
Akamai が保護対象のウェブサイトへのユーザーリクエストが悪意のあるものかどうかを判断し、検知アルゴリズムを適用するために許される時間はわずか数ミリ秒です。これらの検知は、確率論的な性質を持つ機械学習(ML)モデルとヒューリスティック分析に依存しており、絶えず進化するサイバー攻撃の状況下で運用されています。そのため、偽陰性(FN)や偽陽性(FP)の発生は避けられません。
効果を維持するためには、モデルの評価、チューニング、再学習、検知の精緻化といった、より深い分析をリアルタイムのリクエスト処理パスの外側で実行する必要があります。
従来、リアルタイム処理を補完するこうした分析フェーズはデータサイエンティストが担い、高度に手動化された職人技のようなプロセスを通じてモデルの開発と維持を行っていました。これらのワークフローは多くの場合アドホックで、定義が曖昧であり、非決定的でエラーが発生しやすいものでした。その結果、変更によって新たな、あるいは性質の異なるFNやFPが容易に混入する可能性があり、本番環境で安全に有効化するまでに長期間のモニタリングが必要となっていました。
明確に定義されたテクノロジースタック、統一されたデータアクセス、形式化されたリアルタイム・サポート・プロセスを備えた共通のセキュリティMLOpsプラットフォームを構築したことで、サービス性、信頼性、そして全体的な有効性が大幅に向上しました。
MLOpsプラットフォームの誕生:標準化による基盤構築
メインストリームとなって15年以上が経過した今もなお、機械学習のエコシステムは非常に断片化されています。同様、かつ複雑な目的を達成するために、多種多様なフレームワーク、ライブラリ、ツールが全く異なる方法で使用されています。
幸いなことに、MLアプリケーションの運用ステップは比較的共通しており、十分に理解されています(図1)。
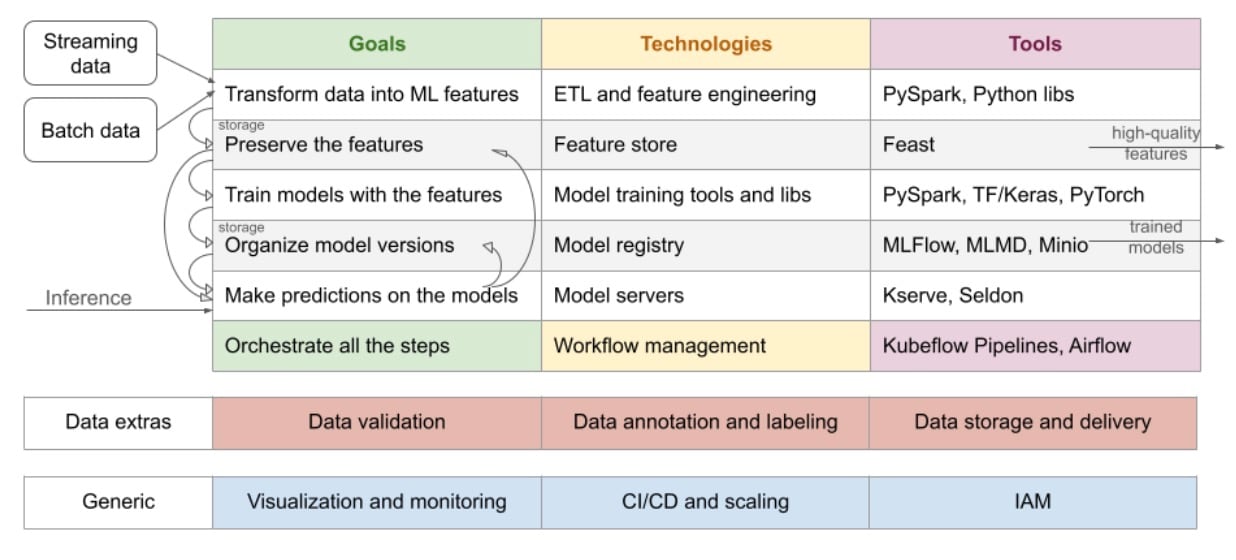 図 1:MLアプリケーションの運用ステップ
図 1:MLアプリケーションの運用ステップ
この共通性により、個々のステップが複数の普及しているテクノロジーをサポートしている場合でも、MLOpsプラットフォームの基盤として一般化および標準化することが可能になります(図2)。
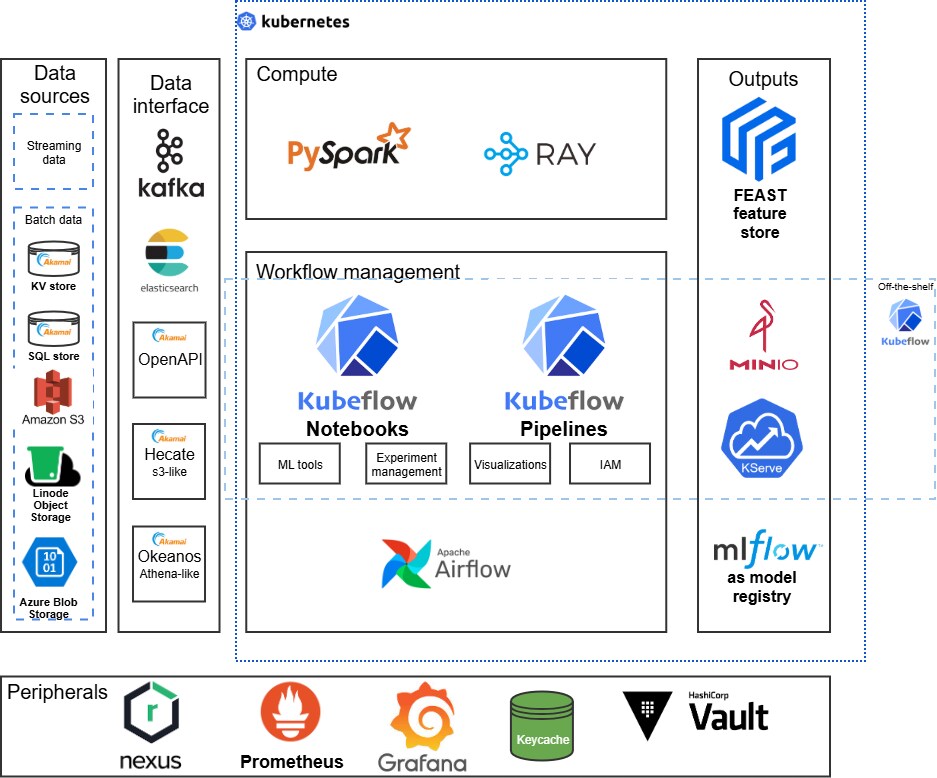 図 2:MLOpsエコシステム
図 2:MLOpsエコシステム
この堅牢で統合されたMLOpsプラットフォームにより、MLソリューションをより迅速かつ信頼性高く、スケーラブルに提供できるようになります。これは、モデルの開発、チューニング、デプロイの間のギャップを埋め、MLアプリケーションのライフサイクル管理を合理化し、再現性を確保し、ガバナンスを強化して、チーム間のコラボレーションを促進します。
プラットフォームの中心となるのは、MLワークフローを実行するためのオープンソースのKubernetesネイティブ・ツールキットであるKubeflowです。Kubeflowは、データの管理、ジョブのトレーニング、ハイパーパラメータのチューニング、モデルサービング、モニタリングのためのエンドツーエンドのインフラスタックを提供します。これらはすべてコンテナ化され、Kubernetes上でオーケストレーションされます。
また、Spark、Kafka、およびネイティブな統合によるコネクターのおかげで、オブジェクトストレージ、データレイク、リレーショナルデータベース、ストリーミングプラットフォームなど、データの所在を問わず、データソースへの統一されたアクセスが保証されます。これにより、データサイエンティストやエンジニアはデータサイロ化を回避し、一貫性のあるバージョン管理されたデータレイヤー上で機能やモデルを構築できます。
さらに、KubernetesのネームスペースとKubeflowプロファイルを使用することで、このプラットフォームは標準でマルチテナンシーをサポートしています。各チームには、独自のリソース、シークレット、パイプライン、ダッシュボードを備えた隔離されたワークスペースが提供されます。これにより、チームをまたいだユーザー管理、アクセス制御、リソース管理が大幅に簡素化されます。
Kubeflowの機能を拡張する主要テクノロジー
Kubeflowの機能をさらに強化するために、以下の主要なテクノロジーを組み込んでいます。
MLflow:モデルのトラッキングとレジストリ
Apache Spark:分散データの前処理と特徴量エンジニアリング
Ray:Pythonベースのスケーラブルな分散トレーニングとハイパーパラメータ最適化
Elasticsearch:インデックス化されたデータストレージと検索分析
HashiCorp Vault:APIキー、認証情報、トークンなどの安全なシークレット管理
Sonatype Nexus:MLモデル、データスナップショット、依存関係のためのアーティファクトリポジトリ
Apache Kafka:リアルタイムのデータ取り込みとモニタリングのためのイベントストリーミング
これらのコンポーネントが組み合わさることで、まとまりのあるエンタープライズグレードのMLOpsプラットフォームが形成されます。各ツールが独自の強みを発揮し、KubeflowがMLライフサイクル全体を統合してスケールさせるオーケストレーション層として機能します。
これらのテクノロジーを統合することで、プラットフォームは以下の価値を提供します。
多様なデータソースへの統一されたアクセスによる、MLワークフロー間の一貫性の確保
安全で協力的なチーム運用のための組み込みのマルチテナンシー
実験から本番環境へのデプロイ、およびモニタリングに至るパスの合理化
この現代的なMLOpsの基盤により、Akamaiはチーム、ユースケース、環境をまたいで、自信を持って効率的に機械学習をスケールさせることができました。AI主導のセキュリティの時代において、堅牢なMLOpsインフラストラクチャは不可欠です。
現場での活用:研究から製品化までの最短距離
MLOpsは、研究、実験、製品化の間の距離を大幅に短縮します。しかし、これらのフェーズは依然として区別されており、それぞれ異なるアクター、目標、要件を持っています。
研究のユースケース
研究者は、緩和策のアイデアを迅速に検証する必要があります。データをローカルで手動で抽出、クレンジング、分析し、カスタムスクリプトで結果を管理する代わりに、研究者は既存のコンポーネントをわずか数行のコードでKubeflow Notebook や Pipeline に組み込むことができます。結果、成果物(Artifacts)、視覚化データ(Visualizations)は、設定可能な保持ポリシーに従って自動的に保存されます。
実験のユースケース
アイデアが有望であることが示されたら、より構造化された環境でテストする必要があります。標準化されたMLOpsセットアップにより、ワークフローのスケジューリング、特徴量や成果物の保存、モデルサービング、およびプラットフォームが提供するMLアドオンとのシームレスな統合が可能になります。これにより、長期にわたって結果を確実に保存し、分析できるようになります。
製品化のユースケース
検証済みのソリューションであっても、本格的な本番ロールアウトの前にさらなる最適化が必要な場合が多くあります。例えば、ワークフローによっては、Kubeflow Pipelinesを介するよりもRayクラスター上で直接実行した方がパフォーマンスが向上することがあります。また、製品化には、カスタムの可視化、外部ツールとの統合、あるいは代替のサービングパターンが必要になる場合がありますが、これらはすべてMLOpsの本番クラスターでサポートされています。
継続的な改善サイクル:ワークフローの視点
インシデント後の対応や検知の精度向上を担う分析プロセスは、主に次の3つのステップに分けられます。
フィードバックの収集:FPおよびFNを検知する
フィードバックの分析:インサイトと攻撃パターンを特定する
インサイトに基づく行動:主要な検知ロジックを調整または拡張する
これらは、汎用化されたMLOpsワークフローの3つのステージに自然にマッピングされます。
トリガー(Trigger)
分析(Analysis)
コントロール(Control)
各ステージは、1つ以上のKubeflow Pipelineコンポーネントを使用して実装でき、最小限のカスタマイズでワークフローへと柔軟に構成できます(図3)。
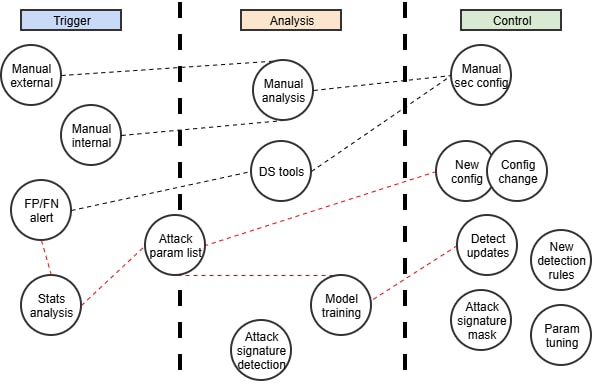 図3:MLOpsワークフロー
図3:MLOpsワークフロー
これらのコンポーネントは、ほとんど、あるいは全く調整することなく、必要なワークフローにグループ化できます。
例1:マニュアルフィードバックループ
Akamai Control Centerで緩和されたトラフィックを確認しているユーザーがFPまたはFNを特定した場合、それが手動の外部トリガーとして機能します。このフィードバックは、MLOpsが制御するインターフェースを介して、ラベル付けされた高品質なground-truth datasetにリアルタイムで送信されます。
その後、データは特徴量に変換され、feature storeに蓄積され、モデルの評価、チューニング、または再学習をトリガーするために使用されます。
最終的に、改良されたモデルバージョンがMLOpsのモデルサーバーにデプロイされ、将来のリクエストに対する推論の精度が向上します(図4)。
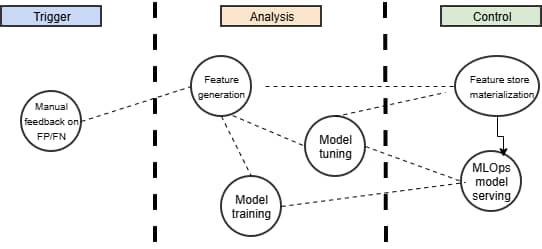 図 4:FP/FNの調整のための手動トリガーワークフロー
図 4:FP/FNの調整のための手動トリガーワークフロー
例2:自動再学習
ユーザー名の送信を伴うエンドポイントなど、一部のエンドポイントでは、高い信頼性でFPおよびFNの検知を自動的に実行できます。この場合、主要な検知レイヤーで使用されているカタパルトモデルの再学習をリアルタイムでトリガーできます。
既存のモデルが最近の攻撃トラフィックに対して評価されます。満足のいくモデルが見つからない場合は、新しいモデルがトレーニングされます。より効果的なモデルが登場すると、自動的に本番環境にデプロイされ、そのアカウントに対する以降のリクエストの推論が向上します(図5)。
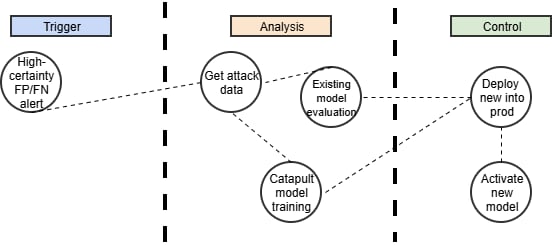 図 5:モデルの再学習とデプロイを伴う完全に自動化されたMLOpsワークフロー
図 5:モデルの再学習とデプロイを伴う完全に自動化されたMLOpsワークフロー
「トリガー、分析、コントロール」というこの3ステップのワークフローアプローチは、幅広いサービス性の課題を解決する上で非常に有効であることが証明されています。これらのソリューションをMLOpsプラットフォーム上でホストすることで、チームは統一されたデータアクセス、検証、ストレージ、可視化、CI/CD、およびアイデンティティアクセス管理(IAM)などの組み込み機能を自動的に享受できます。これらすべてが、MLソリューションの市場投入までの時間を大幅に短縮します。
生成AIの進化:MLOpsから次世代の運用へ
Akamai は、生成AI技術の採用と自社開発を急速に進めています。当社のセキュリティMLOpsプラットフォームにおけるエンジニアの生産性は、社内AIチャットボット「Aether」によってすでに大幅に向上しています。Aetherはプラットフォームのドキュメント、インターフェース、ベストプラクティスを学習しており、いつでも質問に答え、ソリューションを提案してくれます。
当社のセキュリティMLOpsは、大規模言語モデル(LLM)や自律型エージェントを含む、現代のAIシステムの増大する複雑さを管理できるスケーラブルなフレームワークへと進化しています。従来のMLモデルのためのMLOpsとして始まったものは、現在以下のように拡大しています。
LLMOps:生成AIモデルの管理とチューニング
AgentOps:自律型エージェントのデプロイ、テスト、モニタリング、ガバナンス
この拡張は、Akamai 専用の生成AIプラットフォームを補完するものです。
MLOpsは、LLMOpsのコアコンポーネントとして、基盤となるLLMのチューニングと評価をサポートします。
MCP(Model Context Protocol)サーバーの背後に配置されたMLOpsパイプラインにより、AIエージェントは自身の内部能力を超えたツールやデータにアクセスできるようになり、当社のセキュリティAgentOpsの基盤を形成します。
MLOpsのワークフロー管理は、デプロイからモニタリングまで、エージェントのライフサイクル全体を統制します。
MLOpsの上に構築されたLLMOpsとAgentOpsは、MLワークフローをスケールさせ、堅牢なAIエージェントを迅速にデプロイし、本番環境で安全に管理するための基盤を提供します。
未来に向けて
MLOpsからLLMOps、そしてAgentOpsへの移行は、AIの適用方法における大きな広がりを象徴しています。組織がより自律的で強力なモデルを採用するにつれ、この運用フレームワークは予測的なインサイト、対話型エージェント、および自律的な問題解決を大規模に実現することを可能にします。
これらのAI運用の基盤に投資することで、私たちは内部プロセスの最適化、顧客体験の向上、そして持続的なイノベーションを推進することができました。
インテリジェントなセキュリティ運用の未来は、すでに構築され始めています。
詳しくはAkamai の専門家にお問い合わせください
Akamai がAIにどのように投資しているか、またAkamaiのセキュリティソリューションでビジネスを保護する方法についてさらに詳しく知りたい場合は、専門家にお問い合わせください。

Tags


