
Analisi riassuntiva
In questa ricerca, abbiamo esaminato l'uso dei modelli linguistici di grandi dimensioni per individuare la causa principale delle vulnerabilità corrette con patch.
Abbiamo sviluppato un sistema multi-agente chiamato PatchDiff-AI che analizza autonomamente la causa principale delle vulnerabilità della Patch Tuesday e genera un rapporto dettagliato.
Questo tipo di analisi può aiutare i team addetti alla sicurezza ad analizzare le vulnerabilità quasi istantaneamente, sia per scopi difensivi che offensivi.
Utilizzando più strategie, siamo stati in grado di mettere a punto il nostro sistema per raggiungere un tasso di successo superiore all'80% nella generazione di rapporti completamente automatizzati, tra cui l'analisi del vettore di attacco e il flusso di attivazione.
Patch Tuesday → Exploit Wednesday
Il ciclo di aggiornamento regolare di Microsoft si basa sul Patch Tuesday, ossia il secondo martedì di ogni mese, in cui l'azienda rilascia un elenco completo delle CVE e delle relative correzioni, che vengono fornite come file MSU (Microsoft Standalone Update), un formato di packaging che applica gli aggiornamenti tramite patch o sostituzione dei file system principali.
Il Patch Tuesday è spesso seguito da quello che è noto come "Exploit Wednesday", ossia, il giorno successivo, in cui i criminali fanno a gara per scoprire le vulnerabilità per le quali Microsoft ha creato una patch. Eseguendo il diffing dei file binari aggiornati, i criminali possono individuare rapidamente i problemi di sicurezza principali e tentare di sfruttarli prima che le organizzazioni abbiano implementato ampiamente le patch necessarie.
Allo stesso modo, gli addetti alla sicurezza, spesso, hanno fretta di analizzare queste patch per comprendere le cause di base delle vulnerabilità al fine di effettuare rilevamenti e creare mitigazioni.
Lo stato attuale del diffing delle patch
Oggi, il diffing delle patch è un processo noioso. Per identificare correttamente il codice vulnerabile, un ricercatore deve:
Identificare il file che si sospetta contenga la vulnerabilità
Eseguire un diff binario per identificare le modifiche
Isolare le modifiche relative alla sicurezza da altri aggiornamenti del codice di routine
Analizzare le parti sospette e comprendere la causa principale del problema
Esaminare dinamicamente i flussi di chiamata per individuare potenziali percorsi di attivazione
Valutare il completamento della correzione della patch
Poiché questi passaggi possono, talvolta, richiedere settimane, si tratta di un problema ulteriormente amplificato dall'enorme volume di vulnerabilità che vengono rilasciate simultaneamente ogni mese.
Abbiamo, quindi, deciso di trovare un modo migliore per consentire ai ricercatori di analizzare rapidamente le vulnerabilità legate alle patch e di comprenderne la causa principale.
Utilizzo dei modelli LLM per l'analisi dei diff delle patch
I modelli linguistici di grandi dimensioni (LLM) possono generare statisticamente informazioni ragionevoli e accurate sulla base dei dati raccolti, insieme agli input degli utenti. Tuttavia, esistono alcune limitazioni, tra cui un intervallo di contesto limitato (che influisce sulla quantità di dati che può elaborare e sui relativi costi operativi) e la famigerata allucinazione del modello.
Nel corso degli anni, sono stati pubblicati molti articoli sul contributo dei modelli LLM al campo della valutazione della vulnerabilità nel settore della sicurezza. Oggi, i modelli LLM sembrano incontrare difficoltà nell'analisi dei software "closed source", mentre offrono performance migliori in termini di vulnerabilità web e open source, ossia in aree in cui la base comune è costituita dalla presenza di codice leggibile dall'uomo.
Da un lato, l'agente Aardvark di OpenAI e Claude Code, lo strumento di revisione della sicurezza, sono ancora legati al codice sorgente leggibile. D'altro canto, troviamo Big Sleep di Google Project Zero che mira a scoprire le vulnerabilità zero-day. Tuttavia, nessuno dei due approcci analizza il file binario come "closed source".
Presentazione dello strumento PatchDiff-AI
La nostra ricerca adotta un approccio diverso utilizzando i modelli LLM per l'analisi della causa principale (RCA) delle patch di sicurezza. La nostra teoria, che sembra essere stata confermata, si basava sul fatto che il contesto aggiuntivo fornito dal "diff" binario poteva migliorare notevolmente la capacità dei modelli LLM di comprendere il codice complesso e di basso livello.
Per questa attività, abbiamo sviluppato un sistema multi-agente che automatizza l'analisi degli aggiornamenti della Knowledge Base (KB) di Microsoft per una piattaforma specifica (Figura 1) e che abbiamo denominato PatchDiff-AI.
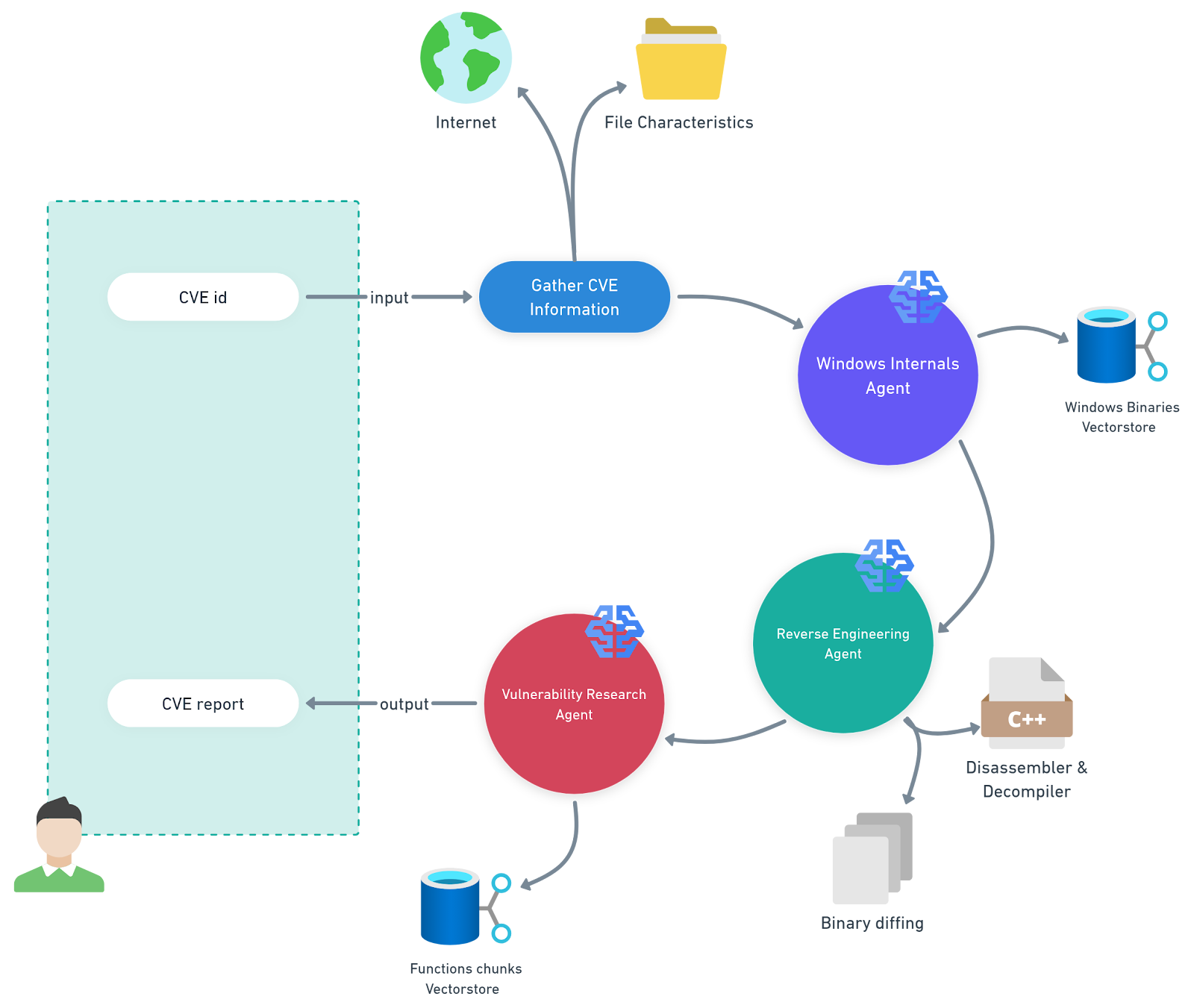 Fig. 1. Illustrazione del nostro sistema multi-agente, PatchDiff-AI
Fig. 1. Illustrazione del nostro sistema multi-agente, PatchDiff-AI
Definizioni relative allo strumento PatchDiff-AI
Agente dei componenti interni di Windows: questo agente utilizza una pipeline RAG (Retrieval-Augmented Generation) supportata da un archivio vettoriale contenente i file binari di Windows e i metadati delle loro funzionalità. In tal modo, l'agente può restringere significativamente l'ambito dell'analisi e concentrarsi sui componenti più rilevanti.
Agente di reverse engineering: questo agente utilizza strumenti avanzati di reverse engineering per l'analisi e il diffing dei file pertinenti, aggiungendo gli artefatti rilevati al contesto generale per consentirne l'uso da parte di altri agenti.
Agente di ricerca sulle vulnerabilità: questo agente coordina l'analisi raccogliendo tutti gli elementi e le altre informazioni esistenti nel contesto e generando un rapporto coerente.
Metodologia
A causa dei limiti dell'intervallo di contesto e dell'allucinazione, è fondamentale fornire un contesto pertinente e conciso per utilizzare i modelli LLM nel modo più efficace possibile, mantenendo un'elevata precisione nell'attività di isolamento dei componenti di codice vulnerabili e riducendo, al contempo, i costi operativi.
Dividere e conquistare
Uno dei dettagli fondamentali della nostra implementazione consisteva nel suddividere l'analisi nelle seguenti attività più piccole e mirate, che, alla fine, operavano come gli agenti:
Recuperare le informazioni sulle CVE per creare un profilo
Scaricare gli aggiornamenti pertinenti e applicare le patch delta ai file della versione di base
Creare un agente basato sull'AI per i componenti interni di Windows allo scopo di isolare i file pertinenti utilizzando i metadati delle vulnerabilità
Creare un agente di reverse engineering basato sull'AI in grado di:
Smontare e applicare i simboli, quindi esportarli per il diffing dei file binari
Correlare i file binari e identificare modifiche e flussi di chiamata
Individuare il blocco del codice vulnerabile
Creare un agente di ricerca sulle vulnerabilità basato sull'AI che procede ad iterare tramite i possibili percorsi delle vulnerabilità per correlare e trovare il miglior risultato possibile
Uno dei principali vantaggi di questa divisione è stato rappresentato dalla possibilità di utilizzare modelli specifici per ogni tipo di attività: OpenAI o4-mini si è evoluto con l'arricchimento dei metadati dei file, mentre OpenAI o3 è stato utilizzato per l'analisi approfondita del codice sospetto vulnerabile.
La scelta del modello giusto per l'attività ha avuto un duplice vantaggio, dapprima per l'accuratezza e poi per i costi offerti.
Arricchimento del contesto
I modelli LLM sono sistemi che "ricordano" una grande quantità di informazioni. Richiamato con un prompt, il modello LLM viene regolato in modo da fornire le informazioni più rilevanti nel contesto del prompt.
Tutte le informazioni che possiamo fornire al modello LLM sulla vulnerabilità corretta con patch contribuiranno a generare una risposta più accurata e ad aumentare le possibilità di individuare il codice vulnerabile. Tuttavia, informazioni ambigue sulla vulnerabilità comporteranno risultati insoddisfacenti, se presenti.
L'arricchimento del contesto con i metadati della vulnerabilità durante l'analisi si è rivelato fondamentale. Per raggiungere questo arricchimento, abbiamo fornito al modello LLM le descrizioni della KB, le descrizioni dei file di sistema e i dati del diff binario. Questo approccio ci ha consentito di restringere il numero di modifiche da analizzare e, di conseguenza, la lunghezza del contesto e il numero di iterazioni con il modello LLM.
Risultati
Per valutare la nostra struttura, abbiamo esaminato la capacità del modello di individuare correttamente:
Il file eseguibile vulnerabile che corrisponde alla CVE
La funzione vulnerabile presente all'interno dell'eseguibile
La causa principale della vulnerabilità e una sua corretta descrizione
In base a questi parametri, abbiamo analizzato le ultime tre versioni della Patch Tuesday per Windows 11 24H2. Dopo aver eseguito il nostro strumento e generato un rapporto automatizzato, abbiamo esaminato manualmente i risultati selezionati e determinato l'accuratezza della risposta finale del modello.
Una volta perfezionato il contesto e regolato i vari modelli per le diverse attività, abbiamo ottenuto i seguenti risultati:
È stato identificato l'esatto eseguibile corretto con patch per la CVE in questione nell'88,6% dei casi
È stata trovata la corretta funzione vulnerabile nell'83,9% dei casi
È stato possibile individuare la corretta causa principale della vulnerabilità nel 71,4% dei casi
Se si escludono errori di generazione dei rapporti causati da un contesto insufficiente, ad esempio arresti anomali dello strumento di analisi statica o l'impossibilità di applicare una patch delta, è possibile stimare la percentuale di successo del modello quando viene assegnato il blocco di codice corretto. In tal caso, la percentuale di successo del modello LLM è pari a circa il 96% quando viene fornito il blocco di codice corretto nel contesto (Figura 2).
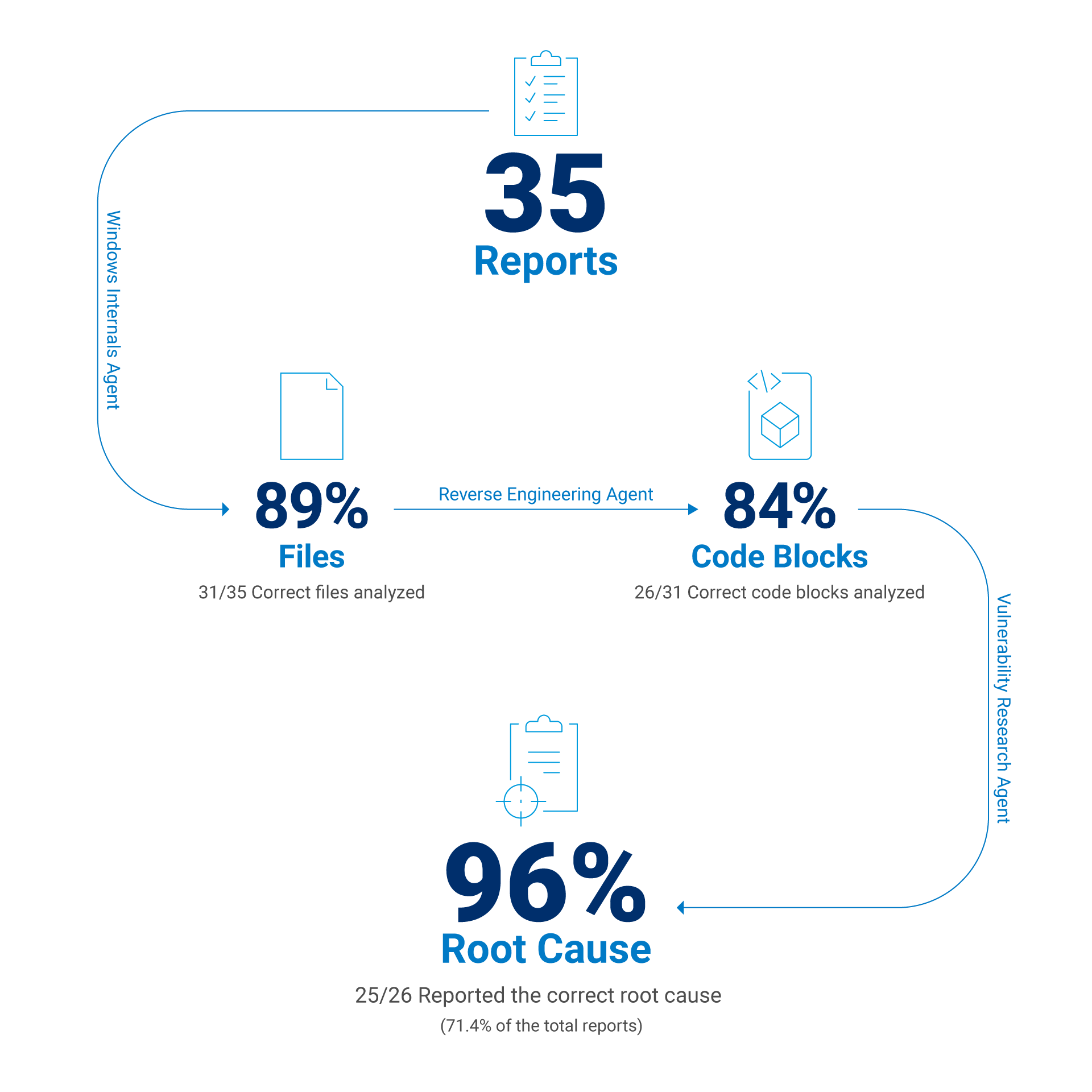 Fig. 2. Risultati della valutazione di report selezionati su CVE
Fig. 2. Risultati della valutazione di report selezionati su CVE
Il rapporto sulle CVE e i suoi componenti
Di conseguenza, abbiamo riscontrato diversi casi di utilizzo interessanti che vorremmo condividere e indagare accuratamente con voi. Ogni caso di utilizzo ha la stessa struttura del rapporto e contiene i seguenti componenti:
Dettagli delle CVE che costituiscono il rapporto
RCA: il fulcro del rapporto
Frammento di codice della patch (prima e dopo)
Panoramica dettagliata su come poter attivare la vulnerabilità
Descrizione accurata della patch
Vettore di attacco che potrebbe sfruttare la vulnerabilità
Impatto chiaro e dettagliato della vulnerabilità
Inoltre, l'ultima sezione di ogni rapporto cerca di mettere in discussione l'efficacia della patch e descrive come poterla aggirare
Case study
Nei quattro case study successivi, analizzeremo alcuni casi interessanti che evidenziano l'eccellenza del nostro sistema, i suoi punti deboli e le aree in cui non è adatto.
Caso 1. Installazione e blocco
Una delle vulnerabilità che abbiamo analizzato è stata la CVE-2025-24991, un bug di lettura fuori banda in Windows NTFS, che consente a criminali autorizzati di divulgare le informazioni a livello locale, come segnalato dal Microsoft Security Response Center (MSRC). Un'altra informazione viene divulgata dalle domande frequenti, in cui si legge che un criminale potrebbe indurre un utente locale di un sistema vulnerabile ad installare un VHD appositamente creato per poter attivare la vulnerabilità.
Ora, la vulnerabilità è chiaramente correlata al componente NTFS, che può implicare il coinvolgimento del file ntfs.sys.
Un altro indizio è fornito dal fatto che la vulnerabilità viene attivata da un file VHD di installazione. L'analisi manuale della patch potrebbe richiedere, nel migliore dei casi, alcune ore, ma l'uso dello strumento PatchDiff-AI ha velocizzato questa operazione richiedendo solo pochi minuti. Inoltre, il nostro strumento funziona anche quando non esiste un percorso ovvio per identificare la causa principale, come in questo caso,
in cui il sistema sostiene di aver individuato la causa principale tra le 17 modifiche più rilevanti apportate al file nell'aggiornamento KB5053598. Il rapporto completo è disponibile nel nostro archivio GitHub, a cui segue il nostro processo di valutazione.
In primo luogo, il nostro strumento genera il componente pertinente, che è effettivamente il file ntfs.sys, e la funzione rilevante ReadRestartTable(); inoltre, fornisce una breve spiegazione sullo scopo per cui la logica è stata progettata (Figura 3).
Microsoft Windows NTFS driver (ntfs.sys)
Affected routines: ReadRestartTable() and its consumer
InitializeRestartState().Ora, analizziamo la classe di vulnerabilità correlata all'indice CWE, che, in questo caso, è la CWE-125: si tratta di un bug di lettura fuori banda, che ci aiuterà a capire quale vulnerabilità cerca il modello LLM quando compone questo rapporto.
La Figura 4 illustra i risultati emersi dall'RCA eseguita con il nostro strumento, indicando chiaramente gli aspetti negativi e individuando con precisione il problema.
ReadRestartTable() processes a restart area that was previously
retrieved from the NTFS transaction log (LFS). The function first
validates the outer log record with NtfsCheckLogRecord(), then calls
NtfsCheckRestartTable() to validate the embedded restart table.
Buggy offset computation (pre-patch)
1. v9 = *(QWORD *)(a4 + 72) // ptr to restart area
2. offset_to_tbl = *(WORD *)(v9 + 4) // value comes from log
3. NtfsCheckRestartTable(v9 + offset_to_tbl, size, cookie)
The code trusts the 16-bit field at offset +4 of the restart area to
locate the first restart table. If an attacker supplies a crafted
restart record in which this field is smaller than the actual header
size, NtfsCheckRestartTable() will be invoked on a memory range that
starts inside the header instead of at the real table. Because the
size argument (derived from *(DWORD *)(a4 + 64)) is unchanged, the
routine reads past the caller-supplied buffer, disclosing adjacent
kernel memory.
Additional consequence: the return value (pointer returned to the
caller) is likewise computed from this untrusted field, so callers
such as InitializeRestartState() may later copy the out-of-bounds data
into pageable pool that is accessible to user mode via other
interfaces.
Patched behaviour
The patch discards the header-supplied offset. Instead it derives the
correct header length from the number of client entries:
hdr_len = (clients <= 1) ? 40 : (8 * clients + 32);
NtfsCheckRestartTable(v10 + hdr_len, ...);
If the validation fails, execution now jumps to new corruption
handling code that raises STATUS_DISK_CORRUPT_ERROR before any out-of-
bounds access can occur.L'esame di questi risultati tramite gli strumenti IDA e BinDiff rivela che si tratta effettivamente della posizione corretta; inoltre, sappiamo che, poiché Microsoft utilizza i flag di funzione per rifiutare la correzione della vulnerabilità, la posizione può essere invertita in caso di comportamenti imprevisti (Figura 5).
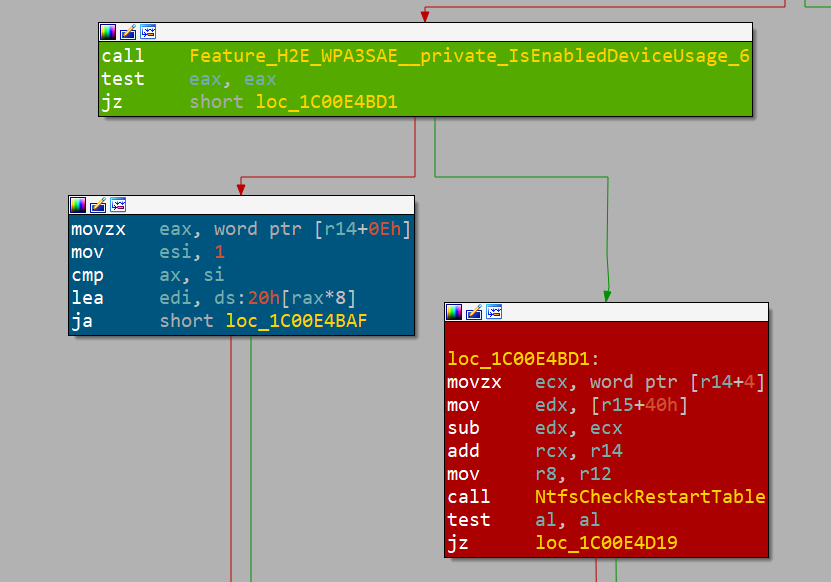 Fig. 5. Microsoft feature flag (blocco verde), percorso corretto (blocco blu) e percorso vulnerabile (blocco rosso)
Fig. 5. Microsoft feature flag (blocco verde), percorso corretto (blocco blu) e percorso vulnerabile (blocco rosso)
Nel rapporto, è possibile trovare i frammenti di codice della parte vulnerabile decompilata della funzione ed esaminare il codice vulnerabile (Figura 6).
```c
// pre-patch (simplified)
WORD offset = *(WORD *)(RestartArea + 4);
if (!NtfsCheckRestartTable(RestartArea + offset,
Total - offset, Cookie))
NtfsRaiseStatus(...);
```
```c
// post-patch
WORD clients = *(WORD *)(RestartArea + 14);
ULONG hdrLen = (clients <= 1) ? 40 : (8 * clients + 32);
if (!NtfsCheckRestartTable(RestartArea + hdrLen,
Total - *(WORD *)(RestartArea + 4),
Cookie))
NtfsRaiseStatus(...);
```Uno dei punti salienti del rapporto è rappresentato dalla sezione relativa all'attivazione dettagliata, in cui il modello LLM suggerisce le possibili misure da adottare per attivare la vulnerabilità, se applicabile, spiegando come sia possibile sfruttarla praticamente (Figura 7).
1. User mounts or accesses a volume containing a malicious $LogFile.
2. NtfsMountVolume() → NtfsRestartVolume() → InitializeRestartState().
3. InitializeRestartState() reads the first restart area and calls
ReadRestartTable().
4. ReadRestartTable() uses the untrusted 16-bit offset to pass an
out-of-range buffer to NtfsCheckRestartTable(), which performs the
actual out-of-bounds memory read.
5. The leaked data is later copied back into attacker-controlled disk
structures or user-mapped memory, allowing disclosure.Se combinato con richieste di follow-up, il nostro strumento analizza ulteriormente il codice decompilato rilevando un numero significativamente maggiore di informazioni e suggerendo, potenzialmente, anche una PoC (Proof-of-Concept).
Un'altra informazione utile è disponibile nelle sezioni relative ai vettori di attacco, che forniscono una visione dettagliata su come sia possibile sfruttare la vulnerabilità, offrendo un'idea dell'ambito della vulnerabilità e di ciò che serve ad un criminale per sfruttarla (Figura 8).
Local attacker crafts an NTFS image (or directly edits $LogFile on an
existing volume) so that the Restart Area field at offset +4 contains
an undersized value. Mounting or otherwise activating the volume on a
vulnerable system triggers the OOB read in kernel context.Le restanti sezioni forniscono una descrizione più generale della patch e del suo impatto sulla sicurezza del sistema. Tuttavia, nell'ultima sezione, abbiamo chiesto al modello LLM di provare a sfidare la patch per verificare se sia possibile riuscire ad identificare rapidamente un'altra vulnerabilità all'interno della correzione. In questo caso, il modello ha confermato che la patch è completa, affermando che ora tutti i percorsi di errore vengono segnalati prima di un eventuale accesso fuori banda.
Caso 2. L'allineamento delle stelle
È utile e, spesso, sufficiente per i team che si occupano delle operazioni di rilevamento o mitigazione, valutare il rapporto rispetto al database IDA generato automaticamente e all'output BinDiff. Tuttavia, il nostro approccio va oltre e può rivelarsi utile anche per i criminali poiché, in alcuni casi, il sistema può andare oltre l'analisi e produrre effettivamente un exploit valido.
Ad esempio, nella CVE-2025-32713, una vulnerabilità che è stata corretta con patch nell'aggiornamento di giugno 2025 (KB5060842), l'overflow del buffer basato su Healthcare in Windows Common Log File System Driver consente a un criminale autorizzato di elevare i privilegi a livello locale. All'incirca in due minuti, il nostro strumento ha generato un rapporto che ha fatto risalire il problema in CClfsLogFcbPhysical::ReadLogBlock().
A questo punto, ci sono due modi per sfidare la possibilità di sfruttare la vulnerabilità:
Invertire manualmente la funzione e i relativi chiamanti fino alla chiamata in modalità utente
Far eseguire questa operazione al modello LLM, che poi andrà a creare una PoC in modo autonomo
Tuttavia, come spesso accade, esiste una terza opzione: l'approccio ibrido. Possiamo chiedere al modello LLM di eseguire il "lavoro pesante" di reverse engineering, mentre si determinano i flussi di codice indiretti e si risolvono le complesse connessioni tra le parti logiche del file binario. In questo modo, il modello LLM potrà ottenere risultati migliori.
Utilizzando questo metodo, abbiamo ottenuto una delle temute "schermate blu" (BSOD) in poche ore (Figura 9).
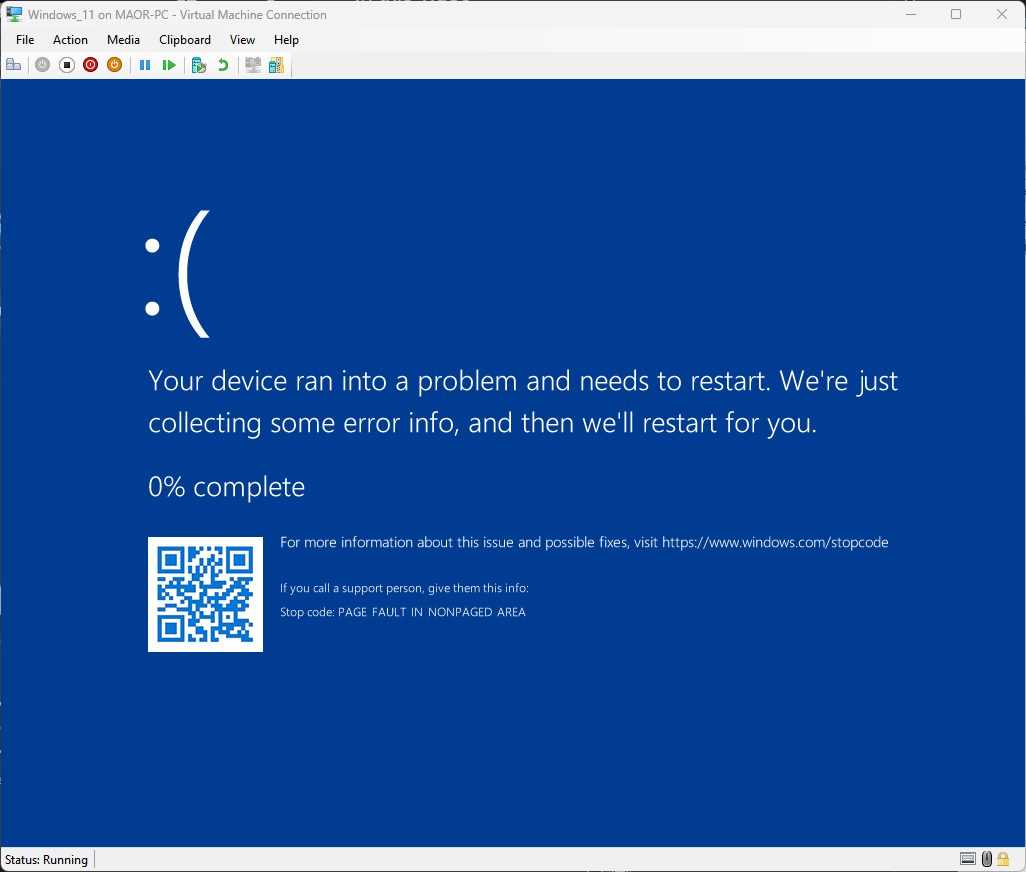 Fig. 9. BSOD durante l’esecuzione del PoC di CVE-2025-32713
Fig. 9. BSOD durante l’esecuzione del PoC di CVE-2025-32713
Il percorso di comprensione del flusso di attivazione della vulnerabilità è iniziato con la valutazione del codice vulnerabile suggerito, come descritto nella sezione relativa all'RCA. Dopo aver capito che la patch tenta di correggere un problema di sicurezza, abbiamo analizzato il flusso di chiamata fino al controllo di input/output (IOCTL) 0x80076832.
Durante la ricerca delle controparti in modalità utente, sono stati individuati due candidati, poiché clfsw32.dll esporta la funzione ReadLogRecord con un percorso diretto per richiamare questo controllo IOCTL (Figura 10).
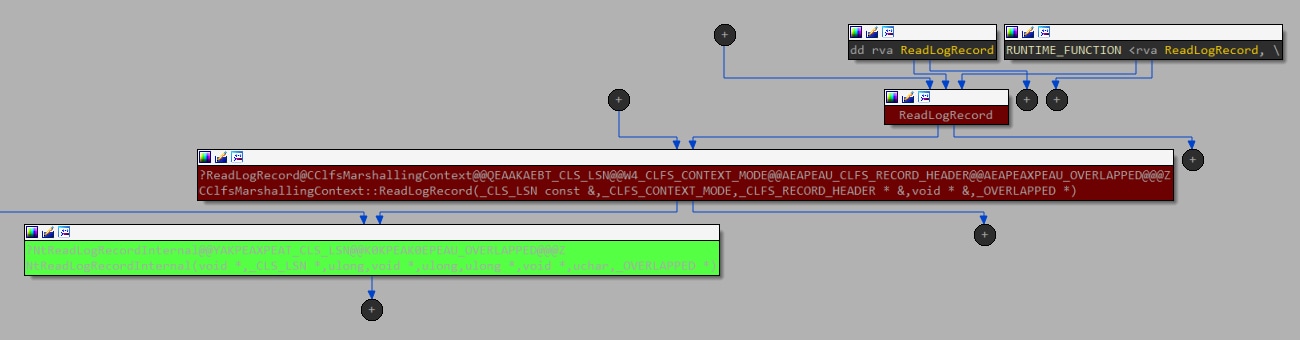 Fig. 10. Grafico del flusso delle chiamate, a partire da un metodo esportato dalla modalità utente fino al driver kernel (utilizzando la chiamata IOCTL)
Fig. 10. Grafico del flusso delle chiamate, a partire da un metodo esportato dalla modalità utente fino al driver kernel (utilizzando la chiamata IOCTL)
In ogni fase, abbiamo valutato come il modello LLM possa aiutare ad invertire e analizzare la logica, considerando che è stata formata su alcune parti di queste conoscenze. La Figura 11 mostra come sia possibile risolvere il requisito di condizione per v4, ovvero le dimensioni del buffer fornito.
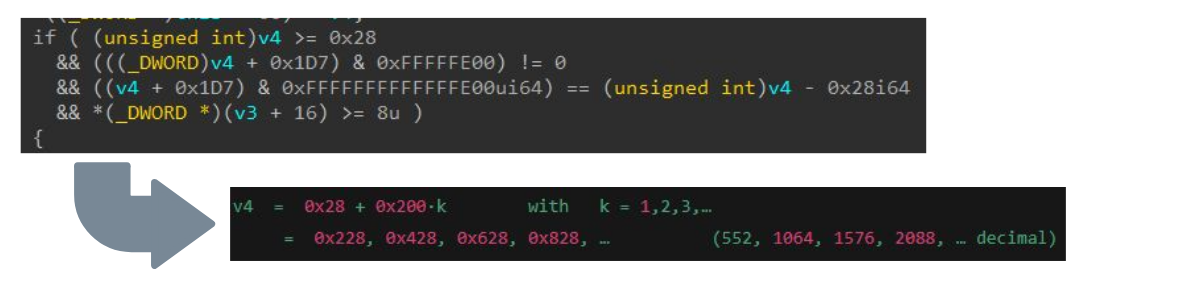 Fig. 11. Utilizzo di LLM per analizzare un controllo di validazione
Fig. 11. Utilizzo di LLM per analizzare un controllo di validazione
Sebbene abbiamo assistito ad alcune eccellenti osservazioni che il modello LLM è riuscito a trovare, in alcuni casi i risultati proposti risultavano fuorvianti. Tornando alla vulnerabilità CVE-2025-32713, in una delle risposte fornite, il nostro rapporto conteneva la citazione mostrata nella Figura 12.
“crafts the log header so that the page size (v48) exceeds the supplied buffer”Questa risposta è stata piuttosto confusa e, in definitiva, non ci ha aiutato a capire come sia possibile attivare il codice vulnerabile. Infatti, ci ha portato ad un percorso di ricerca completamente irrilevante (abbiamo tentato di manipolare la struttura di file .blf , in cui erano state già implementate varie misure di mitigazione). Successivamente, abbiamo creato dischi virtuali con diversi byte fisici e logici per settore e abbiamo analizzato il loro comportamento tramite un'operazione di debug.
Possiamo dire che il modello LLM sia riuscito a gestire la maggior parte del lavoro, ma ha richiesto un'attenta supervisione da parte di un ricercatore esperto. Infatti, i modelli LLM sono uno strumento di assistenza per l'uomo, purché l'assistenza sia fornita correttamente.
In altre parole, il modello può occasionalmente deviare dal percorso previsto risultando inefficace, pertanto la guida dell'uomo è stata essenziale per mantenerlo sulla giusta strada. Ciò nonostante, i risultati parlano da soli: il modello LLM ha identificato correttamente il codice vulnerabile, ha tracciato accuratamente il flusso di chiamata e ha spiegato come l'assegnazione errata della v27 abbia causato l'overflow in CcCopyRead().
Caso 3. Un ago in un pagliaio
In alcuni casi, i risultati forniti dal modello LLM vanno presi con cautela. Le allucinazioni non sono l'unico rischio correlato ai modelli LLM, ma questo problema può ripetersi ripetutamente nelle relative interfacce (ad esempio, ChatGPT può commettere errori. Controllare le informazioni importanti.").
In questo caso, occorre prestare la stessa cautela, sebbene il sistema tenti di verificare i propri dati di input e output e di esaminare più percorsi per identificare la causa principale. In alcuni casi, fornire un risultato è quasi impossibile perché le condizioni sono troppo ampie e ambigue.
Prendiamo la vulnerabilità CVE-2025-29974 segnalata dall'aggiornamento KB5058411 di maggio. Nella pagina delle informazioni del MSRC sulla vulnerabilità, si legge che l'underflow dei numeri interi (wrap o wraparound) in Windows Kernel consente a un criminale di divulgare le informazioni su una rete adiacente, un'affermazione che potrebbe non essere molto chiara.
Più avanti, nella pagina del MSRC si afferma che il criminale deve trovarsi nelle vicinanze, ossia all'interno del raggio d'azione, per ricevere le trasmissioni radio: sta quindi descrivendo chiaramente come esfiltrare le informazioni, ma non è chiaro né come né tramite quale hardware. In assenza di queste informazioni, si riduce le possibilità di ottenere un rapporto valido, se applicabile.
Per quanto riguarda la CVE-2025-29974, abbiamo eseguito il nostro strumento e abbiamo ricavato una rapporto su due funzioni anonime: sub_1408E6D3C e sub_1408FAD58, a cui faremo riferimento per comodità come primary() e secondary(). Nella Figura 13, viene illustrata una panoramica BinDiff di queste funzioni, da cui è facile vedere come sono piuttosto diverse tra loro…fin troppo diverse, se posso dirlo.
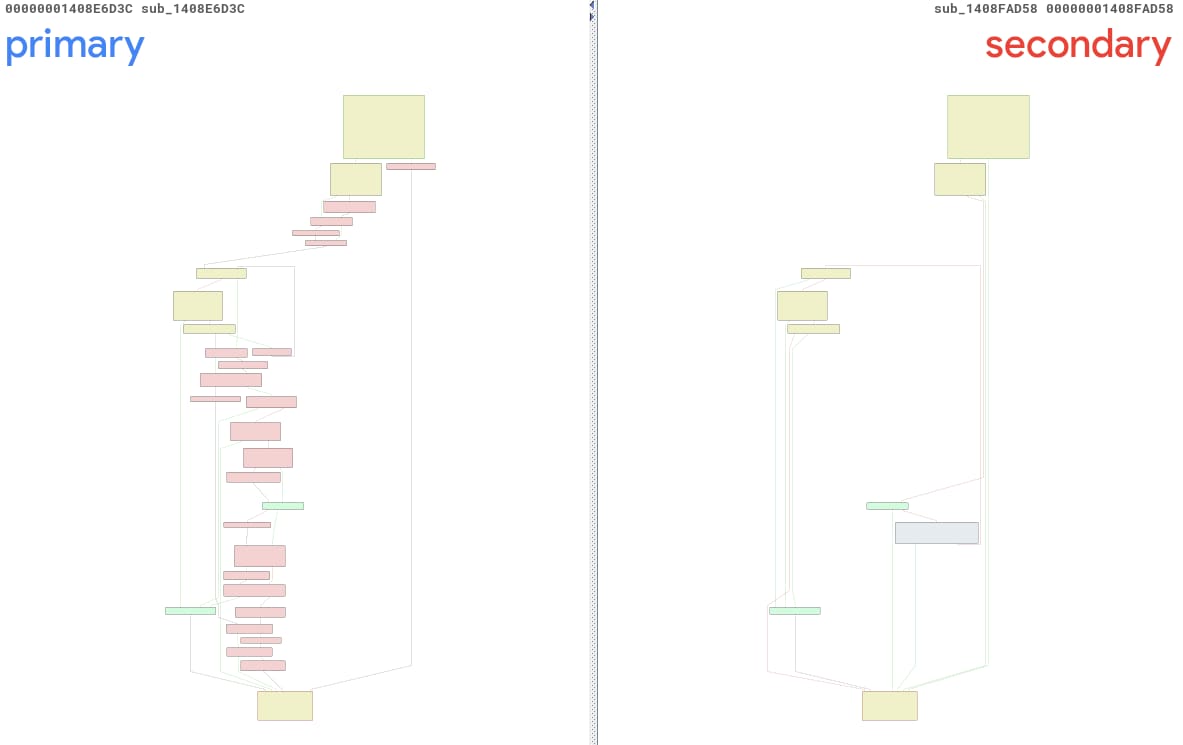 Fig. 13. Vista BinDiff delle modifiche creata automaticamente utilizzando PatchDiff-AI
Fig. 13. Vista BinDiff delle modifiche creata automaticamente utilizzando PatchDiff-AI
Dopo un esame più approfondito, possiamo identificare la funzione primary corretta come sub_1408E7738, un metodo completamente diverso, situato a un indirizzo diverso. Il motivo principale di questa confusione risiede nel fatto che il file ntoskrnl.exe è stato notevolmente modificato tramite questo aggiornamento. Infatti, sono state modificate 3791 funzioni, il che ha abbassato notevolmente la probabilità di trovare le coppie corrette prima e dopo l'operazione.
Il livello di fiducia fornito insieme al rapporto per questo caso è stato pari allo 0,2 a indicare una probabilità del 20% per il rapporto di individuare la vulnerabilità corretta. Questo livello di fiducia, insieme al numero elevato di modifiche dei blocchi di codice, riflette gli scarsi risultati che sono emersi.
Caso 4. Un'eccessiva vulnerabilità
In alcuni casi, il componente presenta più vulnerabilità che vengono risolte dall'aggiornamento. Non si tratta di un caso raro perché un singolo difetto logico può contenere una catena di vulnerabilità con classi diverse.
Osservando l'aggiornamento KB5055523 (aprile 2025), è possibile trovare una serie di bug denominati CVE-2025-24058, CVE-2025-24060, CVE-2025-24062, CVE-2025-24073 e CVE-2025-24074 (Figura 14), tutti correlati a DWM (Desktop Window Manager) e derivanti da CWE-20: Improper Input Validation, che li rende indistinti e ambigui per il modello.
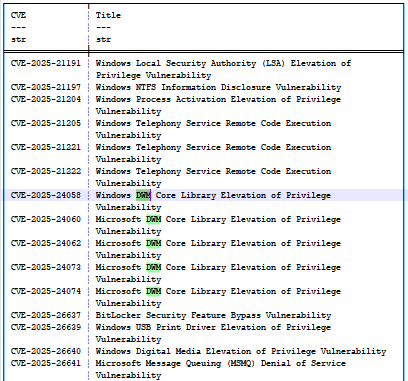 Fig. 14. Elenco parziale dei bug dell’aggiornamento di aprile 2025
Fig. 14. Elenco parziale dei bug dell’aggiornamento di aprile 2025
L'uso dei modelli LLM presenta vantaggi e svantaggi. Tra questi ultimi, i costi, che interessano tutti i modelli. Il modello LLM tenta di completare l'attività richiesta in un'unica operazione, anche se il contesto richiesto non è allineato. Per ottenere risultati più accurati, dobbiamo valutare i risultati attraverso l'euristica e perfezionare il contesto in modo da creare una variazione migliore.
Abbiamo utilizzato i rapporti relativi ai bug corretti dall'aggiornamento di aprile 2025 per valutare l'esito di tale caso di utilizzo. Confrontando la causa principale e le informazioni aggiuntive, siamo riusciti a comprendere in che modo più vulnerabilità possono influenzare il modello LLM tramite la sua analisi (Tabella).
CVE | Funzioni principali errate | Classe bug | Causa principale |
|---|---|---|---|
CVE-2025-24074 | COcclusionContext::PreSubgraph CDDisplaySwapChain::PresentMPO CLegacySwapChain::Present | Danneggiamento della memoria basata sull'heap causato da un'errata verifica dell'input/ overflow del numero intero durante la crescita dell'array dinamico (CWE-20, che conduce alla CWE-787). | Lo stesso numero intero PreSubgraph attiva l'overflow del buffer occlusion-info |
CVE-2025-24073 | COcclusionContext::PreSubgraph | Overflow del buffer basato sull'heap/overflow del numero intero causato da un'errata verifica dell'input (CWE-20, che conduce al danneggiamento della memoria) | Lo stesso numero intero PreSubgraph attiva l'overflow del buffer occlusion-info |
CVE-2025-24060 | COcclusionContext::PreSubgraph COverlayContext::ComputeOverlayConfiguration | Errata verifica di limiti/input con conseguente scrittura heap fuori banda | Lo stesso numero intero PreSubgraph attiva l'overflow del buffer occlusion-info e un altro overflow |
CVE-2025-24058 (dwmcorei.dll) | CLocalAppRenderTarget::EnsureRenderSurface | UAF (Use-After-Free)/confusione sul tipo di percorso dovuta al passaggio di un puntatore oggetto libero come questo puntatore implicito (CWE-416, CWE-843) | Il puntatore CD3DDevice libero ha riutilizzato come CDeviceManager questa vulnerabilità |
CVE-2025-24058 (dwmcore.dll) | CLegacyRenderTarget::CollectOverlayCandidates COverlayContext::ComputeOverlayConfiguration | Overflow del buffer basato sull'heap derivante da un'errata verifica dell'input di lunghezze dell'elenco fornito dal chiamante (CWE-20, che porta alla CWE-122) | Overflow dell'heap tramite CollectOverlayCandidates |
CVE-2025-24062 | CCompositionSurfaceBitmap::AddOcclusionInformation CSurfaceBrush::AddOcclusionInformation | Troncamento del puntatore/errata verifica dell'input che porta ad un problema UAF (Use-After-Free)/elevazione dei privilegi (CWE-20, correlata alla CWE-704) | Argomenti ampliati a __int64; aggiunto IsOverlayCandidateCollectionEnabled() |
Più vulnerabilità e relative RCA eseguite tramite il modello LLM
La tabella illustra semplicemente il contenuto dei rapporti. La valutazione dei bug inclusi nell'aggiornamento di aprile 2025 rivela la duplicazione delle vulnerabilità CVE-2025-24074, CVE-2025-24073 e CVE-2025-24060, che si riferiscono tutte e tre alle stesse funzioni con modifiche o aggiunte minori.
CVE-2025-24058 (dwmcore.dll) sembra sovrapporsi alla CVE-2025-24060 di ComputeOverlayConfiguration. Le vulnerabilità CVE-2025-24058 (dwmcorei.dll) e CVE-2025-24062, tuttavia, sembrano derivare da cause di base completamente diverse.
Poiché il modello LLM non è un sistema deterministico, l'output può variare anche con un input identico. Possiamo osservare come le modifiche apportate nel contesto dell'input, a prescindere da quanto lievi, riescono ad influire sull'output del modello LLM e a generare due rapporti diversi.
I costi
Lo strumento PatchDiff-AI è basato su un'architettura controllata da più agenti con diversi modelli LLM, per ridurre i costi, mantenendo, al contempo, un'elevata precisione. Per generare un rapporto tramite i modelli OpenAI, sono richiesti al massimo 1,43 dollari.
In pratica, abbiamo generato 131 rapporti tra marzo, aprile e maggio, filtrati solo per Windows 11 24H2 x64, con un costo medio di circa 0,14 dollari per rapporto. Se si considera il numero di vulnerabilità che vengono affrontate ogni giorno (se non ogni ora), questi costi possono risultare notevoli in caso di cifre molto elevate.
Se sono abilitate le funzioni completamente autonome, ad esempio il perfezionamento di tutti i componenti interni di Windows e degli agenti di ricerca sulle vulnerabilità, i costi possono risultare ridotti; tuttavia, non si può stimare una media dei costi a causa della natura indeterministica del sistema.
Conclusione
Il futuro dell'utilizzo dell'intelligenza artificiale e, in particolare, dei modelli LLM nel settore della cybersecurity si prospetta roseo. I modelli LLM possono trasformare facilmente un processo molto complesso, ma metodologico in un workflow semplice da poter integrare nelle pipeline dei vari team addetti alla sicurezza.
La nostra ricerca dimostra che una RCA delle vulnerabilità completamente automatizzata non è solo possibile, ma anche pratica, perché offre una precisione significativa e costi ragionevoli.
Frammentando il problema in microattività e adattandolo ad un'architettura specializzata con più agenti che combina il perfezionamento dei componenti interni di Windows, i workflow di reverse engineering e l'analisi specifica delle vulnerabilità, abbiamo consentito ai modelli LLM di superare i loro limiti tradizionali. Questa pratica (insieme allo strumento complementare PatchDiff-AI) può essere anche applicata ad altri prodotti e piattaforme.
Utilizzando il nostro sistema, i team addetti alla sicurezza possono creare sistemi completi di rilevamento, mitigare efficacemente le vulnerabilità ed eseguire test di penetrazione e regressione per i loro sistemi. Inoltre, il nostro sistema può contribuire ad abbreviare il processo di attivazione delle vulnerabilità note, consentendo di eseguire ulteriori ricerche e di individuare le varianti nel codice condiviso delle vulnerabilità.

Tag


