

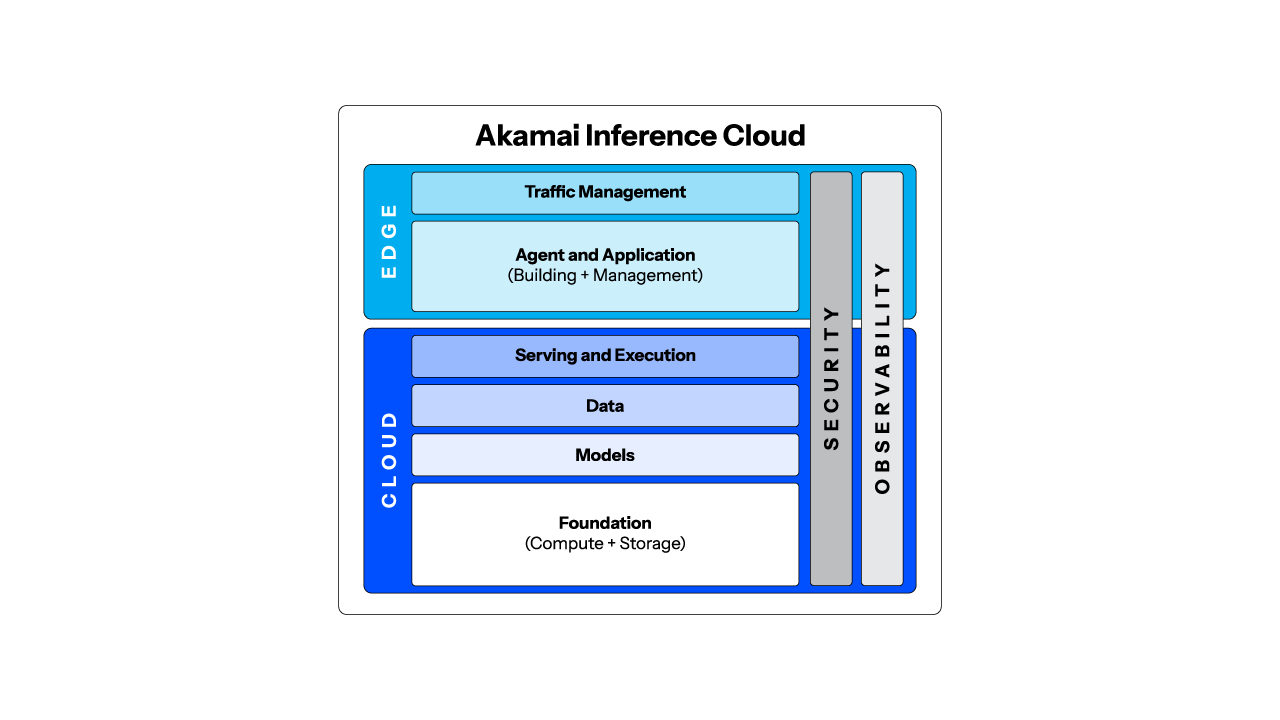
Crea uno stack cloud di AI unificato (basi, modelli, dati ed esecuzione) con la gestione del traffico sull'edge e il controllo del ciclo di vita degli agenti. Le GPU specializzate e la rete sull'edge di Akamai forniscono una bassa latenza per l'inferencing con il supporto della sicurezza adattiva e dell'osservabilità di Akamai, che offrono performance, protezione ed efficienza su scala globale.
L'inferencing è il futuro dell'intelligenza artificiale
L'addestramento insegna l'intelligenza artificiale a pensare, ma l'inferencing la rende operativa perché trasforma i modelli in applicazioni in tempo reale che motivano, rispondono e agiscono. L'inferencing offre le experience necessarie per rendere inestimabile l'intelligenza artificiale.
Le app di intelligenza artificiale sull'Akamai Inference Cloud vengono eseguite più vicino agli utenti, rispondono immediatamente e riescono a scalare senza limiti.
Senza l'inferencing, l'intelligenza artificiale rimane solo un'opportunità
Perché scegliere l'Akamai Inference Cloud?
Akamai offre un cloud solido e distribuito a livello globale progettato per l'era dell'intelligenza artificiale. Il computing basato su GPU si avvicina maggiormente a utenti e dati, accelerando la crescita, rafforzando la competitività e controllando i costi.

Come funziona
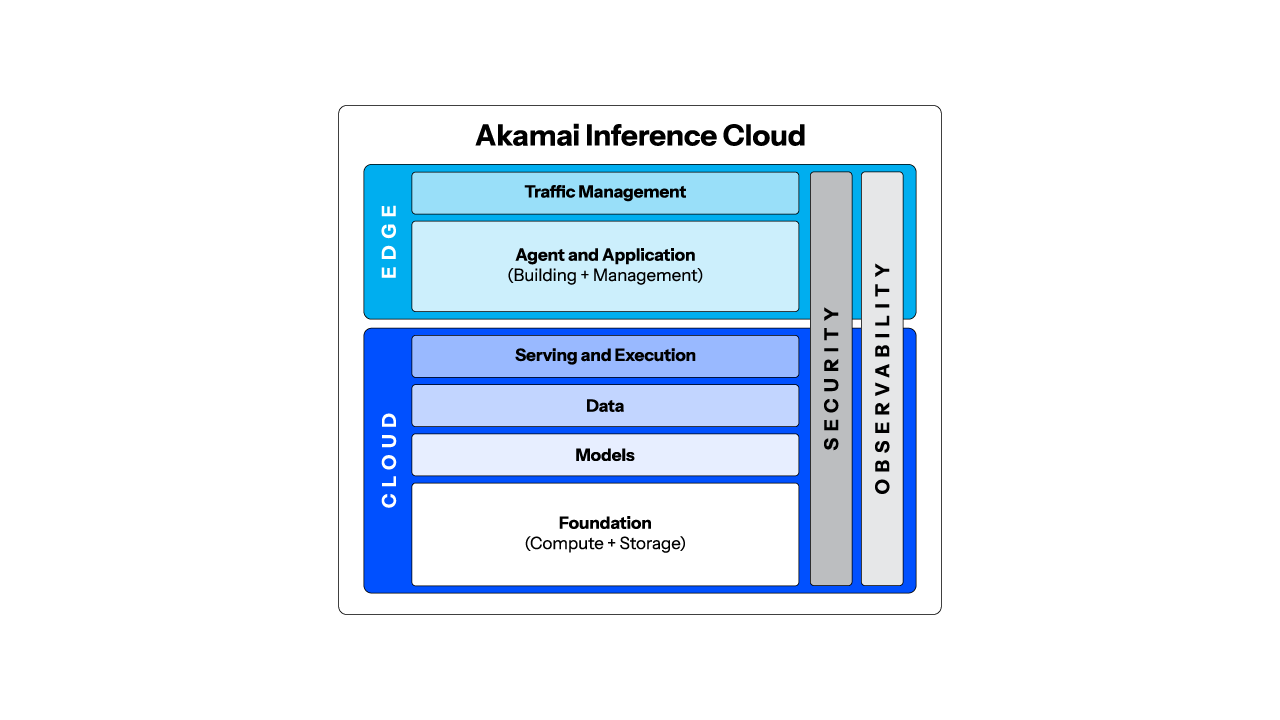
Funzioni
- GPU specializzate
- Sicurezza dell'AI adattiva
- Osservabilità unificata
- Gestione del traffico
- Creazione e gestione di agenti e applicazioni
- Pipeline di dati
- Funzioni senza server
- Dati distribuiti
- Archiviazione a oggetti
Casi di utilizzo
Esegui l'intelligenza artificiale ovunque riesca a creare valore. Risposte più rapide, automazione più intelligente ed experience efficaci in tempo reale in ogni caso di utilizzo.
Domande frequenti (FAQ)
Domande frequenti (FAQ)
L'Akamai Inference Cloud è progettato per le organizzazioni che investono nell'intelligenza artificiale nell'intento di ottenere un vantaggio competitivo, promuovere la trasformazione operativa e prepararsi per il futuro. È progettato per i team che creano e implementano applicazioni basate sull'intelligenza artificiale su vasta scala e che hanno bisogno dell'infrastruttura necessaria per supportare elevate performance in tempo reale in tutto il mondo. Possiamo offrire:
- MLOps: ingegneri che automatizzano l'intero ciclo di vita dell'apprendimento automatico per garantire che i modelli vengano continuamente riaddestrati, implementati e monitorati per garantire elevate performance in fase di produzione
- Ingegneri AI: ingegneri informatici che creano applicazioni agentiche end-to-end, spesso utilizzando modelli preaddestrati, e colmano il divario esistente tra la ricerca sul data science e il software di produzione
- Architetti di sistemi agentici: si tratta dell'evoluzione dell'architetto di sistemi tradizionale che progetta, crea e gestisce complessi sistemi agentici autonomi in grado di motivare, pianificare, agire e adattarsi in modo indipendente per raggiungere obiettivi aziendali di alto livello
L'inferencing avviene più vicino agli utenti, non in un data center distante. La rete sull'edge distribuita a livello globale di Akamai indirizza il traffico verso l'area della GPU più adatta, riducendo la latenza e fornendo risposte più veloci e coerenti per le experience basate sull'intelligenza artificiale.
L'Akamai Inference Cloud porta la produzione dell'intelligenza artificiale sull'edge, decentralizzando dati e funzioni di elaborazione e indirizzando le richieste al modello migliore tramite le posizioni sull'edge distribuite su vasta scala di Akamai. Avvicinando i dati e l'inferencing agli utenti, gli agenti intelligenti dei clienti possono adattarsi istantaneamente agli utenti e all'ottimizzazione delle transazioni in tempo reale.
Akamai offre una difesa a livello di rete, una protezione adattiva dalle minacce e la sicurezza delle API sull'edge con controlli di accesso e sicurezza configurabili per dati e modelli.
È possibile distribuire e monitorare le applicazioni di agentic AI utilizzando la piattaforma per sviluppatori Kubernetes preintegrata di Akamai. Gli ingegneri MLOps possono sfruttare uno stack integrato e preconfigurato di software Kubernetes, tra cui vLLM, KServe, NVIDIA Dynamo, NVIDIA NeMo e NIM NVIDIA.
La piattaforma combina i server NVIDIA RTX PRO, con le GPU NVIDIA RTX PRO 6000 Blackwell Server Edition e il software NVIDIA AI Enterprise, con l'infrastruttura di cloud computing distribuita di Akamai e la rete sull'edge globale, che ha più di 4400 PoP in tutto il mondo.
Parla con il nostro team del tuo caso di utilizzo: potremo aiutarti ad associare i tuoi carichi di lavoro alla GPU e alla configurazione di distribuzione più appropriate, quindi ti assisteremo nella configurazione per consentirti di iniziare ad eseguire rapidamente l'inferencing.
Risorse

Prenota oggi stesso una consulenza sull'intelligenza artificiale
L'intelligenza artificiale sta passando dal laboratorio alla produzione e le aziende sono sempre più sotto pressione per offrire experience più veloci, intelligenti e sicure. Sia per ottimizzare l'inferencing, scalare i modelli o ridurre la latenza, siamo qui per aiutarti a dare vita all'intelligenza artificiale... sull'edge.
- Scopri come distribuire e scalare l'AI inferencing più vicino agli utenti.
- Scopri in che modo l'infrastruttura edge-native migliora le performance.
- Scopri come tagliare i costi, mantenendo, al contempo, una sicurezza di livello aziendale.
Prenota una consulenza sull'intelligenza artificiale per soddisfare le tue specifiche esigenze!