
Over the past two years, enterprises have invested billions into generative AI (GenAI), but many are finding that these massive expenditures have failed to yield significant ROI. The industry initially focused on the raw power of foundation models, but there has been a lot of frustration as these models move from isolated pilots to live business environments.
A 2025 MIT report famously found that 95% of artificial intelligence (AI) projects fail to deliver on their promises, as most companies continue to struggle with the day-to-day discipline of operationalizing AI. How can there be such a vast gap between the expectations and reality of AI? Here at Akamai, we had a hunch that the issue was infrastructure — and we set out to prove it.
The Akamai State of AI Inference report
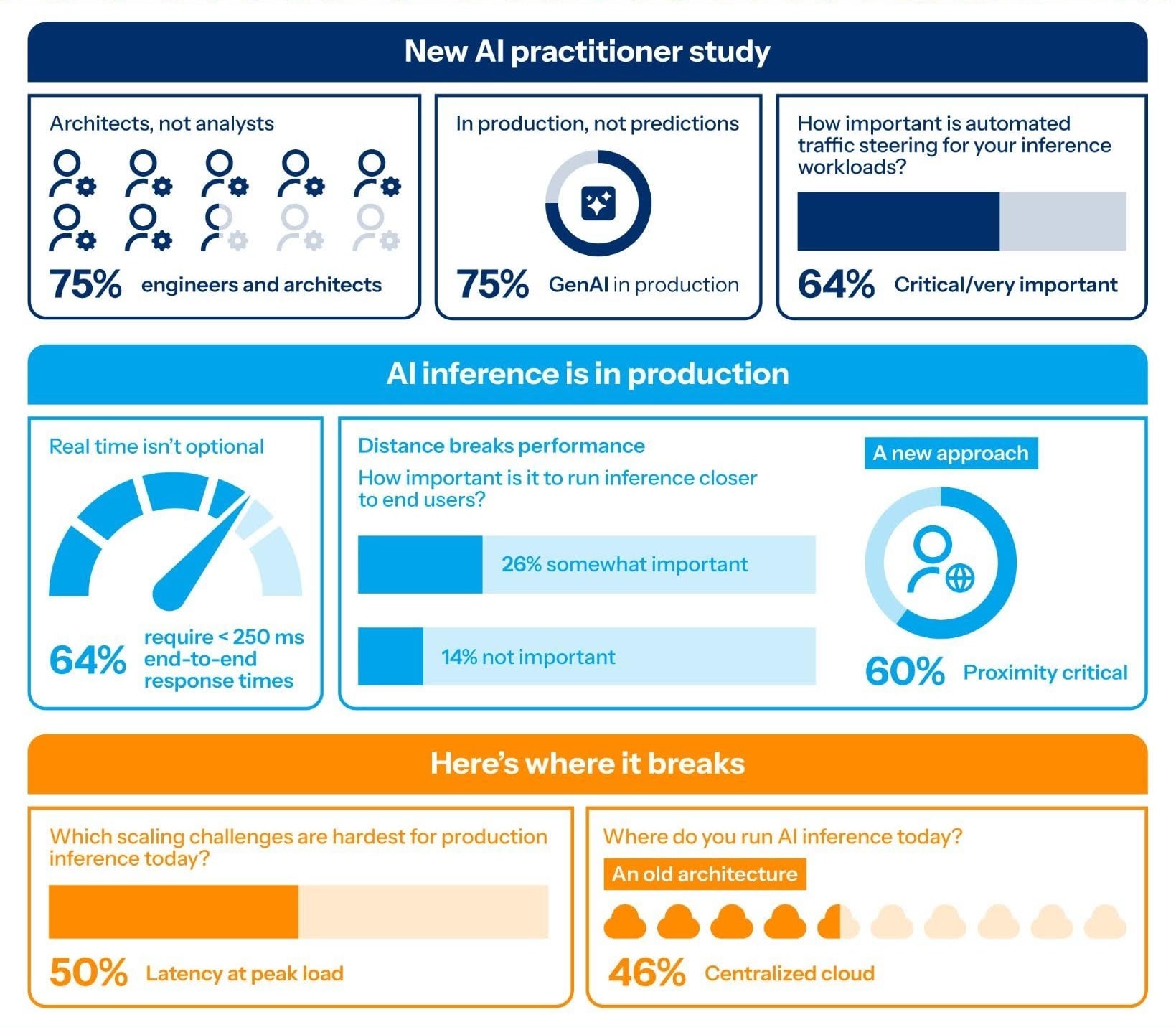
In March 2026, Akamai surveyed 200 AI practitioners to evaluate the operational maturity of modern enterprise AI. This population consisted primarily of engineers and architects, with 75.5% of respondents holding roles such as:
- AI infrastructure systems engineers
- DevOps engineers
- Solutions architects
The cohort was highly senior, with 76% serving as primary or secondary decision-makers for AI deployment. Unlike analyst forecasts that focus on future expectations, this study captured real-world operational insights from practitioners who are actively deploying AI inference in production to provide concrete evidence to support infrastructure and architectural decisions.
The central conclusion of the survey is that AI inference is moving into business-critical use cases faster than enterprise architecture can evolve. Although 75% of organizations have successfully moved GenAI workloads into production, their current infrastructure has failed to keep pace. This has resulted in a "latency wall."
 The AI inference surge
The AI inference surge
The AI honeymoon is over
The enterprise AI honeymoon phase is over. Over the last two years, companies have moved rapidly from experimental chatbots to mission-critical business applications. However, as these applications become embedded in core business workflows, they are colliding with a new physical bottleneck — the limitations of the centralized cloud — that threatens to stall ROI.
The market’s need for speed and ultra-low latency has vastly outrun its current deployment reality. In the early stages of AI experimentation, a slow response from a chatbot was just an inconvenience. Today, customers perceive it is a product defect.
A total of 64% of organizations now require end-to-end response times of less than 250 milliseconds for their most important use cases, yet 50% of deployments are failing to meet these latency demands at peak load; they are hitting the latency wall. This infrastructure-performance gap is a primary barrier to scale that directly impacts revenue per visitor and customer satisfaction.
The architectural mismatch
The root of this problem is an architectural mismatch. While centralized GPU clusters are essential for training models, they are proving too slow, too remote, and too rigid for the inference phase (the actual execution of AI in real-time environments).
In fact, 60% of practitioners acknowledge that running inference in close proximity to the end user is critical to meeting performance standards, but 46% of organizations remain tethered to a single centralized cloud region. This distance introduces unavoidable delays that break the multilevel pipelines modern AI depends on, from retrieval-augmented generation to real-time compliance guardrails.
Operational coping strategies
Because companies cannot re-architect their systems overnight, they are relying on frantic operational work-arounds to close the performance gap. Teams are attempting to compensate through automated traffic steering and rapid rollback capabilities, with 64% citing automated steering as a critical requirement.
These coping strategies, however, have structural limits. The specific limits identified in the survey data include:
- Operational friction: 51% of teams resort to retrying the same model when inference slows down, which often compounds congestion rather than solving it
- Predictability issues: 65.9% of AI-native teams cite GPU capacity planning as their hardest scaling challenge, followed closely by unpredictable compute and token costs
These work-arounds ultimately fail due to immature cost discipline, growing runtime governance risks, and a lack of sufficient compute runway to sustain long-term growth.
How to stop AI ROI and development from stalling
To stop AI ROI and development from stalling, enterprises must stop treating AI as a back-end data center task and start treating it as a distributed production system. The next phase of the AI boom will be defined by those who can successfully distribute intelligence to the edge, not by those who have the most GPUs.
For organizations still hitting the latency wall, the simple conclusion from this research is that your AI strategy is only as viable as the infrastructure it runs on.
Get the details
To get all the details from our survey, download the report.

Tags

