
大規模言語モデル(LLM)は、ディープラーニングを使用して人間の言語を処理および生成するAIの一種です。ディープラーニングは、データのパターンを認識するようニューラルネットワークをトレーニングすることでLLMを強化する、より広範なテクノロジーです。生成 AI とは、テキスト、画像、コードなど、新しいコンテンツを作成できる AI を指します。LLM は、テキストベースの生成に重点を置いた具体的な例です。
大規模言語モデル(LLM)は、人工知能(AI)の最も革新的な進歩の1つです。この強力なツールにより、機械はかつてない規模と深さで人間の言語を処理、理解、生成できます。LLM は、質問への回答、テキストの翻訳、ChatGPT のような会話型 AI の作成など、私たちの世界を形成する生成 AI テクノロジーの中核となっています。
大規模言語モデル:定義
大規模言語モデル(LLM)は、人間の言語を理解して生成するために設計されたAIモデルの一種です。ニューラルネットワーク(特にトランスフォーマーアーキテクチャを備えたネットワーク)を使用して構築されたLLMは、膨大なテキストデータセットでトレーニングされます。自然言語のパターン、構造、意味を学習し、要約、テキスト生成、感情分析など、言語ベースのさまざまなタスクを実行できるようにします。LLM の最も有名な例には、OpenAI の GPT-4 と GPT-5、Google の Gemini、Meta のLlama、Microsoft の Copilot などがあります。
大規模言語モデルの主要コンポーネント
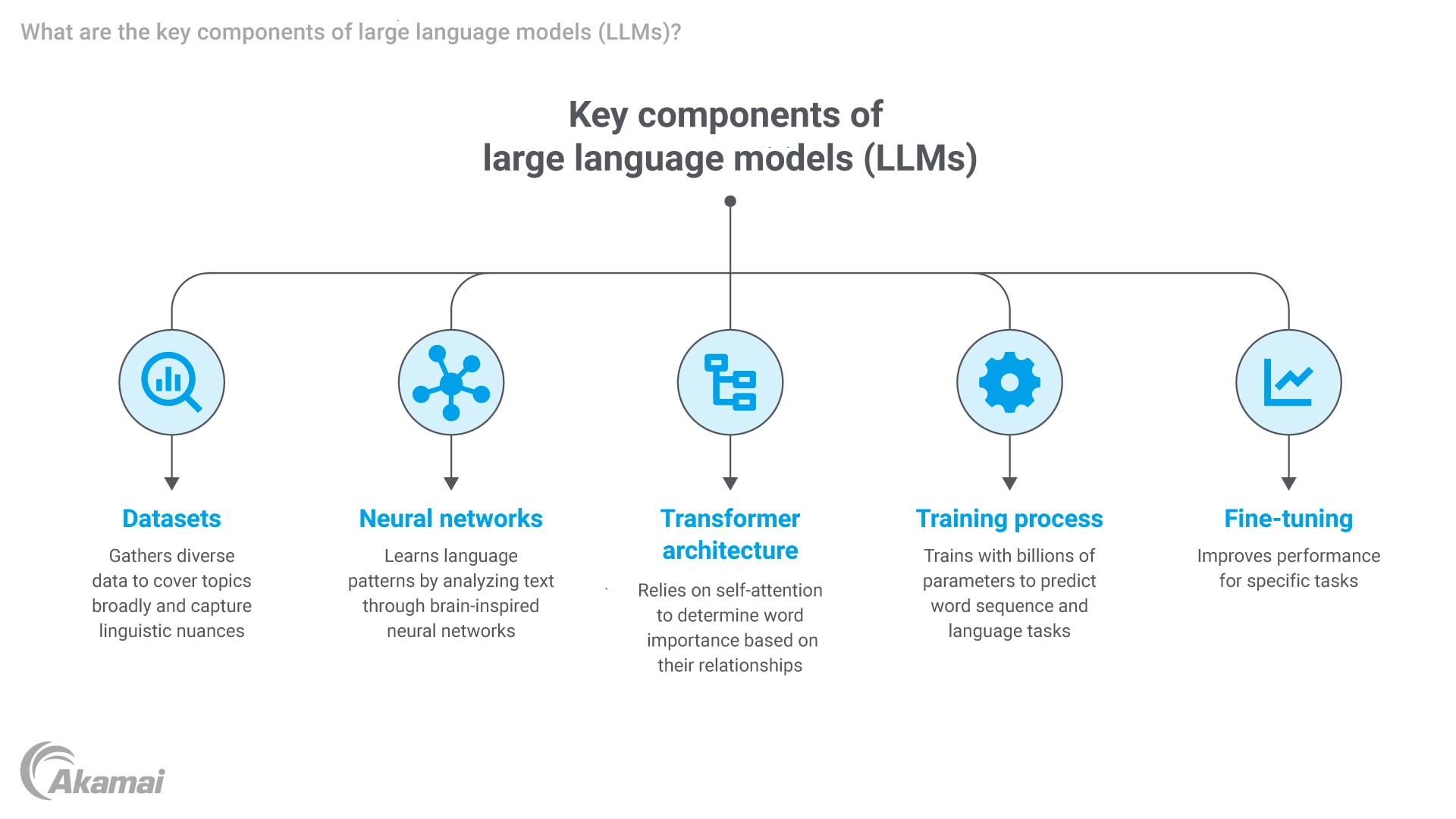
LLMは、いくつかの重要なコンポーネントとテクノロジーに依存しています。
- データセット:LLMは、書籍、Webサイト、記事などから収集した何兆もの単語を含むことが多い大規模なデータセットでトレーニングされています。これらのデータ収集により、トピックを幅広くカバーし、言語的なニュアンスを理解するようになります。
- ニューラルネットワーク:ニューラルネットワークは、人間の脳と同様に機能するように設計された機械学習モデルの一種です。ニューラルネットワークは、データを処理して分析する相互接続されたノード(人工ニューロン)で構成されています。大規模言語モデルでは、ニューラルネットワークが膨大な量のテキストを処理することで、言語の仕組みの学習を支援します。
- トランスフォーマーアーキテクチャ:ニューラルネットワークの強力なモデルであるトランスフォーマーアーキテクチャは、テキストの理解と使用に非常に長けています。トランスフォーマーモデルは、自己注意と呼ばれる方法を使用して、文の中のどの単語が他の単語との関係に基づいて最も重要であるかを理解します。
- トレーニングプロセス:大規模言語モデルは、シーケンス内の次の単語を予測したり、他の言語タスクを実行したりするのに役立つ数十億から数兆のパラメーターが関与する厳格なトレーニングプロセスを経ます。
- ファインチューニング:トレーニング後、LLMは多くの場合、特定のタスクやドメイン固有のデータセットに応じて微調整され、特定のユースケース向けにパフォーマンスを向上させます。
大規模言語モデルの仕組み
大規模言語モデルは、言語を理解し、パターンを学習し、有意義な応答を生成するためにいくつかのステップを実行します。
- 自己注意:この概念は、LLMがコンテキストを理解するための鍵となります。モデルが文や文書を読み取るとき、注意メカニズムはすべての単語の関係を調べて、すべての単語を等しく扱うのではなく、どの単語が最も重要であるかを判断します。これは、モデルがコンテキストを理解するのに役立ちます。
- 埋め込み:LLMは、人間のように単語を直接操作するのではなく、埋め込みと呼ばれるプロセスを使用して単語を数値に変換します。これらの数値は、単語の意味と他の単語との関係を捉えています。この数値形式により、モデルは言語を簡単に処理して理解できます。
- トレーニング:LLMはトレーニング中に、文中の次の単語を予測することで、言語の仕組みを学習します。これは、次単語予測と呼ばれます。たとえば、「太陽は___」とある場合、モデルは「輝いている」または「明るい」と予測することを学習します。このプロセスを数十億から数兆の例で繰り返すことで、言語のパターン、文法、構造を学習する。
- 最適化:モデルのトレーニング中に、パラメーターと呼ばれる数百万から数兆の小さな設定を調整して、ミッションをうまくこなせるようにします。この最適化と呼ばれるステップにより、大規模言語モデルは時間の経過とともにより正確かつ効率的になり、複雑な言語シナリオや異常な言語シナリオにも対応できるようになります。
- 推論:この段階では、大規模言語モデルは蓄積された知識を使用して正確な回答を生成したり、有益なアクションを実行したりします。ストーリーを書いたり、記事を要約したり、文を別の言語に翻訳したりすることがあります。
大規模言語モデルのユースケース
大規模言語モデルは、多くのタスクやテクノロジーに革命をもたらしてきました。
- 会話型AI:大規模言語モデルは、ChatGPT や Bard などのシステムを強化することで、会話型 AI の進歩を促進しています。これらのツールは、カスタマーサポート、仮想アシスタント、教育アプリケーションに自然なコンテキスト認識型のインタラクションを提供し、シームレスで直感的な会話を可能にします。
- プログラミング:プログラミングでは、LLMはコード生成、デバッグ、ドキュメント化などのタスクを支援することでワークフローを合理化します。GitHub Copilotのようなツールは、これらのモデルを使用して開発者の時間を節約し、エラーを減らしながら、プログラミングを初心者にとってよりわかりやすいものにします。
- 検索:LLMは、クエリーの意味関係を理解することで検索エンジンを強化し、より正確で関連性の高い結果を提供します。リンクを返すだけでなく、システムが直接的な応答を提供できるようにし、情報取得の速度と効率を向上させます。
- 翻訳:大規模言語モデルにより、言語翻訳が改善され、テキストドキュメントの高品質な変換とリアルタイムのコミュニケーションが実現しました。多言語コンテンツの作成とローカリゼーションをサポートし、企業が世界中のオーディエンスとつながるのを支援します。
- コンテンツの作成:LLMは、記事、マーケティングコピー、クリエイティブな課題レポートを生成することで、コンテンツ作成を変革しています。執筆者がアイデアをブレインストーミングし、魅力的なコンテンツを作成するのを支援し、ジャーナリズムや広告などの分野で生産性を向上させます。
- 学習:LLMは、パーソナライズされた学習体験とAIチューターを可能にします。これらのツールは、複雑なトピックをシンプル化し、カスタマイズされたサポートを提供するため、生徒や教師などの役に立ちます。
大規模言語モデルが業界をどのように変革しているか
LLMは、ほぼすべての業界を変革し、複雑な課題に対するよりスマートで高速、かつ効率的なソリューションを実現しています。
- ヘルスケア:大規模言語モデルは、医療研究を要約し、医師が最新情報を把握するための支援をし、患者に優しいレポートのドラフトを作成することで、ヘルスケアをサポートします。また、患者と医療機関の間のコミュニケーションをより簡単に行えるようにします。
- ファイナンス:金融業界では、LLMがレポート生成、不正検知、財務分析などのプロセスを自動化します。銀行や投資会社向けのインテリジェントなチャットボットを強化することで、カスタマーサービスを強化します。
- 小売およびEコマース:LLMは、顧客を導く仮想ショッピングアシスタントを強化し、レコメンデーションをパーソナライズすることで、小売とEコマースを変革しています。また、製品説明を改善し、オンラインストア体験を最適化します。
- 教育:教育システムはLLMを活用して、採点やレポート生成などのタスクを自動化するとともに、パーソナライズされた学習ツールで学生をサポートします。LLMを活用したAIチューターは、教育をより身近で魅力的なものにします。
- 法務:法律業界では、LLMを使用して契約書の作成、判例法の要約、法的調査を行っています。また、これらのツールは複雑な法的文書をシンプル化し、クライアントにとってより理解しやすいものにします。
- マーケティングと広告:LLMは、マーケティングや広告において、広告コピー、パーソナライズされたEメール、ソーシャルメディアへの投稿を作成するために重要です。オーディエンスデータを分析して、キャンペーンを効果的に調整するのに役立ちます。
- メディアおよびエンターテイメント:メディアおよびエンターテインメント業界では、LLMはスクリプト、歌詞、その他のクリエイティブコンテンツを生成します。また、おすすめのパーソナライズやコンテンツの要約により、視聴者体験を向上させます。
- カスタマーサービス:LLMを活用したチャットボットによってカスタマーサービスが向上し、一般的な問い合わせやトラブルシューティングを効率的に処理できます。これらのツールは、待ち時間を短縮し、人間のようなインタラクションを提供します。
- 旅行&ホテル:LLMは、旅程の計画、予約、カスタマーサポートなどのタスクを合理化します。また、文書や会話を複数の言語に翻訳することで、コミュニケーションを支援します。
大規模言語モデルのメリット
大規模言語モデル(LLM)にはさまざまなメリットがあり、さまざまな分野や業界で非常に価値があります。
- 汎用性:LLMの最大の利点の1つは、幅広いタスクを処理できることです。医学研究や法的文書分析といった分野固有の専門的な用途から、対話型AIなどのより一般的な用途まで、人間の言語の理解と生成が関わるほぼすべての状況に適応できます。たとえば、言語翻訳のサポート、マーケティングコンテンツの作成、プログラミングの支援を最小限のカスタマイズで行うことができます。
- スケーラビリティ:LLMは簡単に拡張できるため、さまざまなプラットフォームに展開し、APIを介して既存のシステムに統合できます。開発者は、GPTやPaLMなどのモデルを使用して、カスタマーサービスのチャットボットから高度な分析ツールまで、さまざまなアプリケーションを強化できます。このようなスケーラビリティを備えているため、LLMはAIシステムをゼロから構築することなく、プロセスの自動化、イノベーション、効率の向上を目指す企業に最適です。
- アクセスのしやすさ:LlamaやBERTなどの多くの大規模言語モデルはオープンソースであり、研究者や開発者はこれらのテクノロジーに無料または低コストでアクセスできます。このオープンな可用性により、ユーザーは大量のリソースを必要とせずにモデルの修正、新しいユースケースの発見、既存の機能の強化を行うことができるため、イノベーションが促進されます。最先端のAIへのアクセスを民主化し、小規模な組織や個人の研究者の競争条件を平準化します。
- 機能の強化:LLMは特に「ゼロショット」学習に適しています。つまり、追加のトレーニングデータを必要とせずに、まったく新しいタスクを処理できます。たとえば、明示的にトレーニングされたことのない方法でテキストを要約することができます。この柔軟性により、新しい問題やニッチな問題向けのAIソリューションの開発に必要な時間と労力が削減されます。
大規模言語モデルの欠点と課題
優れた機能があるにもかかわらず、大規模言語モデルはいくつかの重要な課題に直面しており、責任ある効果的な使用のために対処する必要があります。
- バイアス:LLMは、ステレオタイプ、誤情報、表現の不均衡など、人間のバイアスを含むことが多い膨大なデータセットでトレーニングされています。その結果、モデルは意図せず偏りのある出力や有害な出力を生成する可能性があります。たとえば、トレーニングデータに存在するジェンダーバイアスや人種的バイアスを反映している場合があるため、回答を監視して改善することが不可欠です。
- 大量のリソース消費:GPTのような大規模言語モデルをトレーニングするには、膨大な計算能力、電力、ストレージスペースが必要です。これにより、これらのモデルの開発にコストがかかるだけでなく、そのようなモデルのトレーニングに必要なエネルギー消費が膨大になる可能性があるため、環境への影響も懸念されます。
- 正確性:LLMは優れた結果を出すことができますが、必ずしも正確ではありません。特に、曖昧な質問や微妙な質問が含まれる場合は、「ハルシネーション」して、誤った情報、無意味な情報、または誤解を招くような情報を生成する可能性があります。この欠点があるため、慎重な監視がなければ、法律や医療上のアドバイスなど、リスクの高い用途では信頼性が低下する可能性があります。
- 倫理的な懸念:LLMを含む生成AIの悪用は、倫理的な課題をもたらします。これらのモデルは、有害なコンテンツの作成、誤情報の拡散、プライバシーの侵害に悪用される可能性があります。たとえば、偽のニュース記事や本物のようなフィッシングメールを生成する可能性があるため、このような悪用に対する保護対策を講じることが不可欠です。
よくある質問
自然言語処理(NLP)は、翻訳、要約、感情分析などのタスクを含め、人間の言語を理解して操作することに重点を置いたAIの分野です。大規模言語モデルは、トランスフォーマーなどの高度な技術を活用して、さまざまな言語タスクを高精度かつ流暢に実行するNLPテクノロジーのサブセットです。
LLMは、事実を検証せずにトレーニングデータのパターンに基づいて応答を生成するため、ハルシネーションを起こします。この確率的アプローチは、特に不完全またはあいまいな入力に直面した場合に、妥当に聞こえるが不正確な情報を作成する可能性があることを意味します。
基盤モデルとは、多様なデータセットでトレーニングされた大規模で汎用性の高いAIモデルであり、多くの特定の用途で微調整を行うための基盤として機能します。BERT(Bidirectional Encoder Representations from Transformers)やGPTなどのモデルは基盤モデルの例であり、翻訳や質問への回答などのタスクに合わせてカスタマイズできる幅広い言語理解機能と生成機能を提供します。
GPTはGenerative Pre-trained Transformerの略で、このモデルの主な特徴を表します。その特徴とは、テキストを生成し(Generative)、微調整される前に大規模なデータセットでトレーニングされており(Pre-trained)、言語の処理と理解にトランスフォーマーアーキテクチャを使用することです。
Akamai が選ばれる理由
Akamai は、オンラインビジネスの力となり、守るサイバーセキュリティおよびクラウドコンピューティング企業です。市場をリードするセキュリティソリューション、優れた脅威インテリジェンス、そして世界中の運用チームが、あらゆるところで企業のデータとアプリケーションを多層防御で守ります。Akamai のフルスタック・クラウドコンピューティング・ソリューションは、世界で最も分散されたプラットフォーム上で、パフォーマンスと手頃な価格を両立します。安心してビジネスを展開できる業界トップクラスの信頼性、スケール、専門知識の提供により、Akamai は、あらゆる業界のグローバル企業から信頼を獲得しています。

