

Serverless Storage at the Edge (EdgeKV Beta)


We are pleased to announce the beta launch of EdgeKV, Akamai’s distributed key-value store. EdgeKV is enabling technology for EdgeWorkers, our serverless computing platform that allows developers to create services using JavaScript and deploy them across our platform. When writing JavaScript, data persistence is often necessary to save data from a user interaction or retrieve contextual data to evaluate inside a function.
Until now, if an EdgeWorker required data, it was stored in the script itself, in a flat file, or retrieved via an expensive round-trip to a cloud or origin data center. Each of these options carries downsides: increased latency, commingling of data and code, and more maintenance. EdgeKV was purpose-built to address these issues by ensuring that data lives close to the user creating or consuming it.
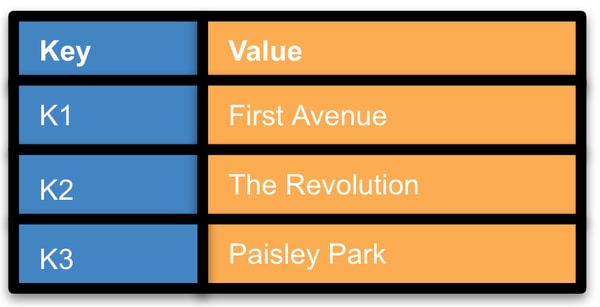
EdgeKV is a distributed key-value (KV) store designed to store unstructured or semi-structured data. A KV store does not have a schema or other defined relationships between entities. There is no complex query language or object-relational mapping (ORM). It acts like a dictionary: you look up a word and find its definition. A KV can be as simple as a two-column table where the values are simple strings (see Figure 1), or more complex where multiple layers of data are nested in a value.
As you might imagine, the lightweight nature of a KV store means that performance is a primary feature. KV stores also have great utility, allowing you to store many different data types as values: strings, arrays, sets, lists, nested JSON, or even base64-encoded binaries. This reduces development time and lets you build applications faster.
Akamai's KV store is fully distributed, ensuring that the data your EdgeWorker needs is an API call away, melting latency while providing high availability. You can be assured that your data is there.
EdgeKV was built for use cases that need to read data quickly and frequently, but write data infrequently. In distributed database parlance, this means that we use an eventual consistency model for writes and updates. If no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. The last client to write eventually "wins," and its value becomes globally consistent.
EdgeKV keeps a local copy of popular data on edge servers that are executing EdgeWorker code requesting that data. We leverage the Akamai delivery network to optimize the transfer of data between the persistent storage back end and the edge servers. When data is written or deleted, it is automatically invalidated on all edge servers that have a local copy. We use a publisher/subscriber-like approach to do the invalidation globally on all servers that have a local copy, while also maintaining an eventual consistency latency of 10 seconds or less for at least 80% of operations.
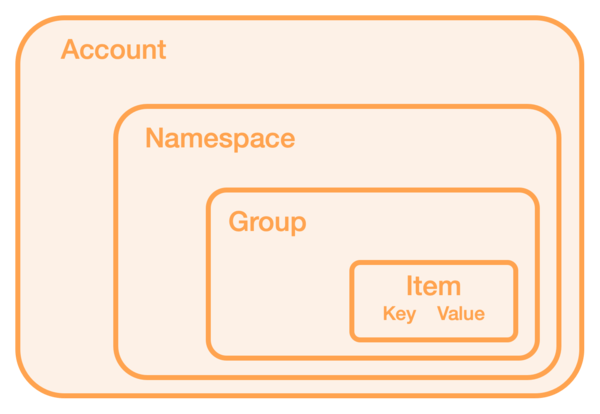
The EdgeKV data model is depicted in Figure 2. The lowest level of the model is a key-value pair, which is called an "item" -- item keys are alphanumeric, while values are discretionary JSON or string textual data. Items then roll up into groups, which are unlimited, developer-defined sets of related items. Groups are created "on the fly" as you create objects to populate them. For example, a group might be "the KV database for microservice XYZ" or "the KV database for website function ABC" -- the choice is yours.
These groups, in turn, roll up to namespaces, which are scarce resources in EdgeKV. Namespaces, while also logical containers of data, are meant to be more durable over time, changing infrequently. A namespace might be "the KV databases for the Asia-Pacific region" or "the KV databases for the widgets business unit". Namespaces also have a retention policy that can be set for automatic deletion of content.
The creation of namespaces is under the control of an EdgeKV Administrator, with privileges derived from your existing Akamai role-based access control.
Coding for EdgeKV could not be simpler. We have created an EdgeKV helper library that you can grab out of our GitHub repository. Once you write your EdgeWorker code, include the helper library and an EdgeKV Access Token (to authorize/control access to the EdgeKV data) in your tarball, and upload it to Akamai. Let's review a simple example.
A snippet of code (Figure 3) is placed inside your EdgeWorker main.js file. Here we instantiate a new EdgeKV object, setting the attributes of the namespace and group that hold the data we want. Once we have the object, an asynchronous request is sent to the database to retrieve the item with the name "key1" from the database in text form. Note that you could also have returned the data in JSON format with the method getJSON if the stored data was JSON.

Now that the EdgeWorker has the data from EdgeKV, it can use that information to compare the value of key1 inside a function. The EdgeWorker could just as easily have been coded in the other direction, writing a value into the EdgeKV store. It's that easy!
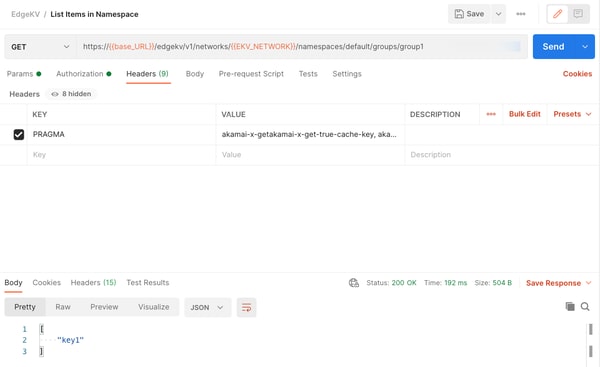
You may also control the database outside of EdgeWorker code via a rich set of administrative APIs. The APIs let you control all levels of the data model: list namespaces, add or delete data, and retrieve access tokens. And with our native EdgeGrid integration with Postman, it's easy to get started. In Figure 4, we retrieve the same key1 from group 1 via API call:
If you don't want to write code against our APIs, we have also created a command-line interface (CLI) to make day-to-day administration of EdgeKV easy. The CLI is tightly integrated with our existing EdgeWorkers CLI, giving you a single utility to control the operation of both products. The CLI is also scriptable, ensuring that automation mechanisms can make use of it. A sample of the CLI listing items from the same group1 is shown in Figure 5.

Responsive applications
EdgeWorker applications get low latency access to a distributed key-value store with EdgeKV. All database provisioning, maintenance, scaling, and data replication is handled by Akamai. You don't have to spend time operating a database -- spend time building your idea!
Key features of EdgeKV
High availability and low latency
Reads at cache speeds using Akamai's unmatched caching infrastructure
Reads and writes data from EdgeWorker code
Available globally on all Akamai edge servers
Administrative APIs for create, read, update, and delete (CRUD) operations against KV databases
Brings data close to your business logic
Existing EdgeKV Tech Preview users will see relaxation of imposed limits. For example, the maximum value size jumps from 100KB to 250KB, while the number of keys allowed jumps from 200K to 2M. These limit changes (and many more) are documented in the User Guide linked below.
If you are an existing Akamai customer, log into Akamai Control Center and select EdgeKV from the Marketplace app store under the Beta Products section. It will be provisioned on contract in minutes.
In the meantime, get started by reading our documentation, reviewing code samples, and installing the CLI at the links below:
