

Tackling DGA Based Malware Detection in DNS Traffic


Earlier this year, Akamai's Enterprise team tackled the problem of DGA detection in the wild by using Neural Networks, essentially creating a state-of-the-art solution for near online detection of DGA communication.
What is a DGA?
DGA stands for "Domain Generation Algorithm." It is a piece of code that at least 46 malware families have, and its goal is to create domain names. These domain names are used for forming a command and control ("C&C") communication channel with the attacker.

The DGA technique is used for evading defense mechanisms that rely on blocking traffic to specific domain names. Imagine you went through the trouble of writing malware, and its command and control server is reached via "botmaster.com;" once a defense system blocks this domain, the malware will no longer function. Therefore, for resiliency, attackers use DGAs to make sure they are able to form the communication channel.
How does a DGA work?
DGAs are pseudo-random generators and are usually seed-based, which generate a random-looking sequence of characters used for forming these domain names. Usually, every day, a new sequence would be generated. These sequences could be anywhere from a few dozen, to a few thousand of domain names, generated at each run. Given this code is known both on the "client-side" (the infected machine) and the "server-side" (the attacker's server), and the secret (seed) is known to both sides, the same exact sequence can be generated on both sides even without them communicating beforehand.
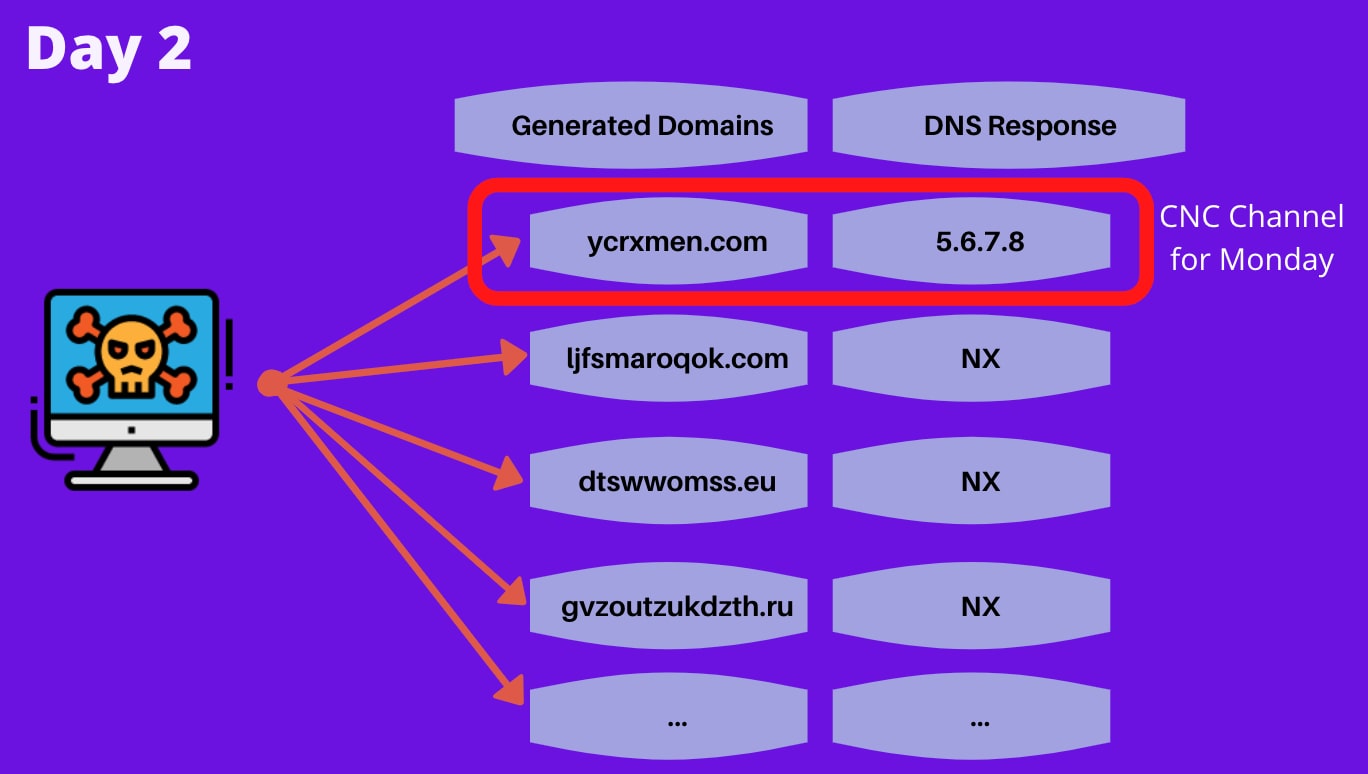
This enables the attacker to know in advance what domain name the malware is going to try and reach out to, which leaves them with the task of registering just one domain out of the sequence, ensuring the communication channel is successfully formed. An illustration of the process is illustrated in figure 2
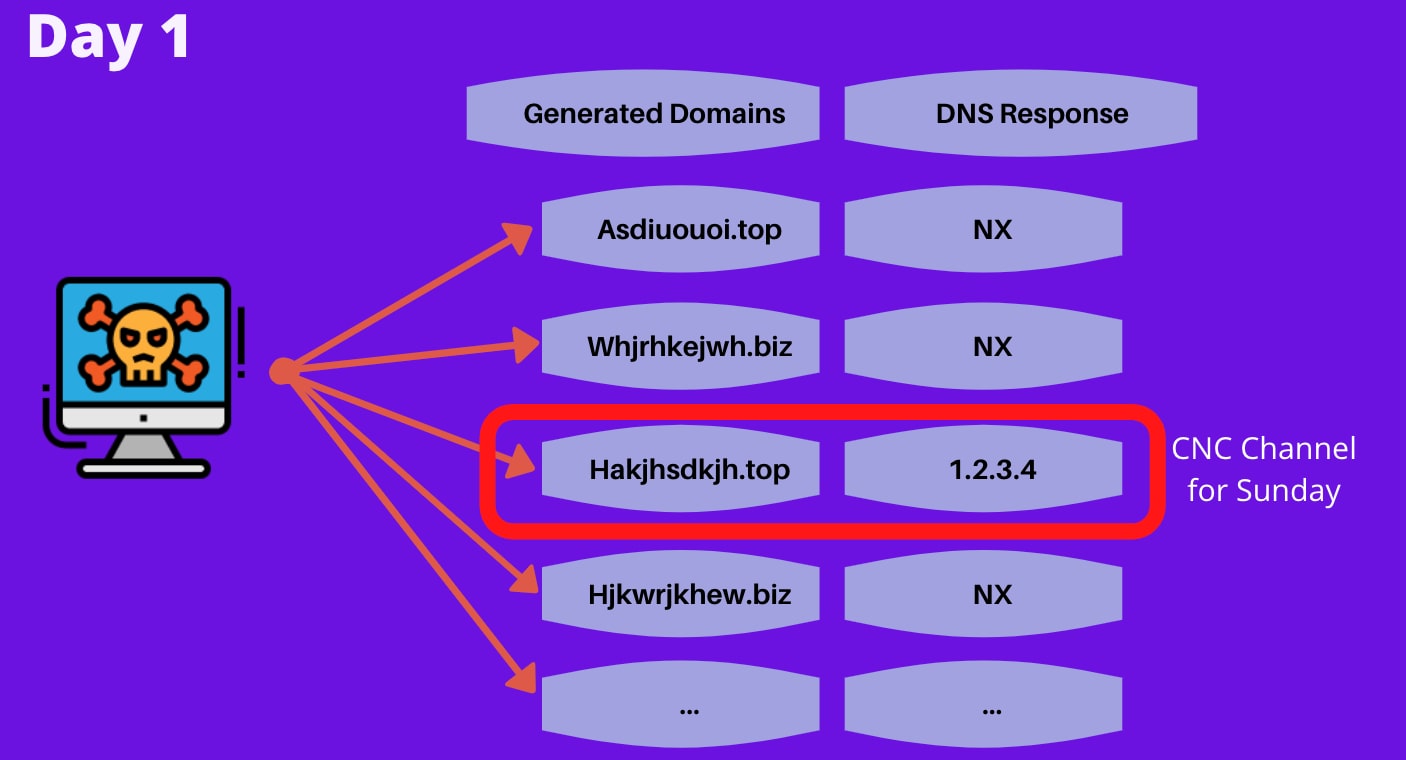 Fig 2: View of querying the DGA names from the "client-side" (the infected machine). One of these domains was registered beforehand by the attacker and will be used to form the communication channel for the day.
Fig 2: View of querying the DGA names from the "client-side" (the infected machine). One of these domains was registered beforehand by the attacker and will be used to form the communication channel for the day.
How did we tackle this problem?
Detecting these domain names in traffic is a problem, one that was researched thoroughly in the defense, and even the academic defense communities. In a previous blog, we've listed the different methods developed over the years to tackle this issue at Akamai. The main point of the previous blogs on this topic, and what we're presenting here, is that there is no "one size fits all" solution. The story of dealing with DGAs is more complicated than it seems. If you're interested in the developments as they've emerged, it's worth looking at the previously linked posts on the topic.
Among those research endeavors, one of the recent breakthroughs is detecting DGAs in traffic without being in possession of the malware sample. We accomplished this by leveraging deep learning neural networks for the task. Specifically, training long short-term memory (LSTM) to distinguish between benign and DGA generated domain names, and using this trained model for providing a score for a single domain as to its probability of being generated by a DGA.
The need for a solution comes from the shortcomings of the complementary method, which includes clustering traffic based on commonality in user traffic. That model has a high noise rate, and therefore a high false positive rate, and requires a massive amount of computational resources.
As advanced as this neural network solution is, applying it to one of the largest DNS traffic datasets in the world revealed a few major shortcomings, such as a high false-positive rate, and the lack of being able to attribute the specific malware generating the domain. Both of these shortcomings are due to the fact that not enough context is being used to determine if the observed domain is generated by a malicious DGA. Such context would be observing the rest of the domains being queried, alongside the single domain being analyzed.
To further understand the rationale behind the inability to classify the specific malware generating the observed domain names, our researchers explored what the neural network "learned." Visualizing this enabled us to develop an intuition about the problem at hand and also guided us towards the solution.
In figure 3, we've illustrated how the LSTM sees the data during classification, to understand why it's incapable of classifying exactly which malware family it originated from. You can see some of the malware families are too similar and effectively intertwine into the same cluster. While it is still distinguishable from the benign cluster, it is impossible to separate the dots. This provided us a great deal of insight into why it's working so well for the binary task, but so poorly for attributing the specific malware family it originated from (this is also called the multiclass classification problem).
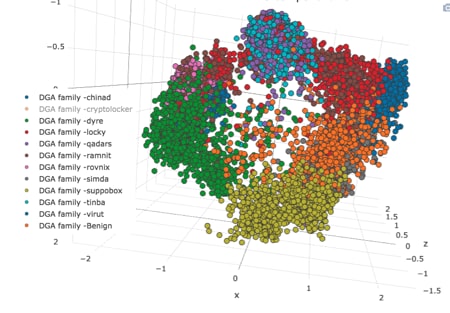 Fig 3: Visualization of the DGA generated domain names, by malware family, as seen in the trained LSTM, one step before it's classification layer.
Fig 3: Visualization of the DGA generated domain names, by malware family, as seen in the trained LSTM, one step before it's classification layer.
The results?
 Fig 4: Results of Akamai's state of the art DGA detection solution in the wild
Fig 4: Results of Akamai's state of the art DGA detection solution in the wild
The DGA landscape is packed with a variety of solutions, each tailored to handling every use case possible. As we continue monitoring the detections made by this system, we keep seeing new and previously undetected DGA-based malicious communication, and we're effectively blocking it for our customers as part of the major portion of global DNS traffic we govern.
One of the unseen botnets this system detected will be described further in an upcoming blog.

