
Autoscaling is a cloud computing feature that automatically adjusts the number of computing resources, such as a VM, based on real-time demand. By using predefined policies, autoscaling ensures that workloads are handled efficiently during traffic spikes and that excess resources are terminated during low-usage periods, optimizing performance and cost.
Frequently Asked Questions
In Kubernetes, you can scale a workload depending on the current demand of resources. This allows your cluster to react to resource demand changes more elastically and efficiently. When you scale a workload, you can either increase or decrease the number of replicas managed by the workload, or adjust the resources available to the replicas in place. The first approach is called horizontal scaling, while the second is called vertical scaling. There are manual and automatic ways to scale your workloads, depending on your use case.
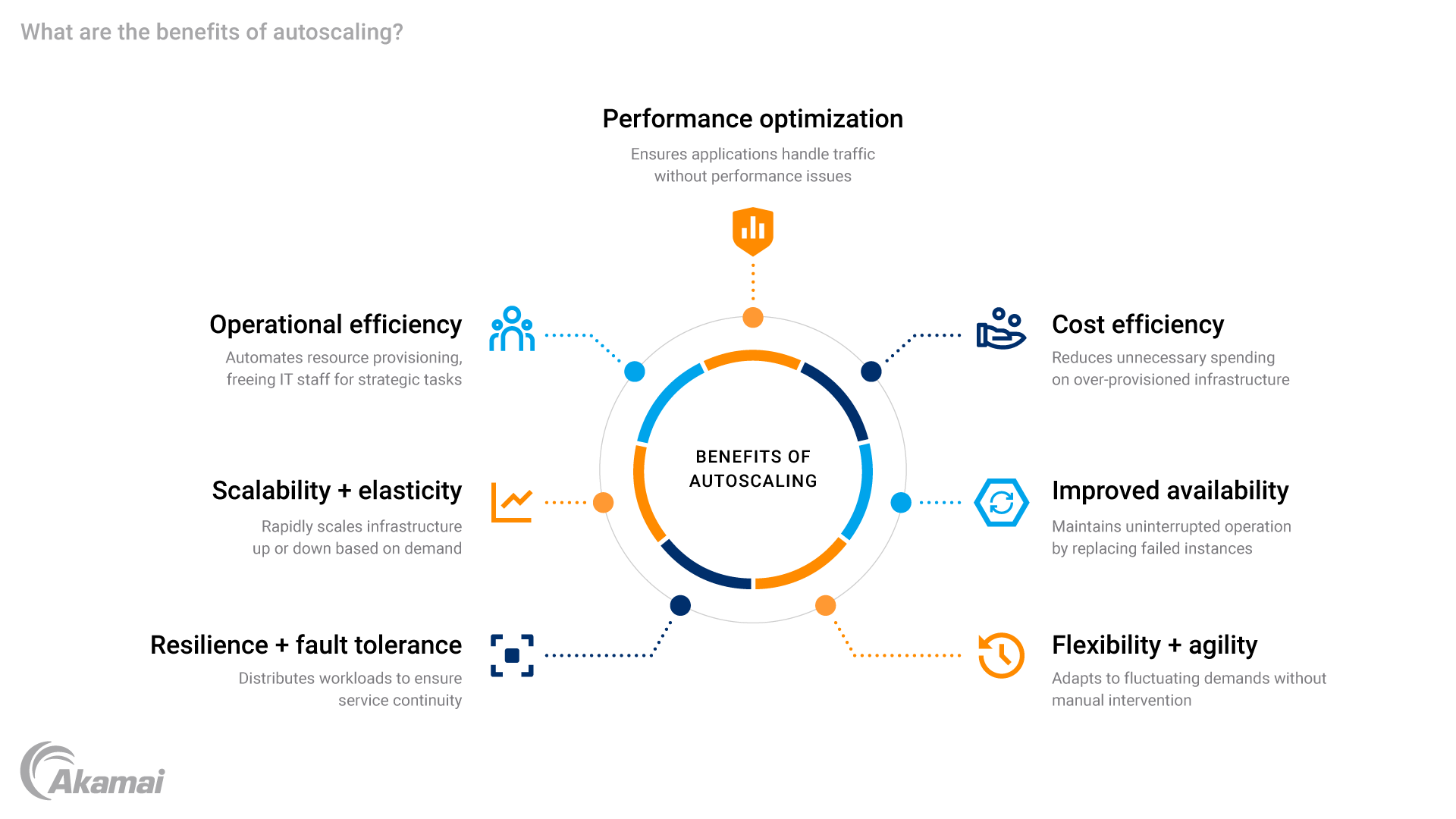
Autoscaling provides numerous benefits, including cost efficiency by only running the necessary resources, performance optimization during traffic surges, improved availability by replacing failed instances, and operational flexibility by automating the scaling process. It reduces the need for manual intervention in handling fluctuating workloads.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.

