
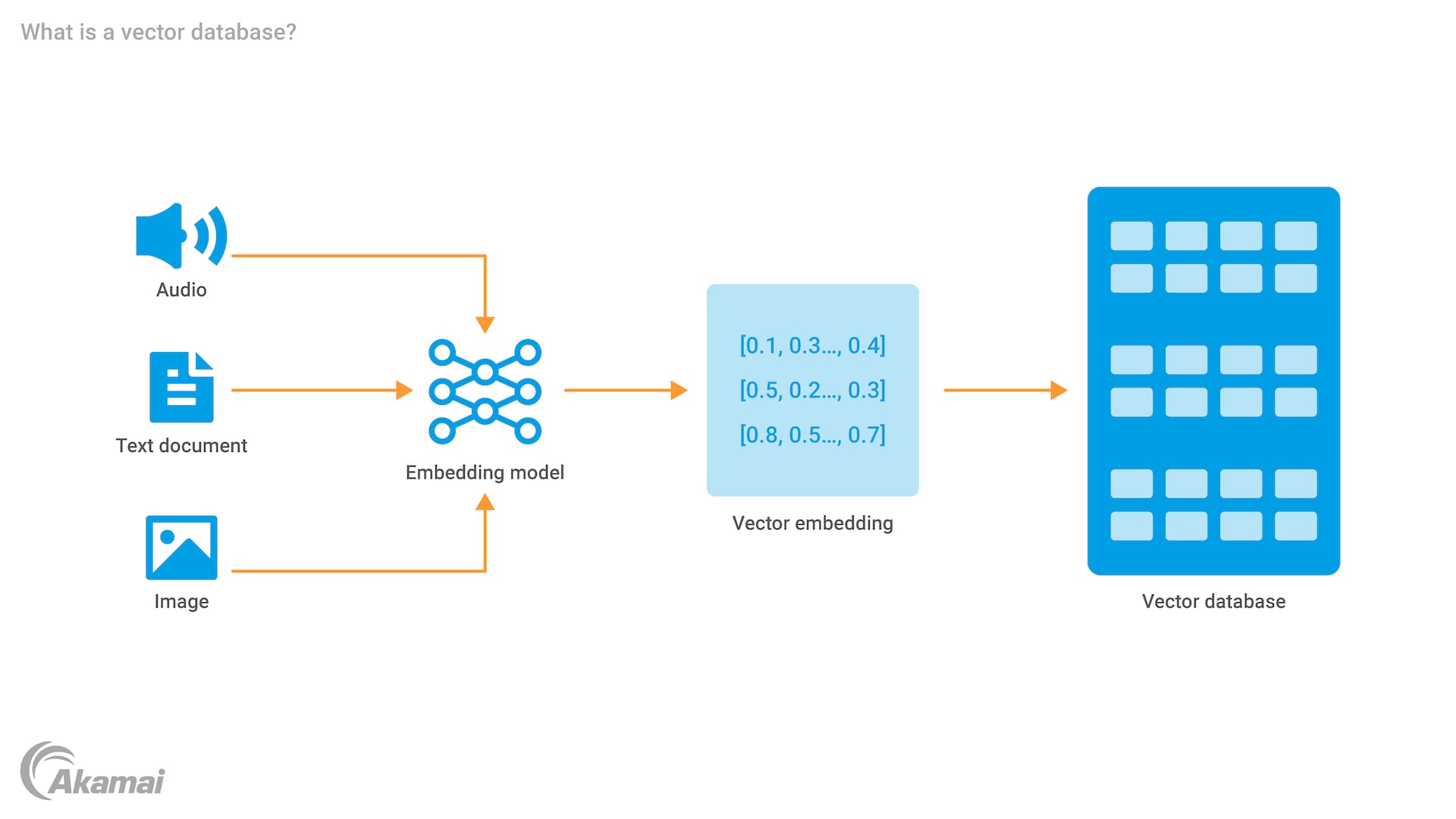
A vector database is a specialized type of database designed to store, manage, and query high-dimensional vectors, which are numerical representations of data such as images, text, or audio. It is optimized for tasks like similarity search, where the goal is to find vectors closest to a given query vector.
In today’s era of artificial intelligence (AI) and machine learning, the demand for efficient tools to manage and analyze complex data has grown exponentially. One such innovation is the vector database, a specialized solution designed to store, manage, and search high-dimensional vector data. This technology is a key enabler for AI applications such as chatbots, recommendation systems, and search engines, offering powerful capabilities for similarity search and large-scale data retrieval. Whether powering generative AI, deep learning and neural networks, natural language processing (NLP), or advanced computer vision tasks, vector databases are reshaping the landscape of data management.
What is a vector?
In AI, a vector is a numerical array or list of numbers that represents an object that can contain various types of data, such as text, an image, or audio, in a form that a machine can understand. Each number in the vector corresponds to a specific feature or attribute of the object. For example:
- In natural language processing, a vector might represent the semantic meaning of a word or sentence. For instance, in large language models (LLMs) such as ChatGPT, sentences are transformed into vectors to facilitate semantic search and context-aware tasks.
- In image recognition, a vector might capture features like color, shape, or texture.
Vectors are used because they allow complex data to be transformed into a mathematical format, making it easier for machine learning models to process, analyze, and find patterns.
What is a vector space?
A vector space is a multidimensional space where each vector represents a point or position. In this space, the dimensions correspond to the features of the data being analyzed. For instance, if you are working with text, the dimensions might represent linguistic characteristics like context or sentiment. There are also distance metrics in vector spaces that facilitate the quick and accurate retrieval of similar data points by assessing the proximity of vectors in a vector space.
Key properties of vector spaces in AI include:
- Similarity measurement: Vectors that are close together in the space are considered similar, making vector spaces essential for similarity search and tasks like semantic search.
- High dimensionality: In AI, vector spaces often have hundreds or thousands of dimensions to capture intricate details of the data.
Vector spaces are foundational in AI because they allow data to be compared, clustered, and retrieved based on relationships encoded in their vector representations.
How is a vector database used?
A vector database is optimized for storing and querying different types of data represented as vectors — numerical arrays that encode information in a vector space. Unlike traditional databases like SQL or relational databases, which are designed for structured data and exact matches, vector databases focus on similarity search — finding similar vectors to a given query vector. This functionality is critical in AI and recommendation systems, where determining “closeness” or “relevance” is more important than exact matches.
How a vector database works
A vector database is designed to simplify the tasks of storing, indexing, and searching high-dimensional vectors that represent data points like text, images, or audio.
Storing vector data
When data like an image or a document is processed by a machine learning model like an embedding model, it is converted into a vector representation. The database stores these vectors alongside relevant metadata, such as labels, IDs, or time stamps. For example:
- An image might be stored as a vector of numerical values capturing its color, texture, and shape.
- A document might be represented as a vector capturing its semantic meaning.
Vector databases are designed to handle increasing data volumes associated with the scalability of AI applications.
Indexing for efficient search
Vector databases create specialized indexes to make similarity search fast and scalable. Common indexing methods include:
Hierarchical navigable small world (HNSW): Builds a graph to quickly navigate through vectors and find nearest neighbors.
Locality-sensitive hashing (LSH): Groups similar vectors into the same buckets for quick lookup.
Approximate nearest neighbor (ANN): Focuses on finding vectors close to the query vector efficiently, trading off slight precision for speed.
Vector database indexes optimize query performance, enabling the database to handle large datasets with billions of vectors.
Performing a vector search with distance metrics
When a query vector is submitted (e.g., from a user query or an AI application), the database searches the vector space to find vectors that are closest to the query. It calculates the similarity using distance metrics like:
- Cosine similarity: Measures the angle between vectors to evaluate their similarity.
- Euclidean distance: Finds the shortest path between two points in the vector space.
- Dot product: Measures the overlap between vectors.
The closest vectors represent the most relevant results, such as similar products in ecommerce or related documents in a semantic search.
Returning results with metadata
The database returns the most similar vectors along with their associated metadata, such as item descriptions, images, or links. Vector databases maintain both a vector index and a metadata index, which are crucial for efficiently retrieving and filtering data. This allows applications to display results or perform further actions based on the search output.
Real-time and scalable queries
Vector databases are designed for real-time queries, enabling fast responses even in large-scale systems. They maintain low latency and high throughput, making them ideal for applications like chatbots, recommendation systems, and image recognition.
Hybrid search vector database capabilities
Some vector databases also support hybrid search, combining traditional keyword or structured data queries with vector similarity searches. This allows complex workflows where both structured and unstructured data are used to find results.
Why vector databases work effectively
- Efficient indexing: Advanced indexing techniques ensure fast vector similarity lookups.
- Scalability: Can handle billions of high-dimensional vectors without significant performance degradation.
- Low latency: Built for real-time applications with quick query responses.
Integration with AI models: Seamlessly integrates with modern AI frameworks and tools via APIs and SDKs.
Vector databases capture semantic relationships between data points, preserving these connections during the embedding process. This makes it possible to perform efficient similarity search across vast datasets, enabling cutting-edge applications in AI, machine learning, and data-driven innovation.
Types of vector databases
Vector databases come in different configurations to suit a variety of needs, ranging from easy-to-deploy managed services to customizable self-hosted solutions. Each type has distinct advantages depending on the scale, use case, and technical requirements.
Cloud-based
Cloud-based vector databases, such as Pinecone, provide fully managed solutions designed for seamless scalability and integration with AI applications.
- These platforms handle the infrastructure, allowing developers to focus solely on building and optimizing their workflows without worrying about server management.
- Cloud-based solutions are ideal for teams looking for rapid deployment, as they offer out-of-the-box compatibility with popular machine learning models, APIs, and SDKs.
- With features like elastic scalability, high availability, and automatic updates, these platforms are perfect for businesses that need reliable and real-time performance at scale.
Open source
Open source vector databases, such as Milvus and Weaviate, provide flexible, community-driven tools that are customizable to specific requirements.
- These databases allow developers to tailor the vector search functionality to their unique needs, making them highly adaptable for diverse use cases like recommendation systems or semantic search.
- Open source tools are cost-effective and encourage innovation, as they are supported by active developer communities that frequently release updates, tutorials, and plug-ins.
- They are particularly appealing to organizations that prioritize transparency and flexibility in their data management workflows.
Self-hosted
Self-hosted vector databases give enterprises complete control over their datasets, infrastructure, and security protocols.
- These databases are deployed on-premises or within private cloud environments, making them ideal for organizations that handle sensitive data, such as in healthcare or finance.
- Self-hosted solutions provide the ability to fine-tune the vector index, algorithms, and storage configurations to optimize for specific metrics or query patterns.
- While more resource-intensive to set up and maintain, self-hosted databases offer unparalleled control, making them a go-to choice for businesses that require customization and data sovereignty.
What are the advantages of using a vector database?
A vector database offers several advantages that make it an indispensable tool for managing high-dimensional vectors and powering modern AI applications. These advantages include enhanced query capabilities, scalability, and seamless integration with cutting-edge tools and models. Additionally, the benefits of vector databases include their suitability for large language models and generative AI applications, effectively managing unstructured data, and optimizing complex data for similarity searches.
Improved query performance
Vector databases are optimized to handle high-dimensional vectors with incredibly fast vector search capabilities.
- Unlike traditional relational databases that struggle with the complexity of similarity searches, vector databases use advanced indexing techniques like HNSW and ANN to deliver precise results in milliseconds.
- This speed makes them ideal for applications like real-time recommendation systems, semantic search, and fraud detection, where quick and accurate responses are critical.
- With the ability to process queries involving millions or even billions of vectors, vector databases ensure smooth user experiences even in large-scale environments.
Enhanced functionality
Vector databases provide the functionality needed to drive advanced AI applications and improve data-driven decision-making.
- They are essential for powering chatbots, enabling them to retrieve contextually relevant responses by performing similarity searches across text embeddings.
- In generative AI, vector databases facilitate efficient retrieval-augmented generation (RAG) workflows by storing and searching through vectorized knowledge bases.
- For search engines, they enable semantic search, which interprets the meaning behind a user’s query instead of relying on simple keyword matching, resulting in more accurate and intuitive search results.
Scalability
Vector databases are designed to handle large datasets without compromising performance, making them highly scalable.
- They can store billions of high-dimensional vectors, distribute data across multiple nodes, and process simultaneous queries efficiently.
- As data grows, the database maintains low latency and high throughput, ensuring consistent performance for AI models and applications.
- This scalability is especially important for industries like ecommerce, where growing product catalogs and user interaction data require robust and scalable solutions for recommendation systems.
Integration
Vector databases integrate seamlessly with AI frameworks, tools, and modern development environments, ensuring smooth adoption and use.
- With support for APIs, SDKs, and programming languages like Python, vector databases make it easy to incorporate vector search into existing applications and workflows.
- They connect effortlessly with embedding models and large language models like GPT, enabling advanced AI applications such as chatbots and image recognition systems.
- Many vector databases also support open source tools and provide compatibility with popular platforms like TensorFlow and PyTorch, ensuring flexibility and ease of use for developers.
Real-world use cases for vector databases
Vector databases have become indispensable across various industries, powering AI applications and solving complex data challenges. By handling high-dimensional vector data efficiently, these databases enable organizations to optimize workflows, enhance user experiences, and unlock insights from massive datasets. Here’s a look at how and where vector databases are being used in the real world.
Ecommerce
In the highly competitive ecommerce industry, vector databases are used to build personalized recommendation systems that analyze customer preferences and browsing histories.
- By using similarity search and comparing product vectors with user preferences stored as embeddings, businesses can suggest items tailored to individual tastes, boosting sales and enhancing customer satisfaction.
- Hybrid search capabilities allow ecommerce platforms to combine structured product information (e.g., price and category) with semantic search for more relevant and intuitive results.
Healthcare
Healthcare providers and researchers rely on vector databases for tasks that require high accuracy and precision.
- Medical imaging: Vector databases store and compare vectors representing features of X-rays, MRIs, and CT scans to detect patterns, anomalies, or similarities in patient data.
- Patient record analysis: By leveraging semantic and similarity search, vector databases help identify relevant medical records or research documents, improving diagnostic workflows and accelerating research.
Finance
In the financial sector, vector databases play a critical role in identifying fraud and other irregularities.
- Fraud detection: They analyze vector embeddings of transactional data to detect suspicious activity or patterns that deviate from the norm.
- Anomaly detection: Vector databases enable real-time monitoring of financial transactions to flag inconsistencies, ensuring enhanced security and compliance.
Technology and AI applications
Tech companies use vector databases to power cutting-edge AI tools and services.
- Chatbots: Vector databases enable chatbots to retrieve contextually relevant responses by performing similarity searches on stored conversation embeddings.
- Generative AI: By integrating with retrieval-augmented generation (RAG) models, vector databases support applications like ChatGPT and other LLMs, ensuring fast and accurate retrieval of contextual information.
- Natural language processing: In NLP applications, vector databases store embeddings of text data to enable semantic search, making it possible to deliver meaningful results based on user intent rather than simple keyword matches.
Search optimization and data insights
Vector databases significantly enhance search engines and data exploration processes.
- Search query optimization: They improve search relevance by analyzing vector embeddings of search queries and matching them with the most relevant data points in a vector space.
- Hybrid search: By combining structured data from relational databases with unstructured vector data, vector databases deliver comprehensive and accurate search results across a wide range of inputs.
- Data augmentation: Efficient similarity search in vector databases enables the creation of additional training data for machine learning models, enhancing their performance and generalization capabilities.
The future of vector databases
As the demand for AI applications grows, vector databases will become increasingly important. Innovations in indexing methods like quantization, support for hybrid search, and low-latency architectures will make vector databases even more powerful. With tools like LangChain and open source platforms, the adoption of vector databases in large-scale AI systems and real-time apps will only expand.
Frequently Asked Questions
Unlike traditional databases that focus on storing and querying structured data like rows and columns, vector databases handle unstructured data represented as vectors. Instead of exact matches, vector databases prioritize similarity searches based on metrics like cosine similarity or Euclidean distance.
Vector embeddings are numerical representations of data generated by machine learning models, such as large language models (LLMs) or image recognition systems. These embeddings capture the data’s key features and are stored in vector databases for tasks like semantic search and data retrieval.
Vector databases offer:
- Improved query performance: Fast and efficient similarity search for large datasets. Algorithms create a data structure that optimizes the search process in vector databases, enabling efficient access to data stored in both vector and metadata indexes.
- Scalability: Handles billions of vectors while maintaining performance.
- Seamless integration: Works with modern AI models, APIs, and SDKs for easy implementation.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.

