
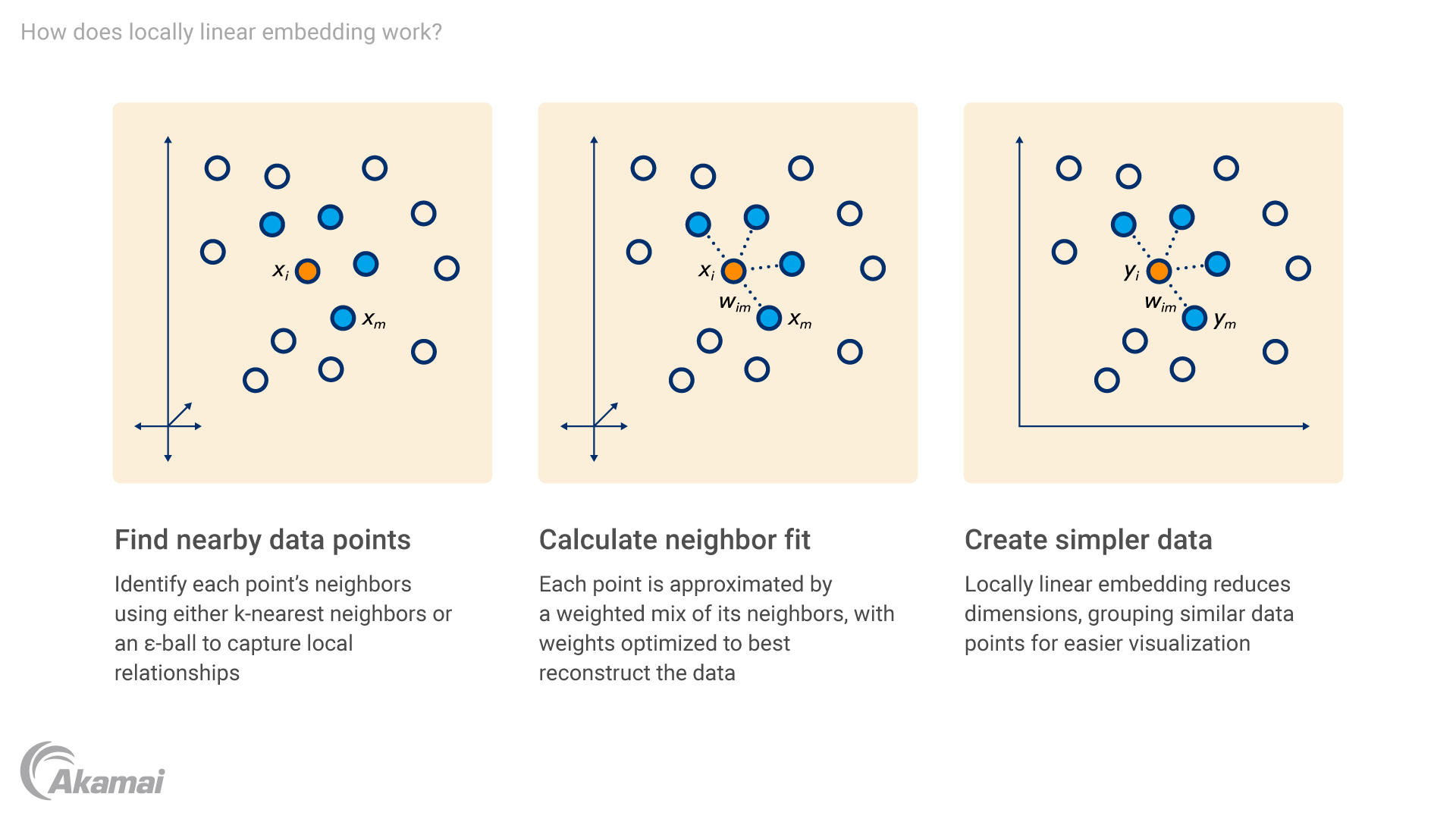
LLE works well with datasets that have complex or curved structures, like images or nonlinear patterns.
Frequently Asked Questions
Yes, LLE can be slow and memory-intensive for large datasets due to its reliance on eigenvalue calculations and iterative optimization processes.
LLE is used in image recognition, text analysis, anomaly detection, and pattern recognition.
LLE is a type of manifold learning that assumes data lies on a low-dimensional manifold embedded in a high-dimensional space.
These are methods or processes used in machine learning to identify patterns or make decisions from data. LLE is an unsupervised machine learning algorithm because it works without labeled data.
Why customers choose Akamai
Akamai is the cybersecurity and cloud computing company that powers and protects business online. Our market-leading security solutions, superior threat intelligence, and global operations team provide defense in depth to safeguard enterprise data and applications everywhere. Akamai’s full-stack cloud computing solutions deliver performance and affordability on the world’s most distributed platform. Global enterprises trust Akamai to provide the industry-leading reliability, scale, and expertise they need to grow their business with confidence.


