
Inference scaling refers to increasing computational resources during the inference phase to improve performance. This can involve scaling out to serve many users simultaneously, or scaling up the compute devoted to a single query — such as allowing more processing steps or time — to improve accuracy and reasoning on complex tasks.
What Is Inference Scaling?
Inference scaling is the process of serving trained AI models in production so they can generate predictions or insights reliably, with enough capacity, low enough latency, and acceptable cost as traffic grows or fluctuates. This concept is critical for ensuring that AI applications can meet fluctuating demand, maintain low latency, and operate cost-effectively as user bases grow or data volumes increas.
The foundation of inference scaling
The foundation of inference scaling lies in the operationalization of trained machine learning models. Once an AI model has been developed and thoroughly validated, it must be deployed into an environment where it can receive new, unseen data and produce predictions or classifications. This operational phase, often termed model serving or model inference, requires robust infrastructure capable of processing numerous requests concurrently and within specific performance parameters. The fundamental objective is to transform a static, trained model into a dynamic service that can deliver its intelligence on demand, at scale, and with high reliability. This necessitates careful consideration of computational resources, network latency, and software architecture to support sustained performance under varying loads.
Inference scaling vs. model training
It is crucial to distinguish between inference scaling and model training, as they represent distinct phases in the machine learning lifecycle with different computational requirements and objectives.
Model training: This phase involves feeding large datasets to an algorithm to learn patterns and optimize its parameters. Training is typically a computationally intensive process, often requiring specialized hardware such as graphics processing units (GPUs) or tensor processing units (TPUs) for extended periods. The primary goal is to achieve high model accuracy and generalization capabilities. Training is an offline process that occurs prior to deployment and is often performed in batch mode.
Inference scaling: This phase occurs after a model has been trained and deployed. Its purpose is to efficiently serve predictions to end users or other systems based on new input data. The key performance indicators for inference are latency (the time taken to produce a prediction) and throughput (the number of predictions processed per unit of time). Inference scaling focuses on optimizing the delivery of predictions to meet real-time or near–real time operational requirements, emphasizing responsiveness, concurrency, and cost efficiency.
How does inference scaling work?
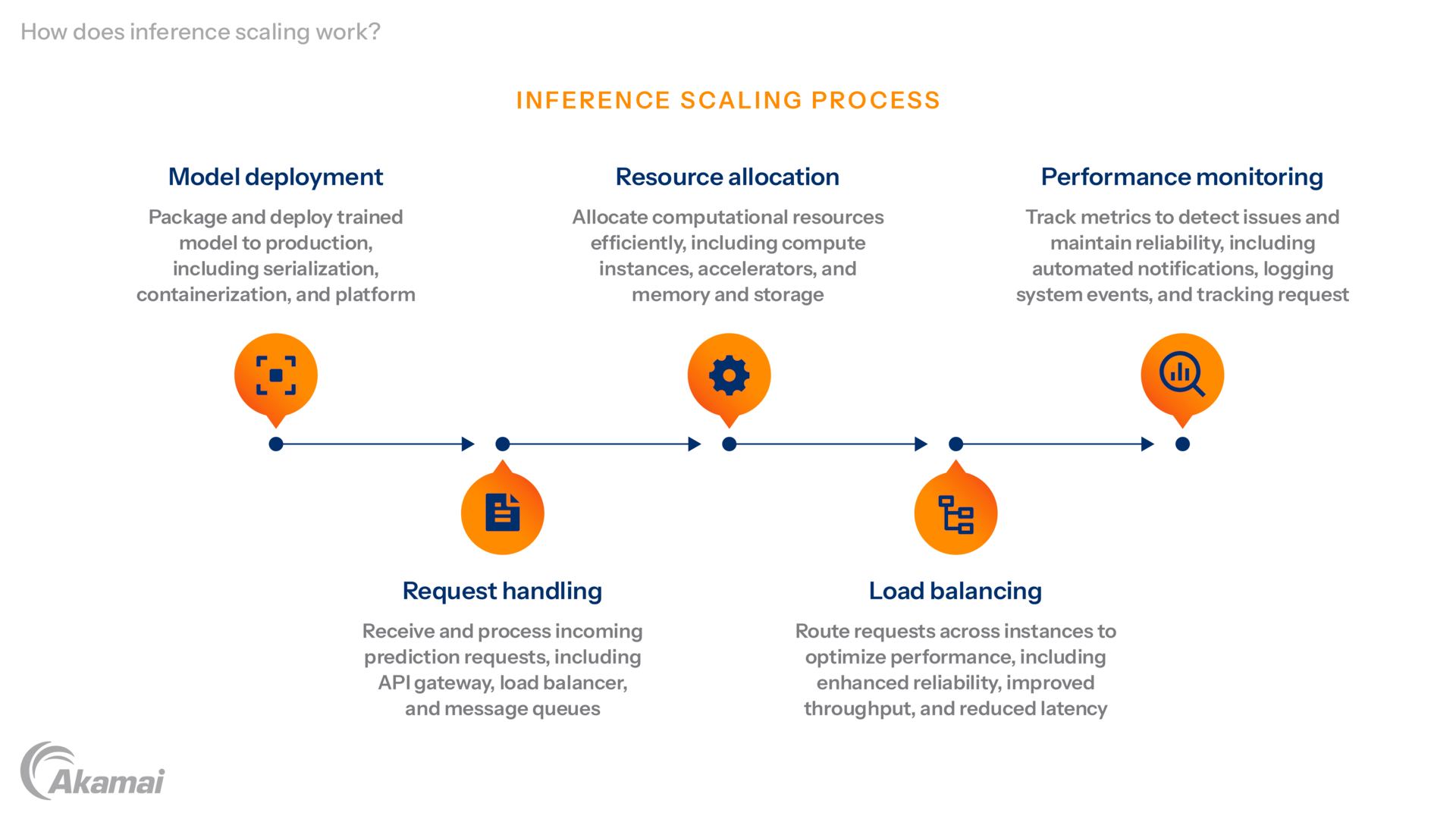 Diagram illustrating how inference scaling works.
Diagram illustrating how inference scaling works.
Inference scaling involves a sophisticated interplay of technological components and strategies to ensure optimal performance. The process can be broken down into several key stages:
Model deployment. The initial step involves packaging and deploying the trained model into a production environment. This typically entails:
Serialization: Converting the model’s structure and learned parameters into a portable format (for example, ONNX, TensorFlow SavedModel, PyTorch JIT).
Containerization: Encapsulating the model along with its dependencies (runtime, libraries) into a lightweight, isolated unit (for example, Docker container). This ensures consistency across different environments.
Deployment platform: Placing these containers onto a suitable infrastructure, which could be cloud-based services (for example, Kubernetes, serverless functions) or on-premises servers.
Request handling. Once deployed, the model service must effectively receive and process incoming prediction requests:
API gateway: Acting as a single entry point for all requests, providing routing, authentication, and rate limiting.
Load balancer: Distributing incoming requests across multiple instances of the model service to prevent any single instance from becoming a bottleneck.
Message queues: Employed for asynchronous processing, especially when requests can be batched or do not require immediate responses, improving system resilience and decoupling components.
Batching and scheduling: Grouping compatible inference requests together can improve accelerator utilization and throughput, especially for GPU-based workloads. For latency-sensitive workloads, batching must be tuned carefully to avoid increasing response times.
Resource allocation. Efficiently allocating computational resources is fundamental to scaling:
Compute instances: Provisioning virtual machines, containers, or serverless functions to host the model. The choice depends on workload characteristics and desired elasticity.
Accelerators: Utilizing specialized hardware like GPUs, TPUs, or FPGAs when models are computationally intensive (for example, large deep learning models) to reduce inference latency.
Memory and storage: Ensuring adequate memory for model loading and intermediate computations, and sufficient storage for model artifacts and logging.
Load balancing. Load balancing is a critical technique for distributing incoming inference requests across multiple operational instances of an AI model. This prevents overload on any single instance, thereby enhancing reliability, improving throughput, and reducing latency. Common strategies include:
Round robin: Distributing requests sequentially to each server in turn.
Least connections: Sending new requests to the server with the fewest active connections.
Weighted least connections: Similar to least connections but factoring in server capacity. Load balancers can be hardware-based appliances or software-based solutions, often integrated into cloud infrastructure services.
Performance monitoring. Continuous monitoring is essential for understanding system health and identifying bottlenecks:
Metrics collection: Gathering data on key performance indicators such as latency, throughput, error rates, CPU/GPU utilization, and memory consumption.
Alerting: Setting up automated notifications for when performance metrics fall outside predefined thresholds.
Logging: Recording all incoming requests, model predictions, and system events for debugging, auditing, and performance analysis.
Traceability: Tracking the full lifecycle of a request across different services to pinpoint performance issues.
Types of inference scaling
Various strategies can be employed to scale AI inference, each suited to different operational requirements and constraints.
Horizontal scaling, also known as “scaling out,” involves adding more machines or instances to distribute the workload. Instead of relying on a single, powerful server, multiple less powerful servers work in parallel to handle requests.
Mechanism: Deploying multiple identical copies of the AI model service across numerous compute nodes (for example, virtual machines, containers).
- Advantages: High availability (failure of one instance does not bring down the entire service), improved fault tolerance, and the ability to scale beyond the capacity of a single machine, subject to quota, networking, data, and accelerator availability constraints.
Disadvantages: Increased operational complexity due to managing multiple instances, potential for data consistency issues in stateful applications (less common for stateless inference).
Typical use cases: Web services, microservices architectures, high-traffic AI applications.
Vertical scaling, also known as “scaling up,” involves increasing the resources (for example, CPU, RAM, GPU) of a single machine or instance.
Mechanism: Upgrading an existing server with more powerful hardware components.
Advantages: Simpler to implement initially, as it involves modifying a single machine.
Disadvantages: Limited by the maximum capacity of a single machine, less fault tolerant (single point of failure), and typically more expensive for equivalent processing power at scale.
Typical use cases: Applications with moderate scaling needs, legacy systems, or when horizontal scaling introduces too much overhead.
Autoscaling is an automated form of scaling that dynamically adjusts the number of instances (horizontal autoscaling) or the resources of existing instances (vertical autoscaling) based on predefined metrics and thresholds.
Mechanism: Utilizing cloud provider services or orchestration tools (for example, Kubernetes Horizontal Pod Autoscaler) that monitor performance metrics (for example, CPU utilization, request queue length) and automatically provision or deprovision resources.
Advantages: Optimal resource utilization (cost-effective), responsiveness to fluctuating demand without manual intervention, and consistent performance.
- Disadvantages: Requires careful configuration of metrics and thresholds to avoid overprovisioning or underprovisioning, potential for “thrashing” if scaling policies are too aggressive.
- Typical use cases: Workloads with unpredictable or highly variable demand, optimizing cloud spending.
Applications of inference scaling
Inference scaling is indispensable across a broad spectrum of AI applications, enabling them to operate effectively in real-world scenarios.
Real-time recommendations
Ecommerce platforms and content streaming services rely on recommendation engines to suggest products, movies, or music to users. Inference scaling ensures that these personalized recommendations are generated instantaneously as users browse or interact with content, directly impacting user engagement and revenue. For example, a new product view might trigger an inference request that identifies similar items or complementary purchases within milliseconds.
Natural language processing (NLP)
Applications such as chatbots, sentiment analysis tools, machine translation services, and advanced search engines leverage NLP models. Inference scaling is crucial for handling the high volume of text input and providing immediate, contextually relevant responses, facilitating seamless communication and information retrieval. A customer service chatbot, for instance, must process thousands of concurrent user queries with minimal delay to maintain efficiency.
Computer vision
Computer vision tasks, including image recognition, object detection, facial recognition, and autonomous driving, often involve processing high-resolution images or video streams. Inference scaling allows these systems to analyze visual data in real time, supporting critical functions like security monitoring, quality control in manufacturing, and navigation for self-driving vehicles. Analyzing frames from a live video feed for anomalies requires substantial, scalable inference capabilities.
Fraud detection
Financial institutions utilize AI models for real-time fraud detection in transactions. Inference scaling enables these models to quickly analyze vast numbers of financial transactions, identifying suspicious patterns and flagging potentially fraudulent activities within seconds, thereby minimizing financial losses. Every credit card swipe or online payment can trigger an inference request that must be processed rapidly to approve or deny the transaction.
Predictive maintenance
In industrial settings, AI models predict equipment failures based on sensor data. Inference scaling ensures that these models can continuously process streams of telemetry data from numerous machines, providing timely alerts for maintenance, preventing costly downtime, and optimizing operational efficiency. Monitoring hundreds of sensors across a factory floor requires an inference system capable of processing continuous data streams to identify subtle deviations indicating impending failure.
Challenges and opportunities in inference scaling
Inference scaling, while critical, presents several challenges alongside numerous opportunities for innovation.
Challenges:
Latency requirements: Many applications demand extremely low latency (for example, sub-100 ms), which can be difficult to achieve, especially for complex models or geographically distributed users.
Cost optimization: Running large-scale inference can be expensive due to continuous compute resource consumption. Optimizing cost without sacrificing performance is a constant challenge.
Model complexity: State-of-the-art AI models, particularly large language models (LLMs) and complex deep neural networks, have massive parameter counts, requiring significant memory and computational power even for a single inference request.
Data locality: Moving large volumes of data to and from inference endpoints can introduce latency and network bandwidth costs, necessitating inference closer to data sources (edge inference).
Resource management: Efficiently managing heterogeneous compute resources (CPUs, GPUs, custom accelerators) across various deployment environments (cloud, on-premises, edge) is complex.
Security and compliance: Ensuring the security of deployed models and sensitive inference data, as well as adhering to regulatory compliance, adds layers of complexity.
Opportunities:
Hardware advancements: Continued innovation in specialized AI accelerators (for example, custom ASICs, next-gen GPUs) offers opportunities for significant performance improvements and energy efficiency.
Model optimization techniques: Techniques like quantization (reducing precision of model weights), pruning (removing redundant connections), and knowledge distillation (training smaller models to mimic larger ones) can drastically reduce model size and inference time without significant accuracy loss.
Serverless inference: The rise of serverless computing platforms offers highly elastic and cost-effective ways to run inference, where users only pay for actual computation time. Serverless inference can be attractive for intermittent or bursty workloads, especially smaller models or event-driven use cases.
Edge AI: Deploying inference capabilities closer to data sources (on edge devices) reduces latency, improves privacy, and conserves bandwidth, creating new application paradigms in IoT, autonomous systems, and manufacturing.
MLOps tools: Maturing MLOps platforms provide comprehensive tools for model deployment, monitoring, and scaling, streamlining the operationalization of AI.
Hybrid cloud and multicloud strategies: Leveraging hybrid and multicloud environments allows organizations to optimize for cost, performance, and regulatory compliance by placing inference workloads where they are most efficient.
The future of inference scaling
The future of inference scaling is poised for transformative advancements driven by evolving AI models, new hardware architectures, and sophisticated deployment paradigms.
One significant trend is the increasing dominance of extremely large models, such as foundation models, which require unprecedented computational resources for inference. This will necessitate innovative strategies for model partitioning and distributed inference, where different parts of a model or different layers are processed across multiple specialized accelerators or even different geographical locations. Quantization and sparsification techniques will become even more critical to make these massive models deployable at scale and within practical latency constraints.
The proliferation of edge AI will continue to expand, pushing inference capabilities closer to data sources like sensors, cameras, and IoT devices. This will minimize latency, enhance privacy, and reduce bandwidth requirements, driving applications in smart cities, autonomous vehicles, and industrial automation. New edge-optimized hardware and specialized inference chips will become more prevalent.
Serverless inference will mature, offering highly elastic and cost-effective solutions for intermittent or bursty AI workloads, abstracting away much of the underlying infrastructure management. This will further democratize access to scalable AI capabilities.
Furthermore, adaptive inference systems that can dynamically adjust their computational complexity based on real-time performance requirements and available resources will become more sophisticated. This could involve dynamically switching between different model versions (for example, a smaller, faster model for urgent predictions and a larger, more accurate one when latency is less critical) or employing cascading inference architectures where simpler models filter requests before more complex models are invoked.
Finally, the convergence of MLOps with advanced infrastructure-as-code practices will streamline the entire lifecycle of AI model deployment and scaling, enabling faster iteration, greater reliability, and more efficient resource utilization across hybrid and multicloud environments. The emphasis will shift toward fully automated, self-healing, and self-optimizing inference systems.
Frequently Asked Questions
Inference scaling is important because it enables AI applications to be reliable, performant, and cost-effective in production environments. Without proper scaling, an AI service might:
Fail to meet user demand: Leading to slow responses or service outages during peak loads.
Incur high operational costs: Due to inefficient resource utilization.
- Deliver poor user experience: With high latency predictions or frequent errors.
- Limit business growth: By preventing the application from expanding its user base or data processing capabilities. Effective scaling ensures that AI models can deliver their intelligence consistently and efficiently to a large number of users or systems, maximizing their real-world impact.
The primary benefits of inference scaling include:
Enhanced performance: By efficiently distributing workloads, scaling reduces latency and increases throughput, allowing AI applications to process more requests quickly.
High availability and reliability: Scaling across multiple instances ensures that the service remains operational even if some components fail, providing fault tolerance.
Cost efficiency: Autoscaling mechanisms optimize resource utilization, provisioning resources only when needed and deprovisioning them during low demand, thereby reducing operational expenditures.
Improved user experience: Fast and consistent responses from AI models lead to greater user satisfaction and engagement.
- Flexibility and elasticity: The ability to dynamically adjust capacity allows AI systems to adapt to unpredictable fluctuations in demand, from sudden spikes to prolonged increases.
- Global reach: Scaling can involve deploying inference endpoints in multiple geographical regions, bringing the AI service closer to users and reducing network latency.
The cloud plays a pivotal role in inference scaling by providing:
Elastic infrastructure: Cloud platforms offer on-demand access to a wide range of compute resources (CPUs, GPUs, TPUs), storage, and networking, which can be rapidly provisioned and deprovisioned. This elasticity is fundamental for autoscaling.
Managed services: Cloud providers offer specialized services for container orchestration (for example, Kubernetes), serverless computing (for example, AWS Lambda, Azure Functions, Google Cloud Functions), load balancing, and API gateways, significantly simplifying the deployment and management of scalable AI inference.
Global footprint: Cloud regions and availability zones enable organizations to deploy inference endpoints geographically closer to their users, minimizing latency and improving regional resilience.
- Cost optimization tools: Cloud-specific billing models (for example, pay-as-you-go, reserved instances) and cost management tools help optimize expenses for varying inference workloads.
- Integrated MLOps platforms: Many cloud providers offer end-to-end MLOps platforms that streamline the entire machine learning lifecycle, from data preparation and model training to deployment, scaling, and monitoring.
Akamai supports inference scaling by leveraging its globally distributed edge network to optimize the delivery and performance of AI inference. By bringing computation closer to the users and data sources, Akamai’s capabilities can:
Reduce latency: Akamai’s edge platform minimizes the physical distance between the inference request and the processing engine, significantly reducing network latency, which is critical for real-time AI applications.
Improve throughput: By offloading certain processing tasks and intelligently routing requests, Akamai can enhance the overall throughput of inference requests.
Enhance reliability and resilience: The distributed nature of Akamai’s network provides inherent redundancy and fault tolerance, ensuring continuous operation even during regional outages or unexpected traffic surges.
Secure inference endpoints: Akamai’s security services can protect inference APIs and models from various cyberthreats, including DDoS attacks and unauthorized access, ensuring the integrity and availability of AI services.
- Optimize data transfer: For applications where input data for inference is large, Akamai can optimize the delivery of this data to the inference engines and the return of predictions to the end users.
- Edge computing for AI: Akamai can support inference scaling by using its distributed edge footprint to reduce network distance, route requests intelligently, protect inference APIs, and place selected compute workloads closer to users or data sources. For latency-sensitive use cases, this can reduce round trips to centralized regions and improve resilience.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.