
The Rise of the LLM AI Scrapers: What It Means for Bot Management




Contents
Large language models (LLMs) and generative AI (GenAI) have dominated business conversations in recent years. Discussions have centered on how they work, where they get data, use cases, possible ethical issues, and their potential impact on businesses and individuals.
LLMs are powerful AI models that can understand and generate text. Today’s market features several well-known LLMs, including ChatGPT, Llama, Claude, Copilot, Grok, and more recently, DeepSeek, in addition to a slew of new models from emerging start-ups — and the competition to outperform rivals on key benchmarks has been fierce. It seems that each week or so a different LLM is claiming the lead.
Large language models and web scraping
To successfully generate human-like writing, LLMs must first be trained on vast datasets. Much of the training materials are composed of scraped data obtained from web pages, code repositories, social media, and other online sources.
LLMs obtain this web data through an automated data extraction process called web scraping. To carry out this process, organizations use special open source or commercial web scraping tools, like Firecrawl, Beautiful Soup, and ScrapeGraphAI, to extract data from websites, parse it, and format it into structured data that can be used to train the LLM.
The state of web scraper bot traffic: Key trends and findings from our data
LLMs span the furthest reaches of the internet in their data collection quest, scraping whatever content they can to make their models as insightful as possible.
Initially, the Akamai team thought that most AI-powered web scraping would happen only during predictably timed and relatively infrequent training runs, and that we should therefore expect to see predictable and infrequent spikes in scraper bots traffic across Akamai’s network.
Our findings surprised us.
Akamai’s bot management team began tracking and managing AI web scraping activity across our customers’ networks in November 2024, and we have some findings to share.
AI scraping accounts for 0.1% of daily traffic across the Akamai network (Figure 1). In other words, the network receives more than 1 billion requests each day, and more than 600 million of these are handled by our application security (AppSec) protections. The percentage alone may seem small, but a total volume of 600 million is impressive for a newly defined bot category.
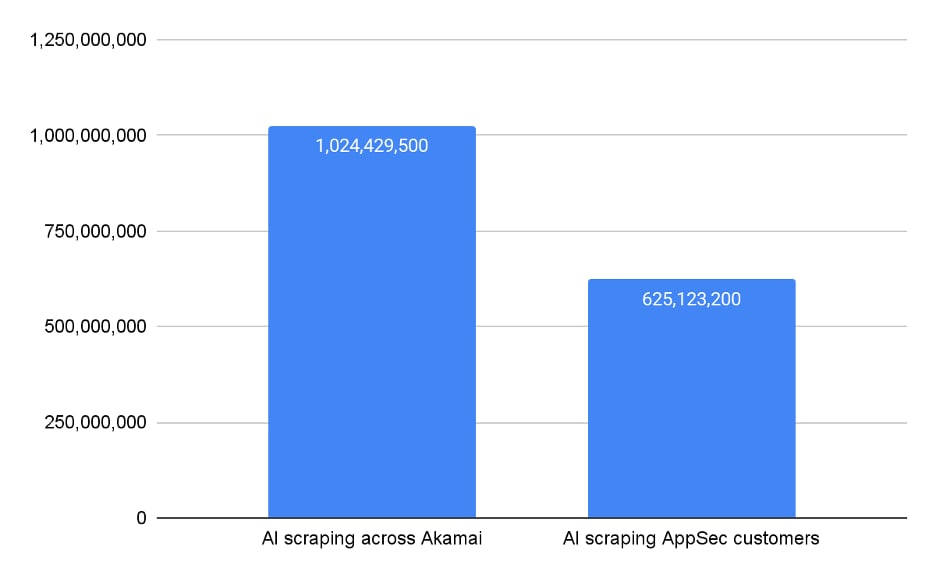 Fig. 1: AI scraping requests across all Akamai and Akamai AppSec customers on April 7, 2025
Fig. 1: AI scraping requests across all Akamai and Akamai AppSec customers on April 7, 2025
Web scraper traffic continues to rise
We continue to see a rise in activity from LLM scrapers, even after accounting for increases in the number of companies on the Akamai network. Figure 2 shows the steady rise in traffic that took place between March 9, 2025, and April 6, 2025.
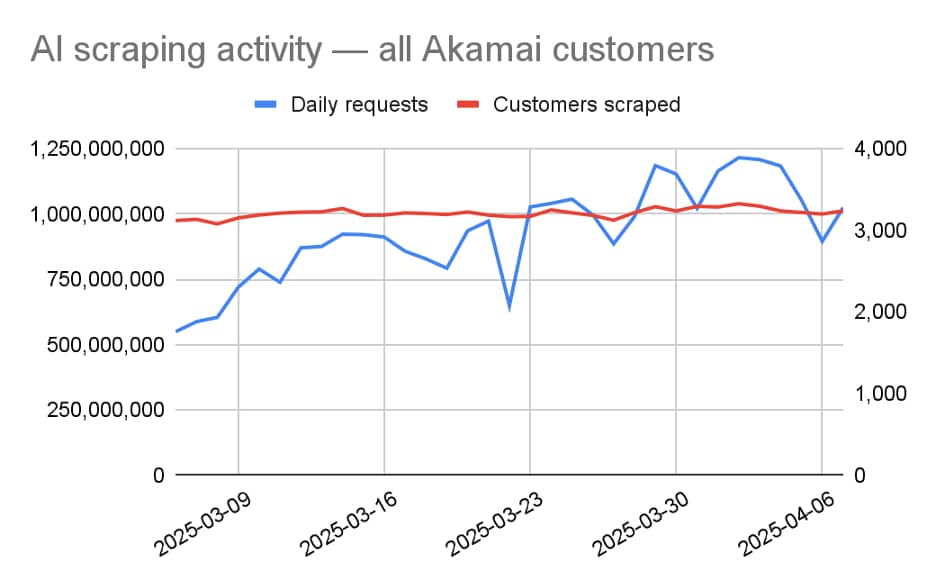 Fig. 2: Number of daily AI scraper requests across all Akamai customers
Fig. 2: Number of daily AI scraper requests across all Akamai customers
How web scrapers introduce themselves — and why it matters
Generally, these AI scrapers are good internet citizens and self-identify in the user agent, as shown in Figure 3. Some even complement that information with a second factor, offering network data such as a list of IPs, dedicated ASN, or reverse DNS entries.
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot) Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) Mozilla/5.0 (compatible; WARDBot/1.0; http://ward.ai/robot) Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot) Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.6943.53 Mobile Safari/537.36 (compatible; Google-CloudVertexBot; +https://cloud.google.com/enterprise-search) Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; WRTNBot/1.0; +https://wrtn.ai/WRTNBot) Mozilla/5.0 (compatible; KunatoCrawler/1.0; +http://kunato.ai/bot.html) meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)|LANG:en,COUNTRY:ie,CITY:clonee,CLIENTIP:0.0.0.0 Mozilla/5.0 AppleWebKit/605.1.15 (KHTML, like Gecko; compatible; iAskBot/1.0; +https://iask.ai/) Chrome/124.0.6367.171 Safari/605.1.15 |
Predictably, OpenAI (ChatGPT), Meta (Llama), Anthropic, and Google (Gemini) are pushing the growth in scraper activity, as seen in Figure 4.
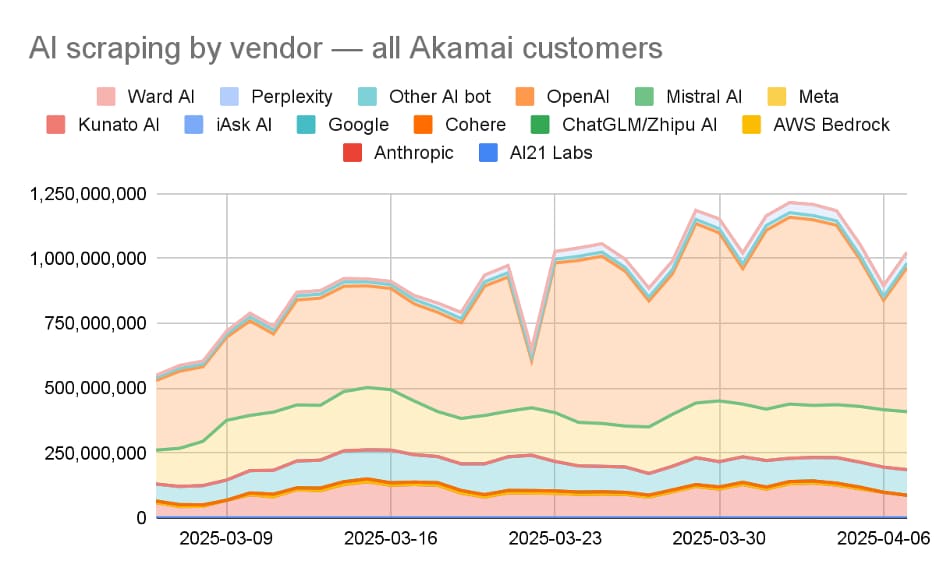 Fig. 4: Scraper activity by AI/LLM vendor
Fig. 4: Scraper activity by AI/LLM vendor
We observed some instances of LLM impersonation, in which nefarious actors set their user agents to known LLMs in an attempt to bypass bot detections. Luckily, our bot detections rely on additional signals, and we can easily filter out faux AI agents and LLMs.
AI web scraping trends by industry
Let’s take a closer look at the data, focusing on our application security customers, whose web apps, native mobile apps, and APIs we protect.
Commerce led in early web scraping growth
The first big bump in requests targeted our commerce (retail, travel, hospitality) customers.
It makes sense that commerce customers saw the initial brunt of AI web scraping, as inventories and pricing (not to mention wide product catalogs) are constantly changing, forcing LLMs to revisit them often to obtain accurate, up-to-date information. Still, this level of activity was not the sort of “training run only” scraping that we’d initially envisioned.
Figure 5 is an illustration of scraper traffic by industry that was observed over the course of several months. As you can see, the traffic begins primarily in commerce, but picks up in other industries as time goes on.
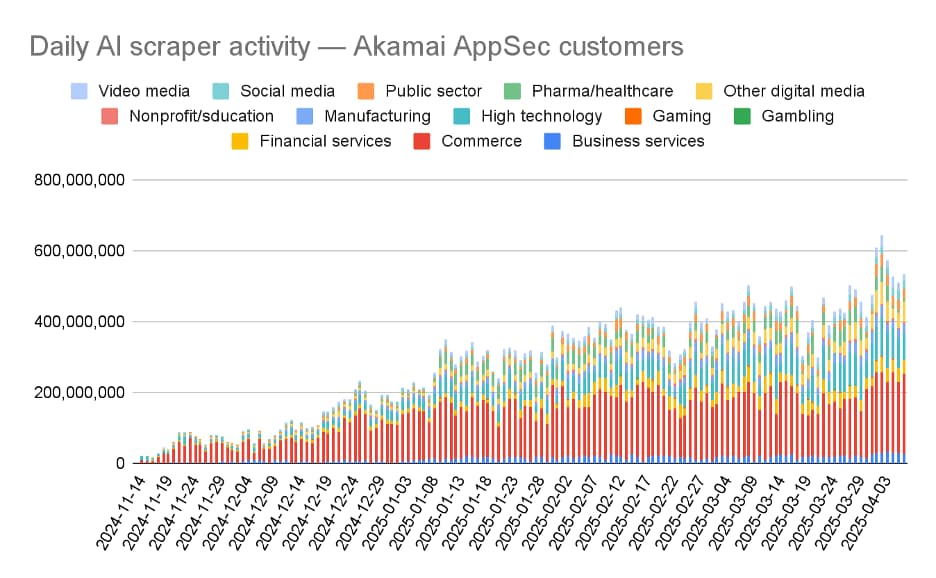 Fig. 5: AI scraper request volume by industry
Fig. 5: AI scraper request volume by industry
AI web scraper traffic is rising across industries
Given the fast start in AI scraping that’s targeting our commerce customers, we were surprised by the changes we’ve seen since the start of 2025. Akamai’s customers across industries such as business services, gambling, and healthcare are now far outpacing the growth we see in commerce.
Figure 6 shows that although our commerce customers may have had the early lead in AI scraping, they’re now among the lowest in AI scraping growth (albeit at a respectable 2.6x year-to-date rate).
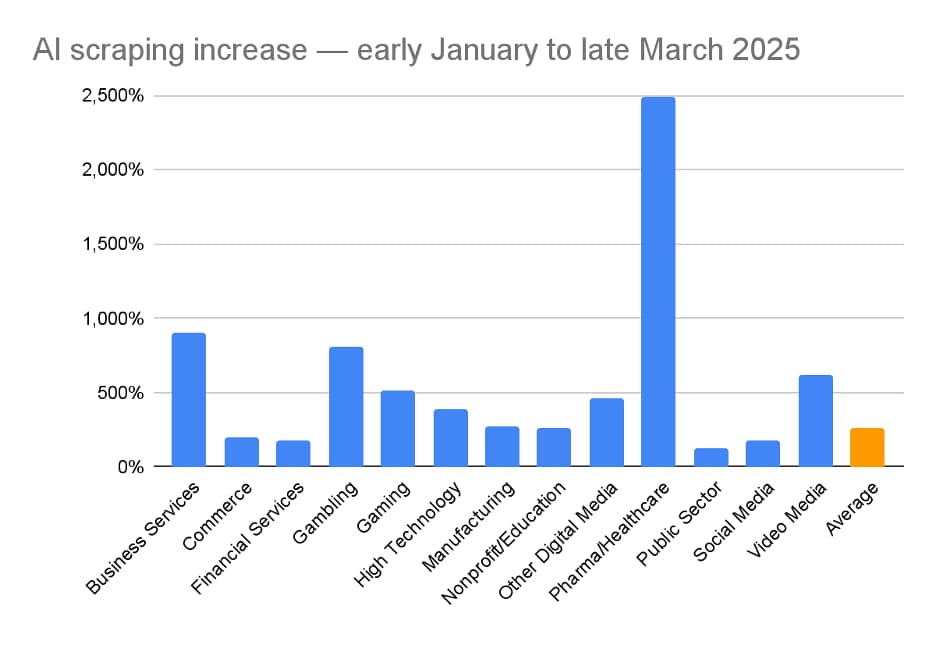 Fig. 6: Percentage of growth in AI scrapers by industry
Fig. 6: Percentage of growth in AI scrapers by industry
Other players in web scraping: The rise of AI agents and RAG
The growing popularity of AI agents and retrieval-augmented generation (RAG)–enabled LLMs is also driving web scraping bot traffic.
RAG is a technique that supplements an LLM’s or AI agent’s own knowledge with external information gathered in real time. RAG is often integrated into workflows like customer support automation, allowing chatbots to quickly pull up accurate information from a company’s product catalog or FAQ.
AI agents (IBM WatsonX, OpenAI Operator, Copilot Agent) and RAG-enabled LLMs (Google Gemini, Llama) have become popular recently due to their ability to automate routine tasks and increase efficiency. However, unlike LLMs, agentic AI often needs to augment training data with outside sources in real time. As a result, queries to these agents drive increased bot requests.
We expect that the continuous scraping of agentic AI will exponentially increase bot traffic.
Unlike humans using Google or another search engine, an agent is running multiple queries in parallel, which leads to a large increase in requests. One question to a RAG LLM or AI agent can spawn many requests across the internet.
According to LLM researchers, each user or agent request can fire in upwards of 100 scraping requests, which creates the potential for a massive increase in traffic toward sites frequently referenced by LLMs and their agents. Half the time, people don't even know they're using AI.
How AI agents collect information: A real-life example
To show how AI agents behave in action on queries beyond their training dataset, we used the new LLM reasoning and explainability features of Google’s Gemini. In addition to answering our initial question, Gemini told us what sources it uncovered, how it prioritized them, what key information it found, and how it validated and weighted the information (Figure 7).
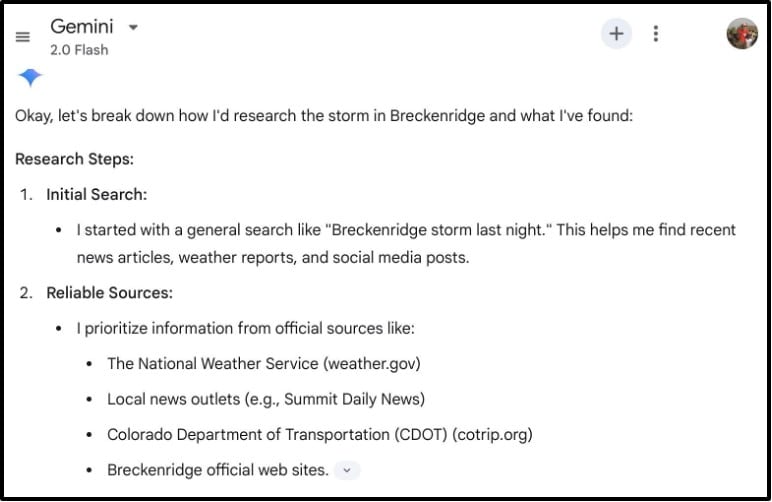


 Fig. 7: Google Gemini AI agent responds to our prompt and explains its research process
Fig. 7: Google Gemini AI agent responds to our prompt and explains its research process
As you can see, when asked about its reasoning, the AI agent told us the steps it took to answer our question, explaining how it extracted and synthesized information from a wide range of sources to come to its conclusion. This ability to engage in real time, interfacing with the broader internet, is blurring the line between LLMs and traditional web search.
How to address the rapid increase in AI scraper volume: Tips and strategies
Even if you consider AI web scrapers to be good bots and you don’t want to block them, high bot traffic volume can cause a number of issues such as performance degradation, increased CDN and cloud costs — and create a poor user experience for humans who visit your site or application. As the volume of bot traffic increases, these problems will only worsen.
To ensure that your organization isn’t harmed by growing bot volume, you can:
Implement strong bot management tools and protocols to gain visibility into your AI scraper traffic and unlock new strategies for responding to bot requests.
Decide which AI scrapers you want to allow into your site. It’s common practice to permit well-known scrapers, or those affiliated with companies your organization has a relationship with, while limiting others.
Create conditional actions within the AI category based on your decisions about each scraping vendor. For example, you may have already decided to allow well-known LLMs to scrape your site, but what about all the others? You can block them outright, slow them down, allow them only during times when human user traffic is light, or do some combination of the preceding actions.
Use reporting insights, like those from Akamai’s web security analytics, to find patterns and trends that drive future decisions about how you want to address changes in AI scraper activity.
Protect your content and optimize site performance by managing web scraper traffic
Akamai’s suite of bot and abuse protection solutions gives you visibility and control over how LLM web scrapers interact with your websites and applications. With advanced bot detection and customizable management tools, these solutions help protect your content from unwanted scrapers while preserving site performance and user experience.
