es einem nicht autorisierten Angreifer, über ein benachbartes Netzwerk Informationen offenzulegen.“ Dies ist unter Umständen schwer zu erkennen.
Als Nächstes wird auf der MSRC-Seite erwähnt, dass der Angreifer in der Nähe sein muss, d. h. er muss in Reichweite sein, um Funkübertragungen empfangen zu können. Es geht eindeutig um die Informationsextraktion per Air-Gap. Unklar ist jedoch, wie oder durch welche Hardware. Ein solcher fehlender Kontext verringert die Wahrscheinlichkeit, einen gültigen Bericht oder überhaupt einen Bericht zu erhalten.
Bezüglich CVE-2025-29974 haben wir unser Tool ausgeführt und einen Bericht über zwei unbenannte Funktionen erhalten: Sub_1408E6D3C und Sub_1408FAD58. Wir bezeichnen sie der Einfachheit halber als primary() und secondary(). Abbildung 13 zeigt eine BinDiff-Ansicht dieser Funktionen, und es ist leicht zu erkennen, dass sie ziemlich unterschiedlich sind – viel zu unterschiedlich, wenn Sie mich fragen.
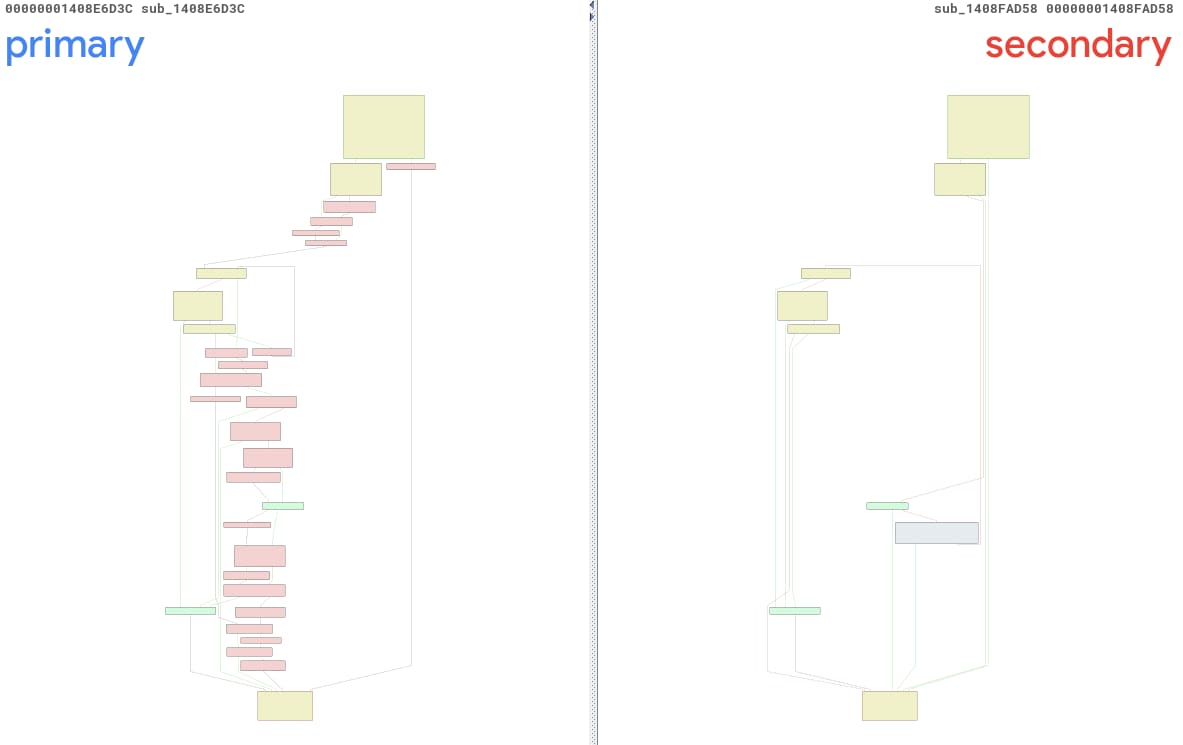 Abb. 13: Automatisch erstellte BinDiff-Ansicht der Änderungen mittels PatchDiff-AI
Abb. 13: Automatisch erstellte BinDiff-Ansicht der Änderungen mittels PatchDiff-AI
Nach näherer Untersuchung können wir die korrekte Primärfunktion als Sub_1408E7738 identifizieren, eine völlig andere Methode, die sich an einer anderen Adresse befindet. Der Hauptgrund für diese Verwechslung ist die Tatsache, dass ntoskrnl.exe durch dieses Update stark verändert wurde. Es wurden 3.791 Funktionen geändert, wodurch die Wahrscheinlichkeit, die richtigen Vorher-nachher-Paare zu finden, drastisch abnahm.
Der Wert für die Vertrauenswürdigkeit, der zusammen mit dem Bericht für diesen Fall angegeben wurde, betrug 0,2, was eine 20%ige Konfidenz dafür anzeigt, dass der Bericht die richtige Schwachstelle gefunden hat. Dieser Konfidenzwert und die hohe Anzahl von Codeblockänderungen entsprechen den schlechten Ergebnissen.
Fall 4: Zu viele Schwachstellen
Es gibt Fälle, in denen die Komponente mehrere Schwachstellen aufweist, die durch das Update behoben werden. Dies ist nicht ungewöhnlich, da ein einziger Logikfehler eine Kette von Schwachstellen verschiedener Klassen enthalten kann.
Wenn wir uns das Update KB5055523 (April 2025) ansehen, finden wir eine Reihe von Fehlern mit den Bezeichnungen CVE-2025-24058, CVE-2025-24060, CVE-2025-24062, CVE-2025-24073 und CVE-2025-24074 (Abbildung 14). Sie alle beziehen sich auf den Desktop Window Manager (DWM), und alle sind das Ergebnis von „CWE-20: Improper Input Validation“, was sie für das Modell vage und mehrdeutig macht.
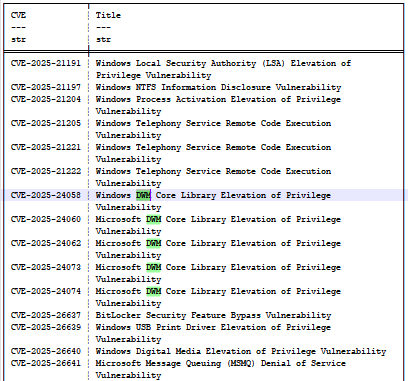 Abb. 14: Teilliste der Fehler im Update von April 2025
Abb. 14: Teilliste der Fehler im Update von April 2025
Die Verwendung von LLMs erfordert Kompromisse. Sie alle haben etwas gemein: den Kostenfaktor. Das LLM versucht, die Aufgabe in einem Durchlauf abzuschließen, auch wenn der erforderliche Kontext nicht abgestimmt ist. Um genauere Ergebnisse zu erhalten, müssen wir die Ergebnisse anhand von Heuristiken bewerten und den Kontext verfeinern, damit er eine bessere Mutation hervorbringen kann.
Wir haben die Berichte zu den Fehlern des Updates vom April 2025 verwendet, um das Ergebnis eines solchen Anwendungsfalls zu bewerten. Durch den Vergleich der Ursache mit den zusätzlichen Informationen konnten wir verstehen, wie die verschiedenen Schwachstellen das LLM über seine Analyse beeinflussen können (Tabelle).
CVE | Primäre fehlerhafte Funktion(en) | Bug-Klasse | Hauptursache |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | Heap-basierte Speicherbeschädigung durch falsche Input Validation / Integer-Überlauf während dynamischer Array-Zunahme (CWE-20, führt zu CWE-787). | Derselbe PreSubgraph-Integer-Wrap löst den Überlauf des Okklusions-Informationspuffers aus |
CVE-2025-24073 | COcclusionContext::PreSubgraph | Heap-basierter Pufferüberlauf / Integer-Überlauf aufgrund unzulässiger Input Validation (CWE-20, führt zu Speicherbeschädigung) | Derselbe PreSubgraph-Integer-Wrap löst den Überlauf des Okklusions-Informationspuffers aus |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | Ungültige Eingabe-/Grenzüberprüfung, die zu Heap-Schreibzugriff außerhalb des zulässigen Bereichs führt | Derselbe PreSubgraph-Integer-Wrap löst den Überlauf des Okklusions-Informationspuffers und einen weiteren Überlauf aus |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | Use-After-Free / Typverwirrung, die aus der Weitergabe eines „Freed Object“-Zeigers als impliziten „This“-Zeiger resultiert (CWE-416, CWE-843) | Freigegebener CD3DDevice-Zeiger wiederverwendet als CDeviceManager this |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | Heap-basierter Pufferüberlauf aufgrund falscher Input Validation von durch Anrufer bereitgestellten Listenlängen (CWE-20, führt zu CWE-122) | Heap-Überlauf mit CollectOverlayCandidates |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | Abschneiden von Zeiger / falsche Input Validation führt zu Use-After- Free / Erhöhung von Berechtigungen (CWE-20, im Zusammenhang mit auf CWE-704) | Argumente erweitert auf __int64; IsOverlayCandidateCollectionEnabled() hinzugefügt |
Mehrere Schwachstellen und ihre RCA werden durch das LLM ermittelt
Die Tabelle spiegelt lediglich den Inhalt der Berichte wider. Die Evaluierung der Update-Fehler vom April 2025 deckt die Duplizierung von CVE-2025-24074, CVE-2025-24073 und CVE-2025-24060 auf. Alle drei beziehen sich auf die gleichen Funktionen mit geringfügigen Änderungen oder Ergänzungen.
CVE-2025-24058 (dwmcore.dll) scheint sich mit der ComputeOverlayConfiguration-Berücksichtigung von CVE-2025-24060 zu überschneiden. CVE-2025-24058 (dwmcorei.dll)und CVE-2025-24062 richten sich jedoch anscheinend auf völlig unterschiedliche Ursachen.
Da das LLM kein deterministisches System ist, kann die Ausgabe auch bei identischer Eingabe variieren. Wir sehen, wie sich noch so geringfügige Änderungen im Eingabekontext auf die Ergebnisse des LLMs auswirken und zu zwei unterschiedlichen Berichten führen können.
Das Preisschild
PatchDiff-AI basiert auf einer überwachten Multi-Agent-Architektur mit verschiedenen LLM-Modellen. Das senkt die Kosten und gewährleistet zugleich eine hohe Genauigkeit. Die Kostenaufschlüsselung für die Erstellung eines Berichts mit OpenAI-Modellen ergibt Kosten von maximal 1,43 US-Dollar.
In der Praxis haben wir 131 Berichte aus März-, April- und Mai-Updates generiert, die nur für Windows 11 24H2 x64 gefiltert wurden. Die durchschnittlichen Kosten beliefen sich auf ca. 0,14 US-Dollar pro Bericht. Wenn man bedenkt, wie viele Schwachstellen täglich (wenn nicht gar stündlich) bekämpft werden, können diese Kosten je nach Skalierung erheblich sein.
Wenn vollständig autonome Funktionen aktiviert sind, wie zum Beispiel die erweiterte Verfeinerung in den Agenten für Windows-Interna und den Schwachstellenforschung, kann der Kalkulationspreis begrenzt werden. Aufgrund der dem System immanenten Unbestimmtheit kann jedoch kein Mittelwert gebildet werden.
Fazit
Was die Nutzung von KI und insbesondere von LLMs im Bereich Cybersicherheit betrifft, sind die Zukunftsaussichten sehr vielversprechend. Mit LLMs lässt sich ein sehr komplizierter, aber methodischer Prozess leicht in einen einfachen Workflow umwandeln und in die Pipelines verschiedener Sicherheitsteams integrieren.
Unsere Untersuchungen zeigen, dass eine vollständig automatisierte RCA von Schwachstellen nicht nur möglich, sondern auch sinnvoll ist – auch angesichts der hohen Genauigkeit und der überschaubaren Kosten.
Durch die Zergliederung des Problems in Mikro-Aufgaben und die Anpassung an eine spezialisierte Multi-Agent-Architektur, die Analysen von Windows-Interna, Reverse Engineering-Workflows und schwachstellenspezifische Analysen kombiniert, konnten wir LLMs aus ihrer konventionellen Limitierung befreien. Diese Praxis (und das Begleittool PatchDiff-AI) können auch für andere Produkte und Plattformen verallgemeinert werden.
Anhand unseres Systems können Sicherheitsteams umfassende Erkennungen erstellen, Schwachstellen effektiv abschwächen und Penetrations- und Regressionstests für ihre Systeme erstellen. Darüber hinaus kann unser System den Prozess der Auslösung bekannter Schwachstellen verkürzen und so weitere Forschung und Variantenermittlung in der verwundbaren gemeinsam genutzten Codebasis ermöglichen.

Tags


