
Fog Computing vs. Edge Computing: Their Roles in Modern Technology


Contents
Background
Over the years, computing paradigms have shifted to meet the needs of the moment — evolving alongside technology. The emergence of cloud computing was revolutionary. Instead of relying on substantial hardware to perform computing tasks, companies and individuals could now process, store, and analyze data on fully virtual cloud servers via the internet.
Cloud computing offers significant advantages over traditional computing processes, including scalability, flexibility, and the ability to access data from any location with an internet connection. Major tech companies, such as Microsoft and Amazon, have emerged as leading cloud service providers, offering computing services through a pay-as-you-go model. This approach allows individuals to access data storage and processing power from a public cloud, paying only for the resources they use.
The evolution from cloud computing to edge and fog
While cloud computing remains a valuable and widely adopted method, the rapid expansion of the Internet of Things (IoT) has illuminated some of its limitations, leading to the emergence of new paradigms like edge computing and fog computing. The IoT refers to the rapidly growing global network of smart devices — such as phones, toothbrushes, and autonomous vehicles. As these devices multiply, so does the volume of data we generate collectively.
Centralized data centers are often located hundreds, if not thousands, of miles away from end users. As more data is transmitted to these distant locations, network traffic increases, leading to issues like congestion, latency, and bandwidth constraints.
Key similarities: Fog computing vs. edge computing
Edge computing and fog computing move processing capabilities closer to the network edge, where the physical and digital worlds converge. By bringing insights and decision-making capabilities closer to devices and end users, rather than relying on centralized clouds that could be far away, fog and edge computing reduce latency, optimize bandwidth, and meet the demands of modern technology.
Demystifying fog and edge computing: How they transform data processing
What is fog computing?
The term “fog computing” was coined by Cisco in 2012. With the goal of bringing computing resources and processing power closer to IoT devices, Cisco and other providers began creating fog computing ecosystems, in which data is processed by fog nodes situated between the cloud and the network edge.
Fog computing relies on strong connectivity between fog nodes and end devices, as well as between fog nodes and the cloud. Fog nodes are capable of real-time processing, which can be seen in action in applications like smart cities and healthcare monitoring systems. Additionally, fog nodes can offload non–time-sensitive processing tasks to centralized data centers.
This approach offers benefits like reduced latency and bandwidth use, which are typical of local processing, while still allowing access to cloud resources for more complex tasks. Because of these advantages, the fog computing market, valued currently at US$372.9 million, is projected to grow at a compound annual growth rate of 50.8% from 2024 to 2030.
Edge computing: Definition and key characteristics
Edge computing is a structure that brings data processing all the way to the edge of the network (Figure). Within the edge computing architecture, computing resources called edge nodes are placed on or extremely close to edge devices.
By storing and processing data locally, these edge nodes allow device end users to gain benefits like real-time processing and low latency. Because edge computing allows data to be processed locally, and only sends essential information to the centralized cloud, it significantly reduces bandwidth use and minimizes network congestion.
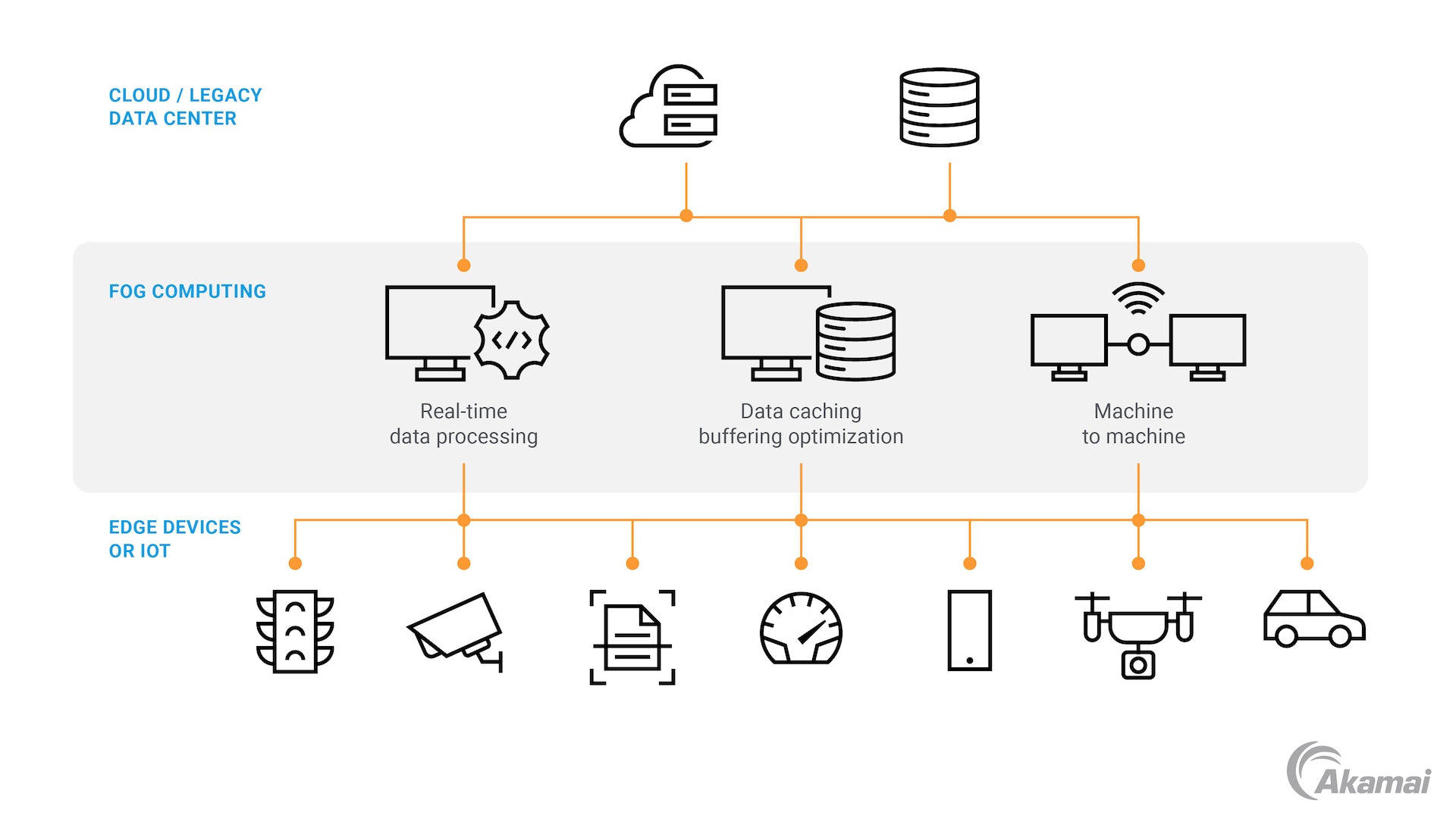 How fog computing works
How fog computing works
Edge computing is likely already a part of your daily life. It’s the structure that enables you to instantly check your bank balance on your phone, shop online, or play a video game without constant buffering. Other notable use cases include wearable medical devices, autonomous vehicles, IoT sensors, and predictive maintenance features.
Key differences: Fog computing vs. edge computing
Fog computing and edge computing are both distributed cloud computing models. They each bring data processing closer to the devices generating the data, but there are some key differences between the two.
Comparative analyses
One major difference is the location of each structure’s nodes. Edge nodes are stationed directly on or very near to the devices that are generating data. Fog nodes are located between the devices and the centralized cloud, making them farther from data sources but closer to the cloud than edge nodes.
There are also differences in computing power. Edge nodes can only perform data processing locally, for one given device. This means that edge nodes can make immediate decisions based on local data. Fog nodes, on the other hand, can carry out more complex decision-making tasks than edge nodes, as they’re able to aggregate and analyze data from multiple edge devices.
Performance metrics
While both structures are known for reducing latency and helping to conserve bandwidth, edge computing delivers faster response times than fog computing, allowing for real-time data processing that enhances the user experience. This is due to the edge node’s extremely close proximity to data sources.
Cybersecurity: Threats and prevention
Fog and edge computing offer security advantages over traditional cloud computing. However, as is the case with any system that involves the transfer of sensitive data, both fog and edge computing are susceptible to cyberattacks.
Fog and edge computing environments with weak security postures can be subject to distributed denial-of-service (DDoS) attacks, eavesdropping, authentication issues, and more.
Fog nodes’ positioning between the edge and the cloud, rather than directly at the edge, means that fog computing offers up a slightly larger attack surface than edge computing. This location can make fog computing environments particularly vulnerable to machine-in-the-middle attacks, in which threat actors intercept information as data transfers between fog nodes.
Because of these vulnerabilities, it’s imperative to have adequate security measures in place. As a Leader in network edge security, Akamai uses strategies like Zero Trust, real-time monitoring, and multiple layers of security features to mitigate threats. These advanced security measures are baked into Akamai’s edge computing solutions.
Integrating fog into edge computing
In the evolving IoT ecosystem, fog computing can enhance edge computing capabilities. Because of this synergy, many devices use fog and edge computing together to manage data more effectively.
Consider this example: A patient wears a heart rate monitor. If their heart rate goes up, edge computing ensures they receive a real-time alert. Then, data can be sent to a fog node for more complex processing.
The fog nodes aggregate data from other devices, perhaps combining heart rate information with other vitals for a more comprehensive health analysis. The fog node then further filters data, transmitting only what is necessary to the cloud, thereby reducing network congestion and adding an extra layer of security.
Choosing between fog and edge computing
If you’re choosing between fog and edge computing, here are a few factors to consider:
Amount of data: Edge computing excels in applications that generate small amounts of data that can be processed locally. In contrast, if your application requires large volumes of data to be aggregated from multiple sources, fog computing is more suitable.
Sensitivity of data: Edge computing offers the best security for highly sensitive data, as it processes data entirely locally.
- Required response time: For time-critical applications that require real-time processing, edge computing is unmatched. However, if your application includes more complex, less time-sensitive elements, fog computing can give you a balance between reduced latency and broader analysis.
The future of IoT and computing paradigms
Just as computing paradigms have evolved over time to address the needs of new technological developments, modern computing infrastructure will continue evolving to meet the growing demands of IoT.
Statista predicts that the number of IoT devices will nearly double from 15.9 billion in 2023 to more than 32.1 billion in 2030. Because IoT devices require real-time processing and low latency to operate effectively, we’re likely to see a large shift toward the adoption of edge computing. With more devices comes more data generation. By shifting to edge computing and processing this data locally, companies can optimize bandwidth and keep costs down.
Why Akamai’s edge computing solutions stand out: Unlocking efficiency and innovation
More than any other computing paradigm, edge computing puts users closer to real-time experiences and keeps threats farther away.
Akamai’s edge computing solutions allow you to innovate in real time. With the world’s largest intelligent edge platform, Akamai puts your applications closer to your users to boost performance and improve user experience. Plus, Akamai integrates its industry-leading advanced security measures directly into its edge solutions, safeguarding your data from cyberthreats.
Learn more about cloud, fog, and edge computing
Explore these additional resources and readings to deepen your understanding of computing paradigms.
