

Abusing the Service Workers API


The Service Worker web API is a powerful new API for web browsers. During our research, we have found several ways attackers can leverage this API to enhance their low-to-medium risk findings into a powerful and meaningful attack. By abusing this API, an attacker can also leave his footprint in the victim's browser and potentially leak sensitive information.
By the end of this post, you will have the basics of what are service workers, how they work and how attackers can abuse them to impact you.
Web browsers 101
Web browsers use JavaScript to run their logical code, which allows our websites to deliver interactive, high-end web applications. JavaScript is a single threaded language, meaning it executes code in order and must finish executing a piece code before moving onto the next.
Every tab in a web browser corresponds to a single JavaScript thread. That thread is usually referred to as the main thread. Because the main thread is a single thread, in a situation where CPU-heavy operations exist, this thread is blocked, and doing so causes degradation for the user experience.
Web workers
So, how can we maintain the user experience and run those heavy applications? This is where the Web Workers web API came in. Quoting the Mozilla Developer Network (MDN) - "Web Workers are a simple means for web content to run scripts in background threads. The worker thread can perform tasks without interfering with the user interface." This API grants us the ability to delegate our heavy tasks into another thread, while maintaining our thread responsive to UI changes.
The Web Worker API has most of the standard thread features available. First, it must be loaded from the same origin - loading from a different origin will fail to load the script. Second, the web worker context has no Document Object Model (DOM) manipulation rights. If a web worker desires to change something on the page, it has to communicate that to the main thread using the postMessage API.
While web workers are great for their own purpose, they have some architectural limitations that one might wish to overcome. First, they are bound to a single page - if we want to load a single web worker on a wide variety of pages, each and every one of those pages has to load it individually - which reduces maintainability. Furthermore, we would need to go over the installation phase every time, which impacts performance. Is there a way to overcome those limitations?
Service workers
This is where the Service Workers API comes in. A service worker is a web worker that can operate on multiple pages and have enhanced capabilities. It acts as a proxy between the web application and the network, so it can intercept network requests and process them. This is especially useful when we want to implement an offline experience for the website.
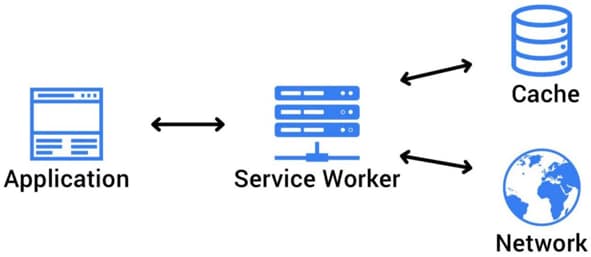
The service worker has a much longer lifespan than a web worker, since once it has been registered, it will reopen itself on every page under the defined scope. Even if we close the browser or shut off our computer - the next time we visit the website, the service worker will still spawn. This feature allows the service worker much more persistence than web workers.
This API is widely used on the Internet today.
Lifecycle
A service worker has a unique lifecycle:
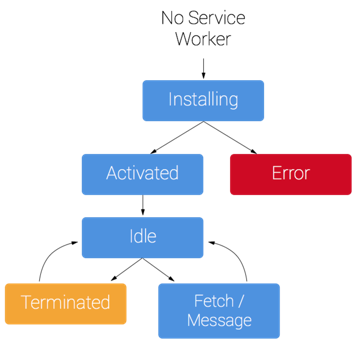
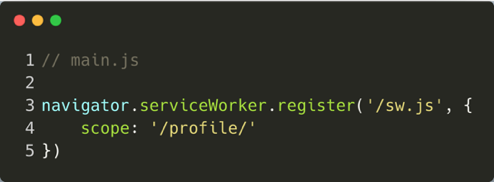
First, the service worker must be installed. This can be done using the "navigator.serviceWorker.register" method:

This function accepts as the first parameter the location of the file in the server - it has to be a physical file. This function returns a promise, when resolved we get information on the registration scope.
The Scope
The scope is a crucial concept of service workers. It determines what path the service worker will be activated on. It is the activation condition of the service worker:
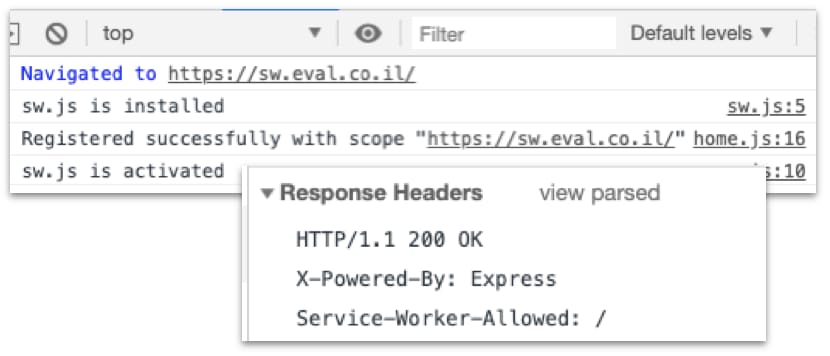
In the example above, the scope is set to be /profile/, which means every web page under this file hierarchy will load this service worker. Any file higher than that scope (for example /), will ignore this service worker.
By default, the scope is defined as the path where the service worker JavaScript file resides. It can be easily reduced, as demonstrated in the example above, and it can also be increased. To increase the scope, the server needs to respond with a special response header called "Service-Worker-Allowed":
There are some strange behaviors when it comes to the scope of a service worker. For starters, only a single service worker can operate at a time, within a single page. If there are two registered service workers under the same scope, the most recent registered one will be activated. If there are two registered service workers on an overlapping scope, the most specific one will be activated.
A service worker can also import other scripts using the "importScripts" function. This is how attackers load malicious service workers while maintaining the original service worker functionality (if the website being targeted already has a service worker). Once again, the imported script has to be from the same origin.
Installation
Once the browser has successfully registered the service worker, the "install" event occurs:
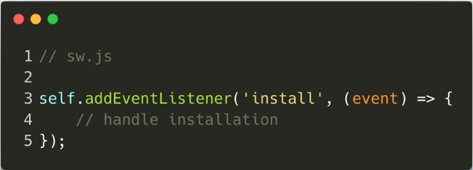
The install event also occurs when the browser identifies that the content of the script has changed and where caches can be opened for later file storage.
Activation
Once the installation event is successful, the "activate" event triggers:
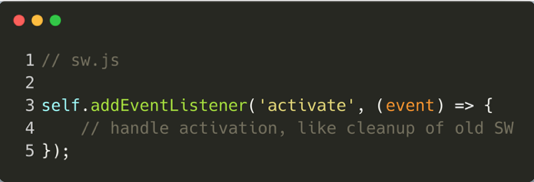
This event is the perfect place to handle the cleanup of older files in the cache. This is done in order to prepare the cache to be filled later on. An important note: opened pages are not controlled by the newly-registered service worker, they must be reloaded. In order to override that behavior, the "self.clients.claim" function can be used, which claims rights on those pages.
Fetch Event
Once the bureaucratic events are complete, it is possible to start listening to the interesting events - such as the "fetch" event. This event triggers every time a resource is requested. The service worker has control over what is being requested and, more importantly, what is being responded with (headers, status, body):
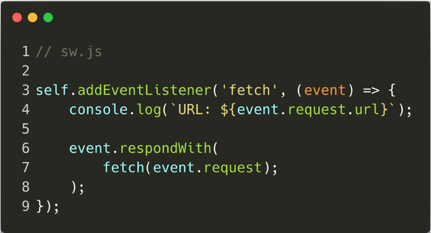
As mentioned above, the service worker API works well at enhancing the experience of web users. However, it can also be used by attackers to enhance their footprint on victims' browsers and amplify their attacks.
Response modification
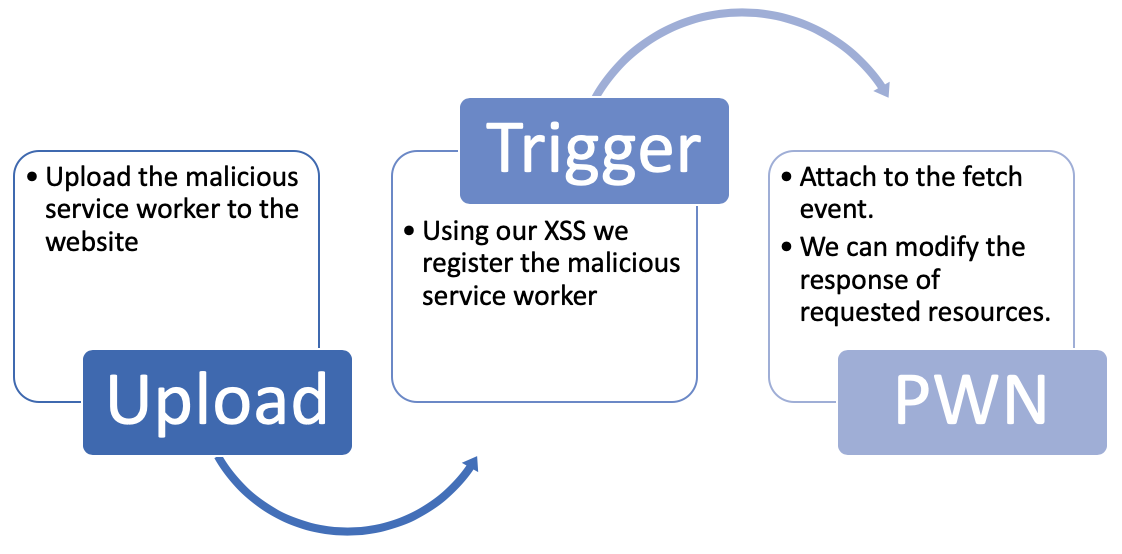
The first category of attacks is called "Response Modification." All of the following scenarios in this category ultimately rely on the fact that once the attacker attaches to the fetch event, he has control over the requested resources. This way, the attacker can manipulate the response body, serving the client whatever he desires.
The scenarios in this category depend on the following:
If the targeted website has a file upload functionality - an attacker can upload arbitrary files (more specifically JavaScript files) and he can retrieve them.
If there's a Cross Site Scripting (XSS) vulnerability in the application - the attacker can inject and execute arbitrary JavaScript code in the context of the victim's browser.
XSS Persistency
An attacker can gain the ability to persist in pursuing his XSS attack, which could be reflected or stored. Either way - the attacker can extend the attack much further than before. Once the victim requests a page (under the service worker scope) the attacker can append to that page the malicious payload, resulting in the XSS to roll out to every corresponding page.
Denial of service
An attacker could also gain the ability to deny requested resources from the victim. Once the victim requests a certain resource the attacker can hijack that request and serve a 404 not found response, resulting in local denial of service.
Phishing / defacement
Ultimately, an attacker can also gain the ability to modify the response of the requested resource, resulting in a phishing or defacement attack. Let's assume the victim has navigated to a login page. Once the victim navigates to the page, the attacker will change the URL of the login and then reroute the victim through the attacker's malicious servers (instead of the legit ones). This way, the attacker will get the victim's credentials.
Data leakage from sandboxed domains
Sandboxed domains are domains that are different from the main application. They are generally used to host various types of files (images, audio, videos, scripts, etc.). They are meant to isolate user uploaded content from the main application. Files on the sandboxed domain are usually available publically.
You might think, how is that possible? Well, they rely on the fact that the filenames are heavily obfuscated, so that they do not resemble the file content nor the owner. As a result, attackers will have a hard time guessing the sensitive URLs. Many vendors tend to ignore XSS findings on those domains, since no cookies are shared across the sandboxed domain and the main application. Some examples for sandboxed domains include googleusercontent.com (Google) and fbcdn.com (Facebook).
Imagine a website that handles sensitive information. We'll call it example-photos.com. Files uploaded to this website are stored on a sandboxed domain called example-photos-sandbox.com, but unfortunately this domain has an XSS vulnerability.
Attack flow
First, the attacker uploads his malicious service worker. This is possible because the sandboxed domains usually are designed to store uploaded content. Then, the attacker triggers the XSS on the victim. This XSS will register the malicious service worker and install it. Now - when the victim previews an image, it triggers a navigation to the sandboxed domain, which in turn will activate the service worker. Since the attacker has control over requested resources, he can exfiltrate the sensitive URL to his own controlled server.
Enhancing self-XSS
For this scenario, consider the following details: here is a website with a file upload functionality. Along with that, there is also a self-XSS finding (low impact) on a page, i.e. the /profile page. A self-XSS is essentially an XSS that is triggered only on pages that are visible to the user themselves. The website also suffers from a Login / Logout CSRF. As a side note - login and logout functions are rarely protected by CSRF tokens.
Attack flow
First, the attacker uploads the malicious service worker to the website (using the file upload functionality). Then, he tricks the victim to visit the attacker's controlled page. That page has an iframe that will cause the user to logout, and login again as the attacker (using the attacker credentials). Once the user is logged in, the attacker will redirect him to the /profile page, thereby triggering the self-XSS. In turn, the XSS payload will register the malicious service worker and log him out again.
In this stage, the user is logged out from the system. When the user tries to log in again, the malicious service worker will kick in on his user context, resulting in a persistent XSS (in contrast to the self-XSS we had before)
Caveats
Although these scenarios look promising, the attacker is still bounded under the following restrictions:
Scope - if the uploaded service worker resides deeper in the file hierarchy than the page the attacker wants to inspect, it won't have any impact on it.
MIME type - the uploaded service worker file must be served with the correct JavaScript MIME type, for example - "application/javascript".
Now that we have covered what can go wrong, it's time to see if there's anything we can do about it to mitigate the issue.
Scope enforcement
One viable solution could be to set the uploaded files depth deeper in the tree. This way, if an attacker is targeting a website, a malicious service worker would have less impact on a victim. In the sandboxed domain - pick a unique path hierarchy for every file. Try to involve timestamps or random strings in the filename.
Generally, try to refrain from using "/" as the general scope for JavaScript files (with the Service-Worker-Allowed response header). This causes a global activation-condition for any uploaded JavaScript file. One could also monitor requests from the "Service-Worker" request header. When the browser tries to register a new service worker, it will append that header to the request. Look for any uncalled for requests with that header.
Real user monitoring
Real user monitoring (RUM) is a passive monitoring technique that records all of a web application's user interaction with the application. It can be used to measure a client's web experience and performance. When you observe a very poor performance on a specific client, one of the reasons could be a local denial of service caused by a rogue service worker.
Browser events monitoring
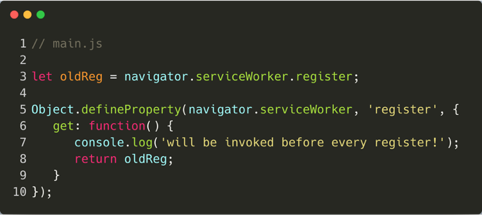
In the browser, it is possible to "monkey-patch" functions. This term refers to replacing the original behaviour of functions with custom behaviour. It is possible to monkey patch the register function for new unauthorized registration events. This mitigates malicious service workers, because control over the register function invocation can be used to deny any registration to an unauthorized service worker:
Service workers are an excellent API that grants game changing features for some websites. Having said that, the risks they introduce to users can't be ignored. As citizens of the web, it is vital to be familiar with the ever growing capabilities of the web browsers, along with the risks they expose.

